Imperva optimizes SQL era from pure language utilizing Amazon Bedrock
It is a visitor publish co-written with Ori Nakar from Imperva.
Imperva Cloud WAF protects a whole lot of hundreds of internet sites in opposition to cyber threats and blocks billions of safety occasions on daily basis. Counters and insights primarily based on safety occasions are calculated day by day and utilized by customers from a number of departments. Hundreds of thousands of counters are added day by day, along with 20 million insights up to date day by day to identify risk patterns.
Our aim was to enhance the consumer expertise of an present software used to discover the counters and insights knowledge. The info is saved in a knowledge lake and retrieved by SQL utilizing Amazon Athena.
As a part of our resolution, we changed a number of search fields with a single free textual content subject. We used a big language mannequin (LLM) with question examples to make the search work utilizing the language utilized by Imperva inner customers (enterprise analysts).
The next determine exhibits a search question that was translated to SQL and run. The outcomes had been later formatted as a chart by the applying. We have now many varieties of insights—world, trade, and buyer stage insights utilized by a number of departments reminiscent of advertising and marketing, assist, and analysis. Information was made out there to our customers via a simplified consumer expertise powered by an LLM.

Determine 1: Insights search by pure language
Amazon Bedrock is a completely managed service that provides a selection of high-performing basis fashions (FMs) from main synthetic intelligence (AI) corporations reminiscent of AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon inside a single API, together with a broad set of capabilities it’s good to construct generative AI functions with safety, privateness, and accountable AI. Amazon Bedrock Studio is a brand new single sign-on (SSO)-enabled internet interface that gives a manner for builders throughout a corporation to experiment with LLMs and different FMs, collaborate on initiatives, and iterate on generative AI functions. It gives a speedy prototyping setting and streamlines entry to a number of FMs and developer instruments in Amazon Bedrock.
Learn extra to study the issue, and the way we obtained high quality outcomes utilizing Amazon Bedrock for our experimentation and deployment.
The issue
Making knowledge accessible to customers via functions has at all times been a problem. Information is generally saved in databases, and may be queried utilizing the most typical question language, SQL. Functions use totally different UI parts to permit customers to filter and question the information. There are functions with tens of various filters and different choices–all created to make the information accessible.
Querying databases via functions can’t be as versatile as operating SQL queries on a recognized schema. Giving extra energy to the consumer comes on account of straightforward consumer expertise (UX). Pure language can remedy this drawback—it’s attainable to assist complicated but readable pure language queries with out SQL information. On schema adjustments, the applying UX and code stay the identical, or with minor adjustments, which saves improvement time and retains the applying consumer interface (UI) secure for the customers.
Developing SQL queries from pure language isn’t a easy process. SQL queries have to be correct each syntactically and logically. Utilizing an LLM with the best examples could make this process easier.

Determine 2: Excessive stage database entry utilizing an LLM circulate
The problem
An LLM can assemble SQL queries primarily based on pure language. The problem is to guarantee high quality. The consumer can enter any textual content, and the applying constructs a question primarily based on it. There isn’t an possibility, like in conventional functions, to cowl all choices and ensure the applying features appropriately. Including an LLM to an software provides one other layer of complexity. The response by the LLM will not be deterministic. Examples despatched to the LLM are primarily based on the database knowledge, which makes it even tougher to regulate the requests despatched to the LLM and guarantee high quality.
The answer: A knowledge science method
In knowledge science, it’s widespread to develop a mannequin and fantastic tune it utilizing experimentation. The thought is to make use of metrics to check experiments throughout improvement. Experiments would possibly differ from one another in some ways, such because the enter despatched to the mannequin, the mannequin kind, and different parameters. The flexibility to check totally different experiments makes it attainable to make progress. It’s attainable to understand how every change contributes to the mannequin.
A take a look at set is a static set of data that features a prediction end result for every report. Operating predictions on the take a look at set data outcomes with the metrics wanted to check experiments. A standard metric is the accuracy, which is the share of the proper outcomes.
In our case the outcomes generated by the LLM are SQL statements. The SQL statements generated by the LLM will not be deterministic and are arduous to measure, nonetheless operating SQL statements on a static take a look at database is deterministic and may be measured. We used a take a look at database and a listing of questions with recognized solutions as a take a look at set. It allowed us to run experiments and fantastic tune our LLM-based software.
Database entry utilizing LLM: Query to reply circulate
Given a query we outlined the next circulate. The query is distributed via a retrieval-augmented era (RAG) course of, which finds related paperwork. Every doc holds an instance query and details about it. The related paperwork are constructed as a immediate and despatched to the LLM, which builds a SQL assertion. This circulate is used each for improvement and software runtime:

Determine 3: Query to reply circulate
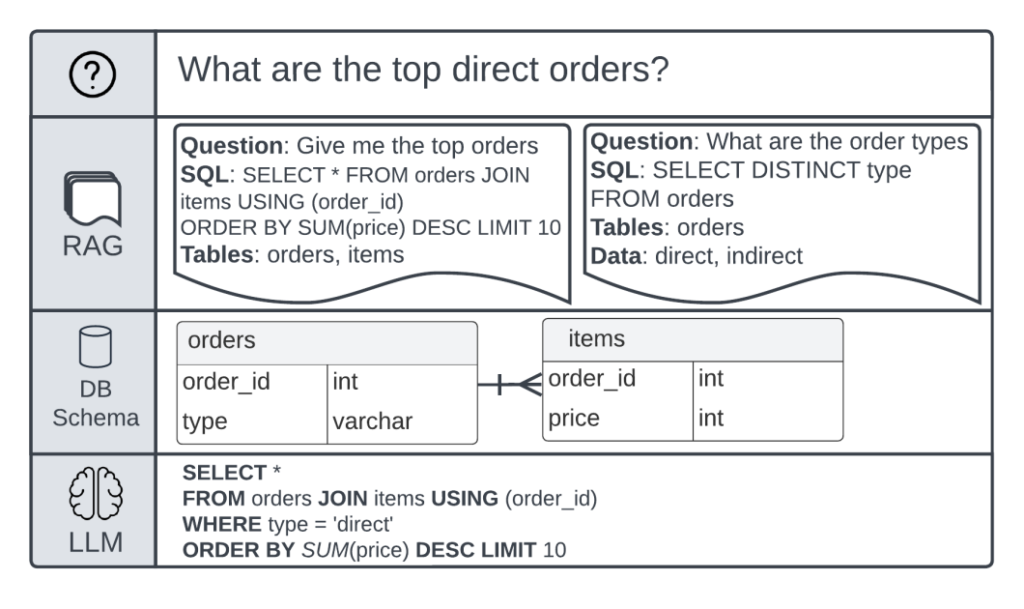
For example, think about a database schema with two tables: orders and gadgets. The next determine is a query to SQL instance circulate:

Determine 4: Query to reply circulate instance
Database entry utilizing LLM: Improvement course of
To develop and fine-tune the applying we created the next knowledge units:
- A static take a look at database: Incorporates the related tables and a pattern copy of the information.
- A take a look at set: Contains questions and take a look at database end result solutions.
- Query to SQL examples: A set with questions and translation to SQL. For some examples returned knowledge is included to permit asking questions concerning the knowledge, and never solely concerning the schema.
Improvement of the applying is finished by including new questions and updating the totally different datasets, as proven within the following determine.

Determine 5: Including a brand new query
Datasets and different parameter updates are tracked as a part of including new questions and fine-tuning of the applying. We used a monitoring instrument to trace details about the experiments reminiscent of:
- Parameters such because the variety of questions, variety of examples, LLM kind, RAG search methodology
- Metrics such because the accuracy and SQL errors fee
- Artifacts reminiscent of a listing of the mistaken outcomes together with generated SQL, knowledge returned, and extra

Determine 6: Experiment circulate
Utilizing a monitoring instrument, we had been in a position to make progress by evaluating experiments. The next determine exhibits the accuracy and error fee metrics for the totally different experiments we did:

Determine 7: Accuracy and error fee over time
When there’s a mistake or an error, a drill all the way down to the false outcomes and the experiment particulars is finished to grasp the supply of the error and repair it.
Experiment and deploy utilizing Amazon Bedrock
Amazon Bedrock is a managed service that provides a selection of high-performing basis fashions. You may experiment with and consider prime FMs on your use case and customise them together with your knowledge.
Through the use of Amazon Bedrock, we had been in a position to change between fashions and embedding choices simply. The next is an instance code utilizing the LangChain python library, which permits utilizing totally different fashions and embeddings:
Conclusion
We used the identical method utilized in knowledge science initiatives to assemble SQL queries from pure language. The answer proven may be utilized to different LLM-based functions, and never just for establishing SQL. For instance, it may be used for API entry, constructing JSON knowledge, and extra. The secret is to create a take a look at set along with measurable outcomes and progress utilizing experimentation.
Amazon Bedrock permits you to use totally different fashions and change between them to seek out the best one on your use case. You may examine totally different fashions, together with small ones for higher efficiency and prices. As a result of Amazon Bedrock is serverless, you don’t must handle any infrastructure. We had been in a position to take a look at a number of fashions shortly, and eventually combine and deploy generative AI capabilities into our software.
You can begin experimenting with pure language to SQL by operating the code samples in this GitHub repository. This workshop is split into modules that every construct on the earlier whereas introducing a brand new method to unravel this drawback. Many of those approaches are primarily based on an present work from the neighborhood and cited accordingly.
Concerning the Authors
 Ori Nakar is a Principal cyber-security researcher, a knowledge engineer, and a knowledge scientist at Imperva Menace Analysis group.
Ori Nakar is a Principal cyber-security researcher, a knowledge engineer, and a knowledge scientist at Imperva Menace Analysis group.
 Eitan Sela is a Generative AI and Machine Studying Specialist Options Architect at AWS. He works with AWS prospects to offer steering and technical help, serving to them construct and function Generative AI and Machine Studying options on AWS. In his spare time, Eitan enjoys jogging and studying the newest machine studying articles.
Eitan Sela is a Generative AI and Machine Studying Specialist Options Architect at AWS. He works with AWS prospects to offer steering and technical help, serving to them construct and function Generative AI and Machine Studying options on AWS. In his spare time, Eitan enjoys jogging and studying the newest machine studying articles.
 Elad Eizner is a Options Architect at Amazon Net Companies. He works with AWS enterprise prospects to assist them architect and construct options within the cloud and reaching their objectives.
Elad Eizner is a Options Architect at Amazon Net Companies. He works with AWS enterprise prospects to assist them architect and construct options within the cloud and reaching their objectives.