Consider generative AI fashions with an Amazon Nova rubric-based LLM decide on Amazon SageMaker AI (Half 2)

Within the put up Evaluating generative AI models with Amazon Nova LLM-as-a-Judge on Amazon SageMaker AI, we launched the Amazon Nova LLM-as-a-judge functionality, which is a specialised analysis mannequin obtainable by means of Amazon SageMaker AI that you should use to systematically measure the relative efficiency of generative AI techniques.
SageMaker AI now affords a rubric-based giant language mannequin (LLM) decide powered by Amazon Nova. As an alternative of utilizing the identical common guidelines for each activity, it mechanically creates particular analysis standards for every particular person immediate. This helps generative AI builders and machine studying (ML) engineers mechanically generate exact, scenario-specific analysis criterion for his or her LLMs and generative AI merchandise, with out manually crafting rule units for each use case.
On this put up, we discover the Amazon Nova rubric-based decide function: what a rubric-based decide is, how the decide is educated, what metrics to contemplate, and find out how to calibrate the decide. We chare pocket book code of the Amazon Nova rubric-based LLM-as-a-judge methodology to guage and examine the outputs of two completely different LLMs utilizing SageMaker coaching jobs.
Overview of Amazon Nova rubric-based decide
A rubric-based LLM decide makes use of a extremely succesful LLM (particularly Amazon Nova) to behave as a decide for responses generated by different AI fashions or human-generated responses. This functionality supplies pairwise comparisons between mannequin iterations, so you may make data-driven selections about mannequin enhancements with confidence. A rubric is a scoring information used to guage efficiency. Historically, to guage an AI mannequin, people manually write a guidelines of guidelines (a static rubric) that apply to each activity. For instance: “Is the reply well mannered?” or “Is the reply brief?” The problem with this strategy is that these common guidelines don’t scale to all customers. A inventive writing immediate wants completely different grading standards than a coding immediate or a authorized abstract moderately than one common guidelines. The Amazon Nova powered decide creates a {custom} guidelines for various interactions. Customers ship a particular immediate to the system (for instance, “Summarize this medical doc for a affected person”). The decide analyzes that particular immediate and decides within the second what an excellent reply ought to seem like. It mechanically writes standards resembling the next:
- Does it use easy, non-medical jargon?
- Does it seize the prognosis precisely?
- Is the tone empathetic?
The decide then appears to be like on the output generated by your LLM mannequin and grades it in opposition to these particular standards it simply created. You get a high quality rating based mostly on guidelines that have been related to that particular activity, not generic guidelines.
Instance enter
For the instance immediate or enter “do dinosaurs actually exist?”, we’ve got two responses as proven within the following desk.
| Response A | Response B |
| The easy reply is: Sure, dinosaurs completely existed, however they don’t exist right now (besides for his or her chicken descendants). Right here’s a breakdown of what which means: 1. Dinosaurs Have been Very Actual For over 150 million years, dinosaurs have been the dominant land animals on Earth. We all know they existed as a result of we’ve got an infinite quantity of proof: Fossils: We’ve got discovered tens of millions of dinosaur fossils—bones, tooth, skulls, and claws—all around the world. These aren’t myths; they’re the precise preserved stays of those animals. Footprints: We’ve got found numerous fossilized trackways, that are footprints left in mud that later turned to stone. These inform us how dinosaurs walked, ran, and lived in teams. Eggs and Nests: Paleontologists have discovered fossilized dinosaur eggs and nests, displaying us how they reproduced. Even Smooth Tissues: In some extraordinarily uncommon instances, scientists have discovered proof of feathers, pores and skin impressions, and even chemical traces of proteins from dinosaurs. 2. However They Are Extinct (Most of Them) About 66 million years in the past, a large asteroid struck the Earth (in what’s now the Gulf of Mexico). This induced a catastrophic occasion that led to the extinction of all non-avian dinosaurs—that’s, all dinosaurs aside from those that might fly. 3. Their Descendants Are All Round Us: Birds! That is probably the most thrilling a part of the reply! Birds are literally a kind of dinosaur. Consider it this fashion: The dinosaur group is big. T. rex, Triceratops, and Brachiosaurus are all well-known members. One other department of the dinosaur household tree have been small, feathered dinosaurs. One group of those feathered dinosaurs advanced the power to fly. They’re the direct ancestors of all fashionable birds. So, once you see a pigeon on the road or a rooster in your plate, you’re looking at a dwelling dinosaur. In abstract:
|
Sure, dinosaurs did actually exist — however not right now. Dinosaurs have been a various group of reptiles that lived on Earth tens of millions of years in the past, primarily throughout the Mesozoic Period, which spanned from about 252 million years in the past to 66 million years in the past. Fossil proof — together with bones, footprints, eggs, and even pores and skin impressions — confirms that dinosaurs as soon as roamed the planet. Scientists have recognized tons of of dinosaur species, starting from the large Tyrannosaurus rex and long-necked Brachiosaurus to smaller, agile predators like Velociraptor. Most non-avian dinosaurs went extinct round 66 million years in the past, probably due to an enormous asteroid influence mixed with volcanic exercise and local weather change. Nevertheless, one group of dinosaurs survived: the ancestors of recent birds. So in a scientific sense, birds live dinosaurs, making them the closest dwelling family members to extinct dinosaurs like T. rex and Triceratops. So whilst you received’t see a Stegosaurus strolling round right now, the legacy of dinosaurs lives on — particularly each time you see a sparrow or eagle fly by. |
Instance output
Out of the 2 responses, the rubric-based decide prefers Response A and likewise supplies a justification of why it prefers response A over response B, as proven within the following screenshot.

The analysis is tailor-made to the precise intent of the person’s immediate (coding vs. writing vs. summarizing). Generative AI builders, information scientists, and ML engineers don’t should spend tons of of hours manually writing analysis guidelines for each doable state of affairs. You’ll be able to consider 1000’s of various kinds of prompts immediately, attaining top quality throughout numerous use instances.
Enterprise implementation examples
The Amazon Nova rubric-based LLM decide addresses vital analysis challenges throughout completely different eventualities:
- Mannequin improvement and checkpoint choice – Growth groups combine the Amazon Nova rubric-based decide analysis into coaching pipelines to mechanically consider checkpoints. Per-criterion scores reveal which capabilities strengthened or regressed throughout iterations, enabling data-driven selections about hyperparameter changes and information curation.
- Coaching information high quality management – Groups use the Amazon Nova rubric-based decide analysis to filter supervised fine-tuning datasets by producing point-wise scores on relevance standards, figuring out low-quality examples. For desire datasets, calculated margins between response pairs allow curriculum studying methods that filter overwhelmingly one-sided examples offering restricted studying alerts.
- Automated deep dive and root trigger evaluation – Organizations deploying generative AI at scale can use the Amazon Nova rubric-based decide analysis for systematic evaluation throughout 1000’s of mannequin outputs with out handbook assessment. When fashions exhibit high quality points, builders can study which particular standards drive desire judgments, figuring out systematic weaknesses that inform focused enhancements as an alternative of broad retraining efforts.
How dynamic rubric era works
The Amazon Nova rubric-based LLM decide takes as enter a triplet: <immediate, response_1, response_2>. The decide compares the standard of the 2 responses for the given immediate and outputs a desire label. Along with the general label, the decide generates a justification for its resolution, guided by a rubric.
A rubric is a set of weighted standards used to guage the 2 responses. The rubric-based LLM decide is educated to generate standards with weights that sum to 1. Every criterion within the rubric has a short_name, description, and weight. The decide’s resolution features a rating for every response on every criterion within the rubric together with justifications for the scores.
The Amazon Nova rubric-based LLM decide employs an analysis methodology the place every judgment is supported by dynamically generated, prompt-specific standards. When the decide receives an analysis request containing a immediate and candidate responses, it analyzes the immediate to know the immediate context, and generates standards based mostly on that context. This dynamic era course of makes certain evaluations are grounded in standards instantly relevant to the duty at hand, offering clear and interpretable assessments.
For every analysis, the decide produces structured YAML output containing the generated standards with their definitions, per-criterion scores on a 1–5 scale, and detailed justifications explaining every rating. The ultimate output contains considered one of 4 desire labels: [[A>B]], [[B>A]], [[A=B]], or [[A=B (bothbad)]. Every criterion rating is accompanied by a justification that grounds the evaluation in observable traits of the responses, enabling deep-dive evaluation and debugging of mannequin habits.
Evaluating rubric-based Amazon Nova LLM-as-a-judge to earlier variations
The rubric-based decide differs from earlier variations in the way it presents analysis outcomes and what data it supplies.
The earlier model of the Amazon Nova LLM-as-a-judge mannequin returned easy desire labels ([[A>B]] or [[B>A]]). The rubric-based model generates a structured YAML output that consists of the next:
- A prompt-specific rubric for assessing the responses organized as a set of standards with related per-criterion significance weights (weights sum as much as 1)
- Transient pure language descriptions of every standards
- Likert score (on 1–5 scale) or binary (true/false) resolution for every criterion for each candidate response within the enter
- Justification for every criterion rating for each candidate response
- General desire judgement: considered one of A>B, B>A, A=B, or A=B (each dangerous)
The brand new detailed output format facilitates a broad vary of nuanced use instances. For instance, particular standards inside rubrics permit for pointed comparisons of responses. A succinct response could be extra appropriate for sure use instances, whereas a complete response could be wanted in others. Justifications and express standards scoring helps customers discard sure standards which might be unsuitable for his or her wants and recompute the desire judgements with out rerunning the question although the LLM decide.
Metrics rationalization
In our decide analysis course of, we use a number of essential metrics to function comparability factors for rating decide high quality. Ahead settlement is a metric which computes settlement with human desire with the chosen response and rejected response in a particular order, which makes certain the right label is at all times considered one of A>B or B>A for your entire dataset. As a result of positional consistency is a vital desired property of a reliable LLM decide, we consider our checkpoints on reconciled settlement—that’s, we get hold of two judgements with responses introduced to the decide in each doable orders (for 2 response desire judgements). We solely credit score the decide with an accurate reply if the decide agrees in each instructions and the judgement matches human desire. This quantity, by definition, will at all times be decrease than ahead settlement. Nevertheless, as a result of real-world datasets aren’t sorted, it supplies a extra correct proxy for the real-world efficiency of an LLM decide mannequin.
Weighted scores (weighted_score_A and weighted_score_B) are new metrics added to the rubric decide analysis output, which offer a view into the arrogance of the judgment. A big distinction between the weighted scores signifies a powerful desire for one response over the over. These scores are calculated per pattern based mostly on the assigned scores for every criterion within the rubric. Every criterion rating is normalized to a 0–1 vary (the place scale scores 1–5 map to 0.0–1.0, and binary True/False map to 1.0/0.0), then multiplied by the criterion’s weight and summed to provide the weighted scores for every response.
The score_margin reveals the distinction between the weighted scores, with unfavorable values indicating a desire in the direction of response B and optimistic values indicating a desire in the direction of response A. Within the remaining analysis output, these metrics are reported as averages throughout all samples. Per-sample standards breakdowns, particular person scores, and justifications could be discovered within the detailed Parquet output file.
Per comparability pattern, we are able to get the precise standards that the brand new rubric decide mannequin used throughout to check the 2 outcomes, which appears to be like like the next instance code:
These weighted metrics are informational and supply quantitative perception into the scoring breakdown, however the precise desire resolution (A>B, B>A, or A=B) that determines the ultimate win counts is predicated on the decide mannequin’s total desire output.
Coaching strategy for the decide
The Amazon Nova rubric-based decide is educated with a multi-aspect reward package deal. In our coaching methodology, we optimize for a number of fascinating traits for an LLM decide utilizing an efficient reward formulation. We primarily goal the next standards:
- Desire accuracy – The decide is rewarded when it produces selections that align with gold human preferences. When it chooses one response over one other, the mannequin is rewarded.
- Positional consistency – The decide’s selections are educated to be resilient in the direction of positional inconsistency points given a particular candidate response order.
- Justification high quality – The decide’s justifications for making the choice should align with the generated rubrics, scores, and remaining judgement.
- Rating calibration – The weighted scores for the responses should be calibrated with the choice accuracy (excessive confidence judgements should be appropriate extra typically than low confidence judgements).
We begin with human annotated desire information and make use of a {custom} information filtering and artificial information era setup to acquire rubric-aligned desire justifications. We pattern from the generated artificial rubrics and developed a {custom} pipeline to coach the Amazon Nova rubric-based LLM decide to proficiently generate acceptable standards with exact granularity for constant and strong decision-making.
Benchmark efficiency
Testing on normal analysis datasets reveals enhancements, notably on duties requiring nuanced judgment, as proven within the following desk.
| Benchmark | Earlier Amazon Nova Choose | New Amazon Nova Rubric-Based mostly Choose |
| PPE | 0.61 | 0.64 |
| RMBench | 0.66 | 0.88 |
| RewardBench | 0.88 | 0.9 |
| JudgeBench | 0.51 | 0.76 |
| CodeUltraFeedback | 0.69 | 0.72 |
| MMEval | 0.8 | 0.84 |
The bigger enhancements on JudgeBench and RMBench replicate higher dealing with of complicated analysis eventualities.
Calibration
Throughout our coaching course of in addition to throughout postprocessing, we consider the Amazon Nova rubric-based decide’s means to make well-calibrated selections. To realize balanced calibration, we take a look at confidence buckets on a human annotated desire dataset. We take a look at the distinction of weighted scores for response pairs. We intention for calibration of confidence to accuracy. Ideally, the LLM decide ought to be extra correct when making excessive confidence selections and is allowed to be much less correct when making low confidence selections. We discover that this calibration methodology leads to constant decision-making out and in of distribution datasets. We additionally take a look at the distributions of scores generated for various standards. We search for an roughly regular distribution over Likert scale scores (1–5) over the eval dataset. This two-pronged calibration checking course of helps us determine higher LLM decide checkpoints amongst a number of equally well-performing checkpoints.
Use instances of rubric-based judgement
The reliability of dynamically generated rubrics stems from three selections:
- The decide is educated on numerous, high-quality rubric-annotated desire information representing real-world use instances, educating it patterns that distinguish efficient analysis standards from superficial ones.
- Our filtering mechanism throughout coaching prioritizes rubrics exhibiting fascinating properties—comprehensiveness, mutual exclusivity, acceptable specificity, and activity relevance—ensuring the mannequin learns from the very best examples.
- Our reward formulation instantly incentivizes rubric high quality: standards that result in correct, position-invariant preferences with well-calibrated confidence receiving optimistic rewards, whereas these producing inconsistent judgments are penalized.
use rubrics to enhance sensible functions
Many fashionable functions function in reference-free environments, the place no gold-standard human solutions exist. In these instances, the usefulness of the rubric is paramount. On this part, we highlight cases the place rubrics generated by our decide may very well be helpful inputs for knowledgeable decision-making. We show how outputs of our rubric-based decide—particularly the weighted standards, granular scores, and express justifications—function vital management mechanisms.
Evaluating RAG techniques
In Retrieval Augmented Technology (RAG), the first failure mode is hallucinations. Conventional desire judges usually conflate “is the response good?” with “is that this fluent?”, “is that this well-formatted?”, “does the interior logic maintain up?”, and so forth. A fluent however factually incorrect response is commonly perceived as extra credible than a disjointed one containing correct data. A factuality-focused analysis may also help you select a summarization mannequin as a result of the retrieval outcomes don’t have hallucinations. Utilizing a rubric-based decide for such judgements may assist in understanding whether or not desire judgement is predicated on standards like fluency and formatting, or if the judgement is predicated on related standards resembling faithfulness, context relevance, and so forth. Customers can disregard the scores of irrelevant standards and re-valuate judgements based mostly on a subset of standards they care about for his or her utility.
The inventive critic
On this instance, we glance within the different path, the place creativity and originality are fascinating over faithfulness to real-world info or earlier context. Take into account a use case the place you’re utilizing an LLM to generate brief tales or scripts which might be authentic, however the person supplies a couple of examples of previous scripts to show the necessities. Deciding on good outputs from these generations require the generated tales to be sufficiently completely different from the examples, inventive, authentic, and never borrow instantly from present coaching information. The tip-user may index on standards resembling originality, coherence, and engagement to optimize for desire judgements suited to this use case, when utilizing our rubric-based decide. You could possibly additional take a look at the specific justifications for standards scores for the precise kind of originality and creativity that’s fascinating.
Answer overview
This resolution demonstrates find out how to consider generative AI fashions on SageMaker AI utilizing a rubric-based decide functionality. You may as well consider human generated responses, however on this resolution, we present how one can consider responses generated by different LLMs resembling Qwen fashions utilizing Amazon Nova as a rubric-based decide.
First, we put together a dataset by sampling questions from the Stanford Query Answering Dataset (SQuAD) and producing candidate responses from each Qwen2.5 1.5B Instruct and Qwen2.5 7B Instruct. Each fashions are accessed by means of SageMaker hosted Hugging Face endpoints. The responses from each fashions are saved in a JSONL file (llm_judge.jsonl) containing the immediate, response_A (from Qwen2.5 1.5B Instruct), and response_B (from Qwen2.5 7B Instruct).
Subsequent, the JSONL file is uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. A PyTorch Estimator then launches an analysis job utilizing the Amazon Nova rubric-based LLM-as-a-judge recipe. The decide mannequin dynamically generates analysis rubrics and standards tailor-made to every activity, then compares the 2 candidate responses in opposition to these standards. The job runs on GPU cases resembling ml.g5.12xlarge and produces analysis metrics, together with per-criterion scores, justifications, comparative assessments, desire counts, and confidence measures. Outcomes are saved to Amazon S3 for evaluation.
Lastly, a visualization perform renders charts and tables, summarizing the generated rubrics, rating distributions throughout analysis dimensions, comparative efficiency between the 2 Qwen2.5 fashions, and detailed examples with justifications. Via this end-to-end strategy, you may assess which mannequin performs higher, determine particular strengths and weaknesses, monitor enhancements, and make data-driven selections about deploying generative fashions—all with out handbook annotation.
Stipulations
You should full the next conditions earlier than you may run the pocket book:
- Make the next quota enhance requests for SageMaker AI. For this use case, you have to request (on the Service Quotas console) a minimal of two g5.12xlarge cases for endpoint utilization and not less than one g5.12xlarge occasion for coaching job utilization.
- (Non-compulsory) You’ll be able to create an Amazon SageMaker Studio area (confer with Use quick setup for Amazon SageMaker AI) to entry Jupyter notebooks with the previous IAM position. (You need to use JupyterLab in your native setup, too.)
- Create an AWS Identity and Access Management (IAM) role with managed insurance policies
AmazonSageMakerFullAccess,AmazonS3FullAccess, andAmazonBedrockFullAccessto provide required entry to SageMaker AI and Amazon Bedrock to run the examples. - Earlier than continuing, make sure that to grant the execution position direct
s3:PutObjectpermissions on your S3 bucket prefix as an inline coverage:
- Create an AWS Identity and Access Management (IAM) role with managed insurance policies
- Clone the GitHub repository with the belongings for this deployment. This repository consists of a pocket book that references coaching belongings.
- Run the pocket book
Amazon-Nova-Rubric-LLM-as-a-Judge-Sagemaker-AI.ipynbto start out utilizing the Amazon Nova LLM-as-a-judge implementation on SageMaker AI.
Configure fashions
To conduct a rubric-based Amazon Nova LLM-as-a-judge analysis, you have to generate outputs from each candidate fashions you wish to examine. On this mission, we deploy Qwen2.5 1.5B Instruct and Qwen2.5 7B Instruct on SageMaker to generate responses that will probably be in contrast by the Amazon Nova decide mannequin.
Each fashions are open-weight multilingual language fashions deployed on devoted SageMaker endpoints. That is achieved through the use of the HuggingFaceModel deployment interface. To deploy the Qwen2.5 1.5B Instruct and Qwen2.5 7B Instruct fashions, we offer a handy script that accepts the mannequin identify as an argument:
We’ve got additionally included the power to check each of those deployed fashions. When you might have deployed the fashions, you may transfer on to creating the analysis information for the rubric-based Amazon Nova LLM-as-a-judge.
Put together dataset
To create a practical analysis dataset for evaluating the Qwen fashions, we used SQuAD, a extensively adopted benchmark in pure language understanding distributed beneath the CC BY-SA 4.0 license. SQuAD consists of 1000’s of crowd-sourced question-answer pairs protecting a various vary of Wikipedia articles. By sampling from this dataset, we made certain that our analysis prompts mirrored high-quality, factual question-answering duties consultant of real-world functions.
We started by loading a small subset of examples to maintain the workflow quick and reproducible. Particularly, we used the Hugging Face datasets library to obtain and cargo the primary 20 examples from the SQuAD coaching break up:
This command retrieves a slice of the complete dataset, containing 20 entries with structured fields together with context, query, and solutions. To confirm the contents and examine an instance, we printed out a pattern query and its floor fact reply:
For the analysis set, we chosen the primary six questions from this subset:questions = [squad[i]["question"] for i in vary(6)]
Generate analysis dataset
After getting ready a set of analysis questions from SQuAD, we generated outputs from each Qwen2.5 fashions and assembled them right into a structured dataset for use by the Amazon Nova rubric-based LLM-as-a-judge workflow. This dataset serves because the core enter for SageMaker AI analysis recipes.To do that, we iterated over every query immediate and invoked the era perform for each SageMaker endpoints:
generate_response("qwen25-15b-instruct-endpoint", q)for completions from the Qwen2.5 1.5B Instruct mannequingenerate_response("qwen25-7b-instruct-endpoint", q)for completions from the Qwen2.5 7B Instruct mannequin
For every immediate, the workflow tried to generate a response from every mannequin.The next code calls two completely different variations of the Qwen 2.5 mannequin. This permits the LLM decide to later decide if the bigger mannequin supplies considerably higher accuracy or if the smaller mannequin is adequate for the duty.
This workflow produced a JSON Traces file named llm_judge.jsonl. Every line comprises a single analysis document structured as follows:
Then, we uploaded the llm_judge.jsonl to an S3 bucket:
Launch Amazon Nova rubric-based LLM-as-a-judge analysis job
After getting ready the dataset and creating the analysis recipe, the ultimate step is to launch the SageMaker coaching job that performs the Amazon Nova rubric-based LLM-as-a-judge analysis. On this workflow, the coaching job acts as a totally managed, self-contained course of that masses the decide mannequin, processes the comparability dataset, applies dynamically generated rubrics, and generates complete analysis metrics in your designated Amazon S3 location. We use the PyTorch estimator class from the SageMaker Python SDK to encapsulate the configuration for the analysis run. The estimator defines the compute sources, container picture, analysis recipe, and output paths for storing outcomes:
After the estimator is configured, you provoke the analysis job utilizing the match() technique. This name submits the job to the SageMaker management airplane, provisions the compute cluster (ml.g5.12xlarge cases), and begins processing your analysis dataset:
estimator.match(inputs={"prepare": evalInput})The job will execute the rubric-based comparability, with the Amazon Nova decide mannequin dynamically producing analysis standards and scoring each Qwen2.5 mannequin outputs. Outcomes, together with per-criterion scores, justifications, and comparative assessments, are mechanically saved to your specified S3 output path for downstream evaluation and visualization.
Outcomes from Amazon Nova rubric-based LLM-as-a-judge analysis job
The next is an instance end result for a row of the analysis. On this instance, Assistant B is the clear winner as a result of it prioritizes grounded, nuanced data over Assistant A’s suspiciously particular however unverified declare of 145 newspapers. The decide penalizes Assistant A for its lack of context, leading to considerably decrease scores for accuracy and completeness. By making use of a {custom} weight that allocates 50% of the whole rating to accuracy, the analysis calculates a weighted margin that quantifies exactly why Assistant B’s detailed, verifiable response is superior.
As within the put up Evaluating generative AI models with Amazon Nova LLM-as-a-Judge on Amazon SageMaker AI, to assist practitioners shortly interpret the end result of an Amazon Nova rubric-based LLM-as-a-judge analysis, we created a comfort perform that produces a single, complete visualization summarizing key metrics, as proven within the following screenshot.
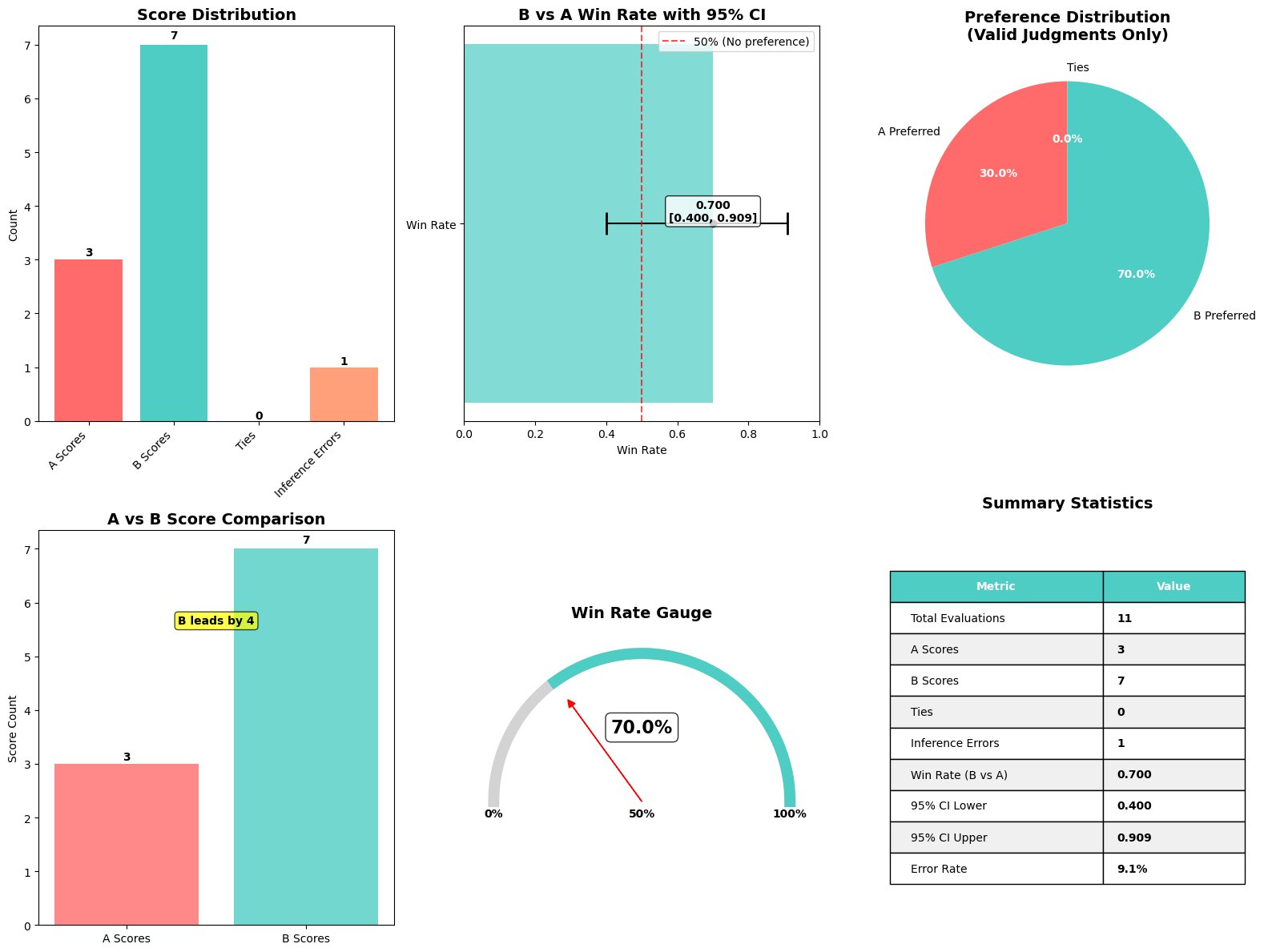
This perform, plot_nova_judge_results, makes use of Matplotlib and Seaborn to render a picture with six panels, every highlighting a distinct perspective of the analysis end result.
This perform takes the analysis metrics dictionary produced when the analysis job is full and generates the next visible elements:
- Rating distribution bar chart – Reveals what number of instances Mannequin A was most well-liked (three wins), what number of instances Mannequin B was most well-liked (seven wins), what number of ties occurred, and the way typically the decide failed to provide a call (one inference error out of 11 evaluations). This supplies a right away sense of how decisive the analysis was, clearly displaying Mannequin B’s dominance with a 70% desire price.
- Win price with 95% confidence interval – Plots Mannequin B’s total win price of 70% in opposition to Mannequin A, together with an error bar reflecting the arrogance interval bounds of [0.400, 0.909]. A vertical reference line at 50% marks the purpose of no desire. As a result of the arrogance interval doesn’t cross this line, we are able to conclude the result’s statistically vital, indicating significant superiority for the 7B mannequin.
- Desire pie chart – Visually shows the proportion of preferences among the many 10 legitimate judgments: 70% for Mannequin B and 30% for Mannequin A. This may also help customers shortly perceive the clear desire distribution favoring the bigger mannequin.
- A vs. B rating comparability bar chart – Compares the uncooked counts of preferences for every mannequin aspect by aspect (three for Mannequin A vs seven for Mannequin B). A transparent label annotates the margin of distinction, emphasizing Mannequin B’s four-win benefit. The chart additionally shows the weighted rubric-based scores: Mannequin A averaged 0.495 whereas Mannequin B averaged 0.630 throughout all analysis standards (accuracy, completeness, readability), with a mean margin of -0.135 favoring Mannequin B.
- Win price gauge – Depicts the 70% win price as a semicircular gauge with a needle pointing to Mannequin B’s efficiency relative to the theoretical 0–100% vary. This intuitive visualization helps nontechnical stakeholders instantly grasp that Mannequin B outperformed Mannequin A by a considerable margin based mostly on dynamically generated rubric standards tailor-made to every question-answer pair.
- Abstract statistics desk – Compiles numerical metrics right into a compact, clear desk: 11 whole evaluations, one error (9.1% error price), 70% win price, weighted rubric scores (0.630 for B vs 0.495 for A with -0.135 margin), and confidence intervals [0.400, 0.909]. This makes it simple to reference the precise numeric values behind the plots and perceive each the statistical rigor and rubric-based evaluation of the analysis.
As a result of the perform outputs a regular Matplotlib determine, you may shortly save the picture, show it in Jupyter notebooks, or embed it in different documentation. The visualization clearly demonstrates that Mannequin B reveals statistically vital superiority total with greater rubric-based scores throughout accuracy, completeness, and readability dimensions.
Clear up
To cease and delete the SageMaker Studio areas, comply with these clear up steps within the SageMaker Studio documentation. You should delete the S3 bucket and the hosted mannequin endpoint to cease incurring prices. You’ll be able to delete the real-time endpoints you created utilizing the SageMaker console. For directions, see Delete Endpoints and Resources.
Conclusion
Evaluating generative AI outputs at scale requires greater than easy desire labels, it requires transparency into why one response outperforms one other. The Amazon Nova rubric-based LLM decide addresses this want by dynamically producing task-specific analysis standards, offering per-criterion scores with express justifications, and delivering well-calibrated confidence alerts. In comparison with earlier decide implementations, the rubric-based strategy affords three key benefits: interpretability by means of structured YAML output with criterion-level breakdowns, flexibility enabling customers to reweight or filter standards for his or her particular use instances, and improved accuracy with vital positive factors throughout normal benchmarks—together with a 49% enchancment on complicated analysis eventualities in JudgeBench. In case you are choosing mannequin checkpoints throughout improvement, filtering coaching information for high quality, or debugging manufacturing mannequin habits at scale, the Amazon Nova rubric-based LLM-as-a-judge analysis transforms opaque desire selections into actionable insights. By exposing the reasoning behind every judgment, groups can determine systematic weaknesses, validate that evaluations align with their high quality priorities, and construct better belief in automated analysis pipelines.
To get began with the Amazon Nova rubric-based LLM decide on SageMaker AI, confer with Rubric Based Judge.
Concerning the authors
 Surya Kari is a Senior Generative AI Information Scientist at AWS, specializing in growing options leveraging state-of-the-art basis fashions. He has in depth expertise working with superior language fashions together with DeepSeek-R1, the Llama household, and Qwen, specializing in their fine-tuning and optimization for particular scientific functions. His experience extends to implementing environment friendly coaching pipelines and deployment methods utilizing AWS SageMaker, enabling the scaling of basis fashions from improvement to manufacturing. He collaborates with clients to design and implement generative AI options, serving to them navigate mannequin choice, fine-tuning approaches, and deployment methods to attain optimum efficiency for his or her particular use instances.
Surya Kari is a Senior Generative AI Information Scientist at AWS, specializing in growing options leveraging state-of-the-art basis fashions. He has in depth expertise working with superior language fashions together with DeepSeek-R1, the Llama household, and Qwen, specializing in their fine-tuning and optimization for particular scientific functions. His experience extends to implementing environment friendly coaching pipelines and deployment methods utilizing AWS SageMaker, enabling the scaling of basis fashions from improvement to manufacturing. He collaborates with clients to design and implement generative AI options, serving to them navigate mannequin choice, fine-tuning approaches, and deployment methods to attain optimum efficiency for his or her particular use instances.
 Joseph Moulton is a Software program Engineer on the Amazon AGI Customization group supporting the implementation of analysis and inference workflows for AWS Nova Forge. Present work focuses on growing and implementing new methods for patrons to guage their {custom} educated Nova fashions. He has been with the corporate as a software program engineer for 4 years, becoming a member of the Alexa AI Machine Studying platform group in 2022 earlier than transitioning to the Nova Forge group in 2025. In his free time he enjoys {golfing} and constructing computer systems.
Joseph Moulton is a Software program Engineer on the Amazon AGI Customization group supporting the implementation of analysis and inference workflows for AWS Nova Forge. Present work focuses on growing and implementing new methods for patrons to guage their {custom} educated Nova fashions. He has been with the corporate as a software program engineer for 4 years, becoming a member of the Alexa AI Machine Studying platform group in 2022 earlier than transitioning to the Nova Forge group in 2025. In his free time he enjoys {golfing} and constructing computer systems.
 Morteza Ziyadi is an senior science lead and supervisor at Amazon AGI, the place he leads a number of tasks on post-training recipes and (Multimodal) giant language fashions within the Amazon AGI Basis modeling group. Earlier than becoming a member of Amazon AGI, he spent 4 years at Microsoft Cloud and AI, the place he led tasks targeted on growing pure language-to-code era fashions for numerous merchandise. He has additionally served as an adjunct college at Northeastern College. He earned his PhD from the College of Southern California (USC) in 2017 and has since been actively concerned as a workshop organizer, and reviewer for quite a few NLP, Pc Imaginative and prescient and machine studying conferences.
Morteza Ziyadi is an senior science lead and supervisor at Amazon AGI, the place he leads a number of tasks on post-training recipes and (Multimodal) giant language fashions within the Amazon AGI Basis modeling group. Earlier than becoming a member of Amazon AGI, he spent 4 years at Microsoft Cloud and AI, the place he led tasks targeted on growing pure language-to-code era fashions for numerous merchandise. He has additionally served as an adjunct college at Northeastern College. He earned his PhD from the College of Southern California (USC) in 2017 and has since been actively concerned as a workshop organizer, and reviewer for quite a few NLP, Pc Imaginative and prescient and machine studying conferences.
 Rajkumar Pujari is an Utilized Scientist II on the Nova Fashions post-training group at Amazon AGI. He obtained his Ph.D. in Pc Science from Purdue College, specializing in Machine Studying for Computational Social Science. At present, his work focuses on post-training and reinforcement studying for Giant Language Fashions. He develops large-scale, dynamic analysis pipelines for frontier fashions and builds LLM-as-a-Choose frameworks.
Rajkumar Pujari is an Utilized Scientist II on the Nova Fashions post-training group at Amazon AGI. He obtained his Ph.D. in Pc Science from Purdue College, specializing in Machine Studying for Computational Social Science. At present, his work focuses on post-training and reinforcement studying for Giant Language Fashions. He develops large-scale, dynamic analysis pipelines for frontier fashions and builds LLM-as-a-Choose frameworks.
 Swastik Roy is a Senior Utilized Scientist on Amazon’s AGI Basis group, specializing in generalizability analysis and post-training of the Amazon Nova household of fashions. His experience spans fine-tuning, reinforcement studying, and analysis methodologies, the place he drives efforts to advance the robustness of foundational AI techniques.
Swastik Roy is a Senior Utilized Scientist on Amazon’s AGI Basis group, specializing in generalizability analysis and post-training of the Amazon Nova household of fashions. His experience spans fine-tuning, reinforcement studying, and analysis methodologies, the place he drives efforts to advance the robustness of foundational AI techniques.
 Joel Catapano is a Senior Utilized Scientist on the Amazon AGI basis modeling group. He primarily works on growing novel approaches for enhancing the LLM-as-a-Choose functionality of the Nova household of fashions.
Joel Catapano is a Senior Utilized Scientist on the Amazon AGI basis modeling group. He primarily works on growing novel approaches for enhancing the LLM-as-a-Choose functionality of the Nova household of fashions.
 Mona Mona is a Sr World Huge Gen AI Specialist Options Architect specializing in Gen AI Options in Amazon SageMaker AI group. She was a Lead Generative AI specialist in Google earlier than becoming a member of Amazon. She is a broadcast writer of two books – Pure Language Processing with AWS AI Providers and Google Cloud Licensed Skilled Machine Studying Research Information. She has authored 20+ blogs on AI/ML and cloud know-how and a co-author on a analysis paper on CORD19 Neural Search which received an award for Greatest Analysis Paper on the prestigious AAAI (Affiliation for the Development of Synthetic Intelligence) convention.
Mona Mona is a Sr World Huge Gen AI Specialist Options Architect specializing in Gen AI Options in Amazon SageMaker AI group. She was a Lead Generative AI specialist in Google earlier than becoming a member of Amazon. She is a broadcast writer of two books – Pure Language Processing with AWS AI Providers and Google Cloud Licensed Skilled Machine Studying Research Information. She has authored 20+ blogs on AI/ML and cloud know-how and a co-author on a analysis paper on CORD19 Neural Search which received an award for Greatest Analysis Paper on the prestigious AAAI (Affiliation for the Development of Synthetic Intelligence) convention.
 Pradeep Natarajan is a Senior Principal Scientist in Amazon AGI Basis modeling group engaged on post-training recipes and Multimodal giant language fashions. He has 20+ years of expertise in growing and launching a number of large-scale machine studying techniques. He has a PhD in Pc Science from College of Southern California.
Pradeep Natarajan is a Senior Principal Scientist in Amazon AGI Basis modeling group engaged on post-training recipes and Multimodal giant language fashions. He has 20+ years of expertise in growing and launching a number of large-scale machine studying techniques. He has a PhD in Pc Science from College of Southern California.




