Construct and deploy scalable AI brokers with NVIDIA NeMo, Amazon Bedrock AgentCore, and Strands Brokers

This put up is co-written with Ranjit Rajan, Abdullahi Olaoye, and Abhishek Sawarkar from NVIDIA.
AI’s subsequent frontier isn’t merely smarter chat-based assistants, it’s autonomous brokers that cause, plan, and execute throughout whole programs. However to perform this, enterprise builders want to maneuver from prototypes to production-ready AI brokers that scale securely. This problem grows as enterprise issues turn into extra advanced, requiring architectures the place a number of specialised brokers collaborate to perform refined duties.
Constructing AI brokers in improvement differs essentially from deploying them at scale. Builders face a chasm between prototype and manufacturing, battling efficiency optimization, useful resource scaling, safety implementation, and operational monitoring. Typical approaches go away groups juggling a number of disconnected instruments and frameworks, making it troublesome to keep up consistency from improvement by means of deployment with optimum efficiency. That’s the place the highly effective mixture of Strands Agents, Amazon Bedrock AgentCore, and NVIDIA NeMo Agent Toolkit shine. You should use these instruments collectively to design refined multi-agent programs, orchestrate them, and scale them securely in manufacturing with built-in observability, agent analysis, profiling, and efficiency optimization. This put up demonstrates tips on how to use this built-in resolution to construct, consider, optimize, and deploy AI brokers on Amazon Web Services (AWS) from preliminary improvement by means of manufacturing deployment.
Basis for enterprise-ready brokers
The open supply Strands Brokers framework simplifies AI agent improvement by means of its model-driven method. Builders create brokers utilizing three parts:
- Foundation models (FMs) comparable to Amazon Nova, Claude by Anthropic, and Meta’s Llama
- Instruments (over 20 built-in, plus customized instruments utilizing Python decorators)
- Prompts that information agent habits.
The framework consists of built-in integrations with AWS providers comparable to Amazon Bedrock and Amazon Simple Storage Service (Amazon S3), native testing help, steady integration and steady improvement (CI/CD) workflows, a number of deployment choices, and OpenTelemetry observability.
Amazon Bedrock AgentCore is an agentic platform for constructing, deploying, and working efficient brokers securely at scale. It has composable, totally managed providers:
- Runtime for safe, serverless agent deployment
- Reminiscence for short-term and long-term context retention
- Gateway for safe instrument entry by remodeling APIs and AWS Lambda features into agent-compatible instruments and connecting to current Model Context Protocol (MCP) servers
- Id for safe agent id and entry administration
- Code Interpreter for safe code execution in sandbox environments
- Browser for quick, safe net interactions
- Observability for complete operational insights to hint, debug, and monitor agent efficiency
- Evaluations for repeatedly inspecting agent high quality primarily based on real-world habits
- Coverage to maintain brokers inside outlined boundaries
These providers, designed to work independently or collectively, summary the complexity of constructing, deploying, and working refined brokers whereas working with open supply frameworks or fashions delivering enterprise-grade safety and reliability.
Agent analysis, profiling, and optimization with NeMo Agent Toolkit
NVIDIA NeMo Agent Toolkit is an open supply framework designed to assist builders construct, profile, and optimize AI brokers no matter their underlying framework. Its framework-agnostic method means it really works seamlessly with Strands Brokers, LangChain, LlamaIndex, CrewAI, and customized enterprise frameworks. As well as, totally different frameworks can interoperate after they’re related within the NeMo Agent Toolkit.
The toolkit’s profiler offers full agent workflow evaluation that tracks token utilization, timing, workflow-specific latency, throughput, and run instances for particular person brokers and instruments, enabling focused efficiency enhancements. Constructed on the toolkit’s analysis harness, it consists of Retrieval Augmented Generation (RAG)-specific evaluators (comparable to reply accuracy, context relevance, response groundedness, and agent trajectory) and helps customized evaluators for specialised use instances, enabling focused efficiency optimization. The automated hyperparameter optimizer profiles and systematically discovers optimum settings for parameters comparable to temperature, top_p, and max_tokens whereas maximizing accuracy, groundedness, context relevance, and minimizing token utilization, latency, and optimizing for different customized metrics as nicely. This automated method profiles your full agent workflows, recognized bottlenecks, and uncovers optimum parameter mixtures that handbook tuning may miss. The toolkit’s clever GPU sizing calculator alleviates guesswork by simulating agent latency and concurrency eventualities and predicting exact GPU infrastructure necessities for manufacturing deployment.
The toolkit’s observability integration connects with common monitoring providers together with Arize Phoenix, Weights & Biases Weave, Langfuse, and OpenTelemetry supported programs, like Amazon Bedrock AgentCore Observability, making a steady suggestions loop for ongoing optimization and upkeep.
Actual-world implementation
This instance demonstrates a knowledge-based agent that retrieves and synthesizes data from net URLs to reply person queries. Constructed utilizing Strands Brokers with built-in NeMo Agent Toolkit, the answer is containerized for fast deployment in Amazon Bedrock AgentCore Runtime and takes benefit of Bedrock AgentCore providers, comparable to AgentCore Observability. Moreover, builders have the pliability to combine with totally managed fashions in Amazon Bedrock, fashions hosted in Amazon SageMaker AI, containerized fashions in Amazon Elastic Kubernetes Service (Amazon EKS) or different mannequin API endpoints. The general structure is designed for a streamlined workflow, transferring from agent definition and optimization to containerization and scalable deployment.
The next structure diagram illustrates an agent constructed with Strands Brokers integrating NeMo Agent Toolkit deployed in Amazon Bedrock AgentCore.
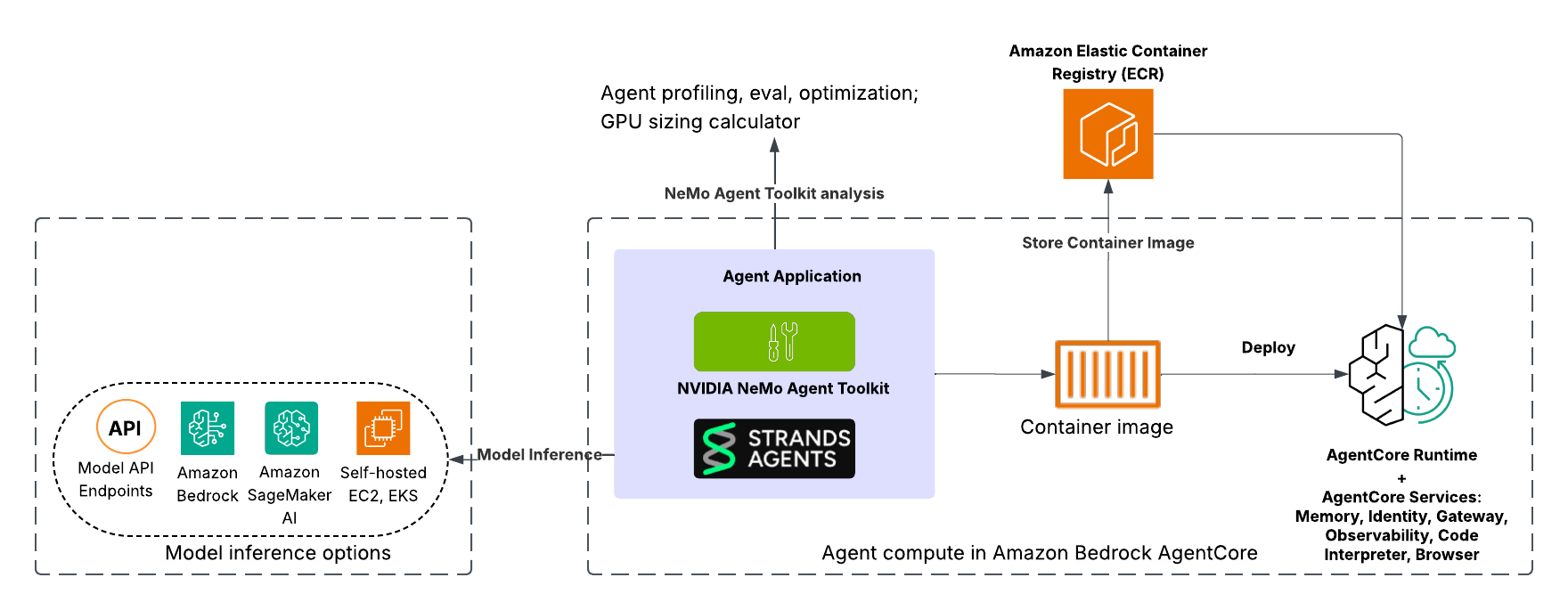
Agent improvement and analysis
Begin by defining your agent and workflows in Strands Brokers, then wrap it with NeMo Agent Toolkit to configure parts comparable to a large language model (LLM) for inference and instruments. Seek advice from the Strands Agents and NeMo Agent Toolkit integration example in GitHub for an in depth setup information. After configuring your setting, validate your agent logic by operating a single workflow from the command line with an instance immediate:
The next is the truncated terminal output:
As a substitute of executing a single workflow and exiting, to simulate a real-world state of affairs, you’ll be able to spin up a long-running API server able to dealing with concurrent requests with the serve command:
The next is the truncated terminal output:
The agent is now operating domestically on port 8080. To work together with the agent, open a brand new terminal and execute the next cURL command. This can generate output much like the earlier nat run step however the agent runs repeatedly as a persistent service moderately than executing one time and exiting. This simulates the manufacturing setting the place Amazon Bedrock AgentCore will run the agent as a containerized service:
The next is the truncated terminal output:
Agent profiling and workflow efficiency monitoring
With the agent operating, the subsequent step is to determine a efficiency baseline. As an instance the depth of insights obtainable, on this instance, we use a self-managed Llama 3.3 70B Instruct NIM on an Amazon Elastic Compute Cloud (Amazon EC2) P4de.24xlarge occasion powered by NVIDIA A100 Tensor Core GPUs (8xA100 80 GB GPU) operating on Amazon EKS. We use the nat eval command to guage the agent and generate the evaluation:
nat eval --config_file examples/frameworks/strands_demo/configs/eval_config.yml
The next is the truncated terminal output:
The command generates detailed artifacts that embrace JSON recordsdata per analysis metric (comparable to accuracy, groundedness, relevance, and Trajectory accuracy) displaying scores from 0–1, reasoning traces, retrieved contexts, and aggregated averages. Further data within the artifacts generated embrace workflow outputs, standardized tables, profile traces, and compact summaries for latency and token effectivity. This multi-metric sweep offers a holistic view of agent high quality and habits. The analysis highlights that whereas the agent achieved constant groundedness scores—which means solutions have been reliably supported by sources—there’s nonetheless a chance to enhance retrieval relevance. The profile hint output incorporates workflow-specific latency, throughput, and runtime at 90%, 95%, and 99% confidence intervals. The command generates a Gantt chart of the agent move and nested stack evaluation to pinpoint precisely the place bottlenecks exist, as seen within the following determine. It additionally experiences concurrency spikes and token effectivity so you’ll be able to perceive exactly how scaling impacts immediate and completion utilization.
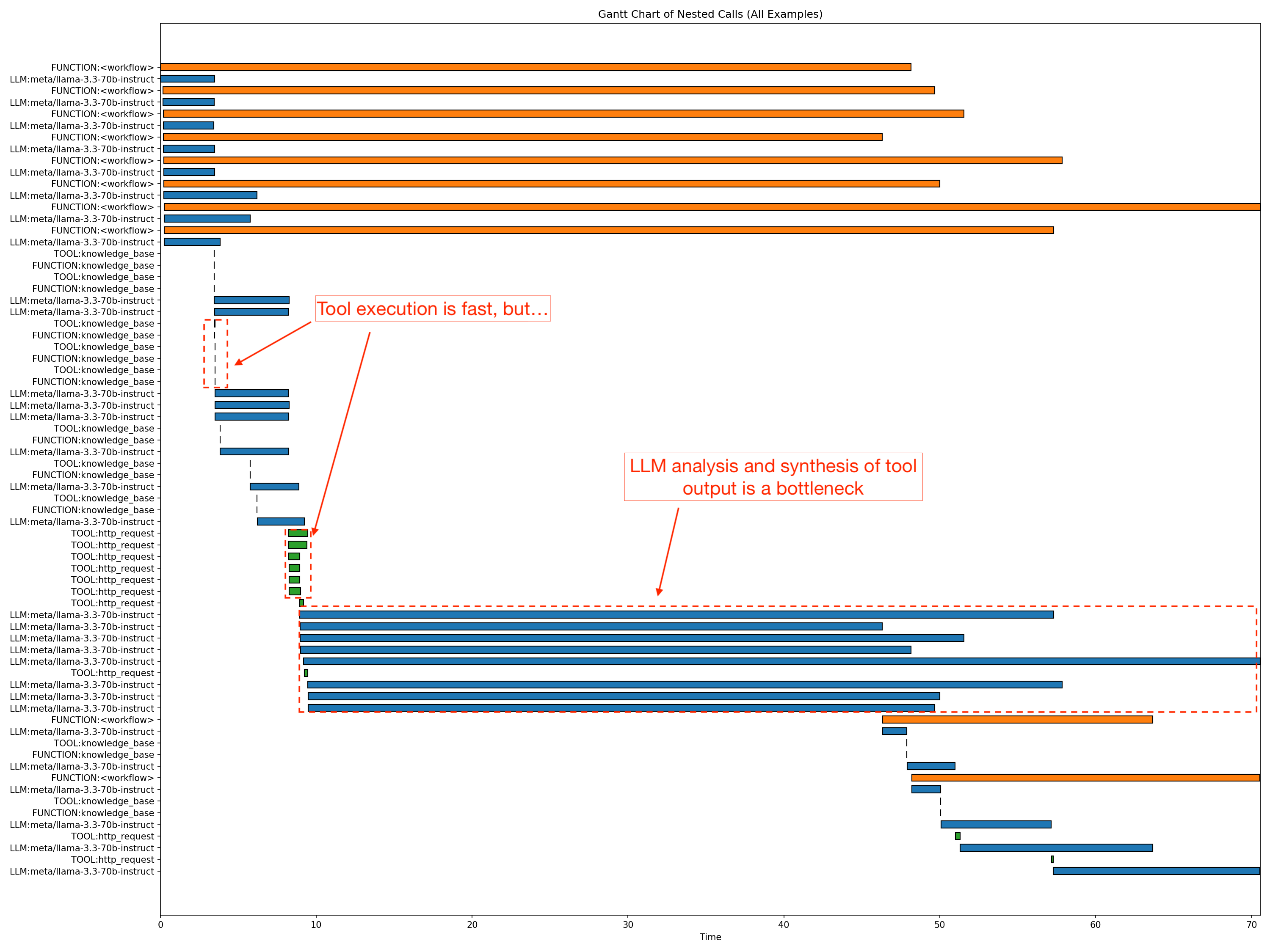
In the course of the profiling, nat spawns eight concurrent agent workflows (proven in orange bars within the chart), which is the default concurrency configuration throughout analysis. The p90 latency for the workflow proven is roughly 58.9 seconds. Crucially, the info confirmed that response technology was the first bottleneck, with the longest LLM segments taking roughly 61.4 seconds. In the meantime, non-LLM overhead remained minimal. HTTP requests averaged solely 0.7–1.2 seconds, and information base entry was negligible. Utilizing this degree of granularity, now you can establish and optimize particular bottlenecks within the agent workflows.
Agent efficiency optimization
After profiling, refine the agent’s parameters to steadiness high quality, efficiency, and price. Guide tuning of LLM settings like temperature and top_p is commonly a sport of guesswork. The NeMo Agent Toolkit turns this right into a data-driven science. You should use the built-in optimizer to carry out a scientific sweep throughout your parameter search area:
nat optimize --config_file examples/frameworks/strands_demo/configs/optimizer_config.yml
The next is the truncated terminal output:
This command launches an automatic sweep throughout key LLM parameters, comparable to temperature, top_p, and max_tokens, as outlined within the config (on this case optimizer_config.yml) search area. The optimizer runs 20 trials with three repetitions every, utilizing weighted analysis metrics to routinely uncover optimum mannequin settings. It would take as much as 15–20 minutes for the optimizer to run 20 trials.
The toolkit evaluates every parameter set towards a weighted multi-objective rating, aiming to maximise high quality (for instance, accuracy, groundedness, or instrument use) whereas minimizing token price and latency. Upon completion, it generates detailed efficiency artifacts and abstract tables so you’ll be able to shortly establish and choose the optimum configuration for manufacturing. The next is the hyperparameter optimizer configuration:
On this instance, NeMo Agent Toolkit Optimize systematically evaluated parameter configurations and recognized temperature ≈ 0.7, top_p ≈ 1.0, and max_tokens ≈ 6k (6144) as optimum configuration yielding the best accuracy throughout 20 trials. This configuration delivered a 35% accuracy enchancment over baseline whereas concurrently attaining 20% token effectivity beneficial properties in comparison with the 8192 max_tokens setting—maximizing each efficiency and price effectivity for these manufacturing deployments.
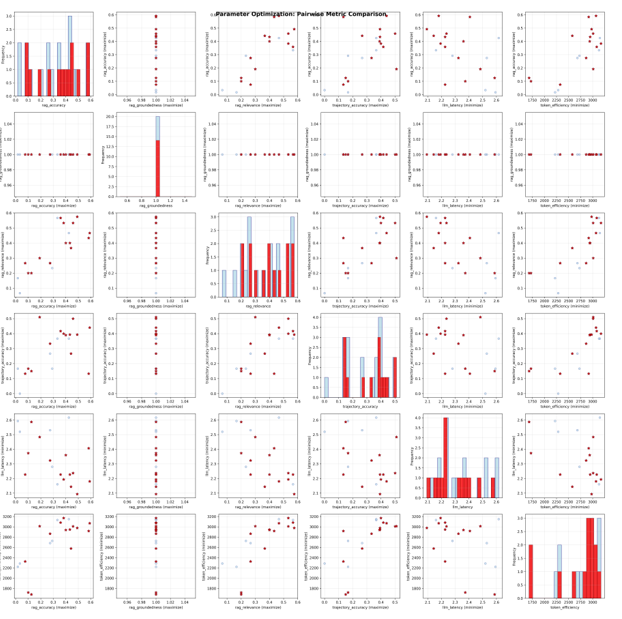
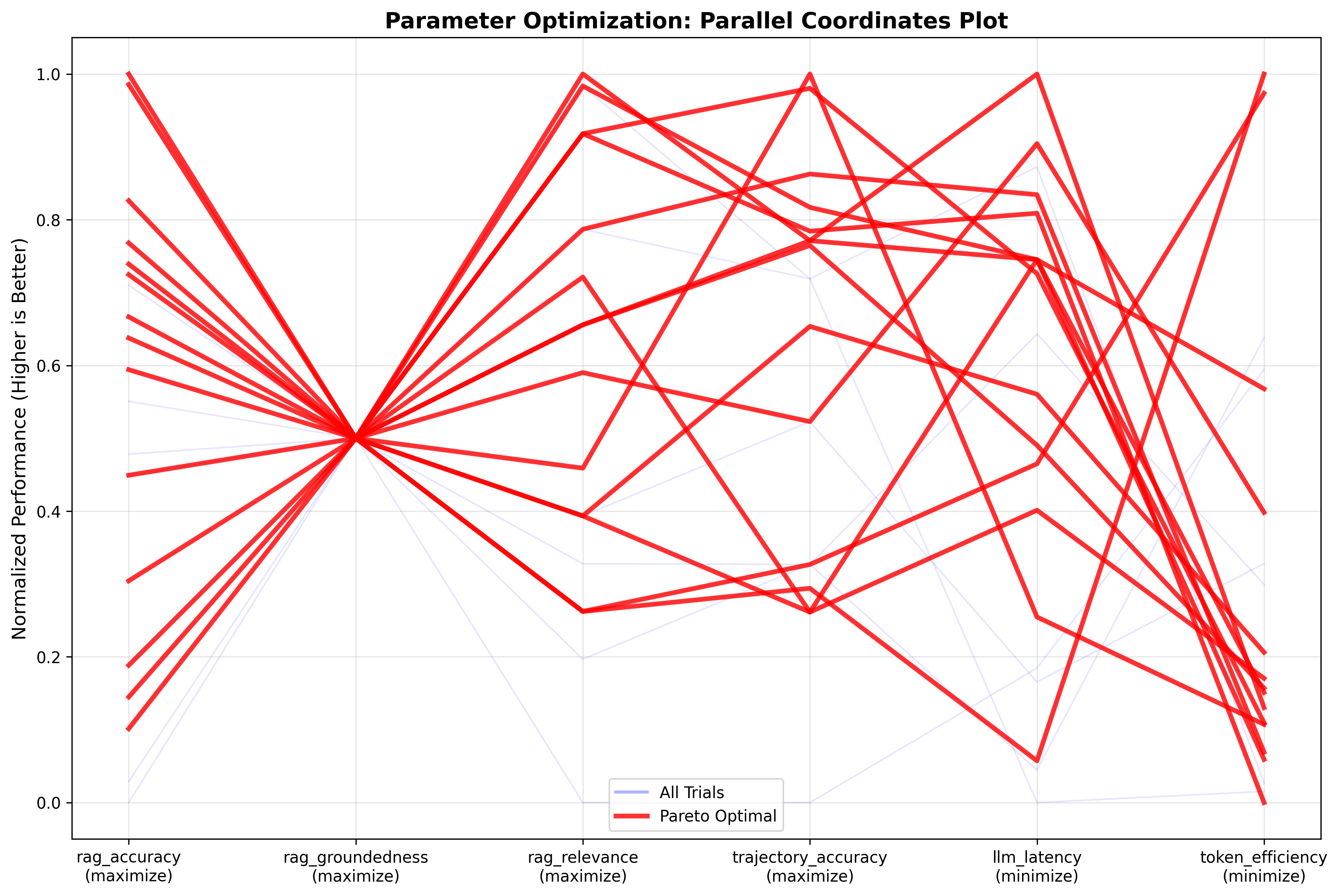
The optimizer plots pairwise pareto curves, as proven within the following pairwise matrix comparability charts, to research trade-offs between totally different parameters. The parallel coordinates plot, that follows the matrix comparability chart, reveals optimum trials (pink strains) attaining top quality scores (0.8–1.0) throughout accuracy, groundedness, and relevance whereas buying and selling off some effectivity as token utilization and latency drop to 0.6–0.8 on the normalized scale. The pairwise matrix confirms sturdy correlations between high quality metrics and divulges precise token consumption clustered tightly round 2,500–3,100 tokens throughout all trials. These outcomes point out that additional beneficial properties in accuracy and token effectivity could be attainable by means of immediate engineering. That is one thing that improvement groups can obtain utilizing NeMo Agent Toolkit’s immediate optimization capabilities, serving to cut back prices whereas maximizing efficiency.
The next picture reveals the pairwise matrix comparability:
The next picture reveals the parallel coordinates plot:
Proper-sizing manufacturing GPU infrastructure
After your agent is optimized and also you’ve finalized the runtime or inference configuration, you’ll be able to shift your focus to assessing your mannequin deployment infrastructure. In the event you’re self-managing your mannequin deployment on a fleet of EC2 GPU-powered cases, then one of the vital troublesome features of transferring brokers to manufacturing is predicting precisely what compute assets are essential to help a goal use case and concurrent customers with out overrunning the funds or inflicting timeouts. The NeMo Agent Toolkit GPU sizing calculator addresses this problem by utilizing your agent’s precise efficiency profile to find out the optimum cluster measurement for particular service degree targets (SLOs), enabling right-sizing that alleviates the trade-off between efficiency and price. To generate a sizing profile, you run the sizing calculator throughout a spread of concurrency ranges (for instance, 1–32 simultaneous customers):
Executing this on our reference EC2 P4de.24xlarge occasion powered by NVIDIA A100 Tensor Core GPUs operating on Amazon EKS for a Llama 3.3 70B Instruct NIM produced the next capability evaluation:
As proven within the following chart, calculated concurrency scales nearly linearly with each latency and finish‑to‑finish runtime, with P95 LLM latency and workflow runtime demonstrating near-perfect development matches (R² ≈ 0.977/0.983). Every further concurrent request introduces a predictable latency penalty, suggesting the system operates inside a linear capability zone the place throughput might be optimized by adjusting latency tolerance.
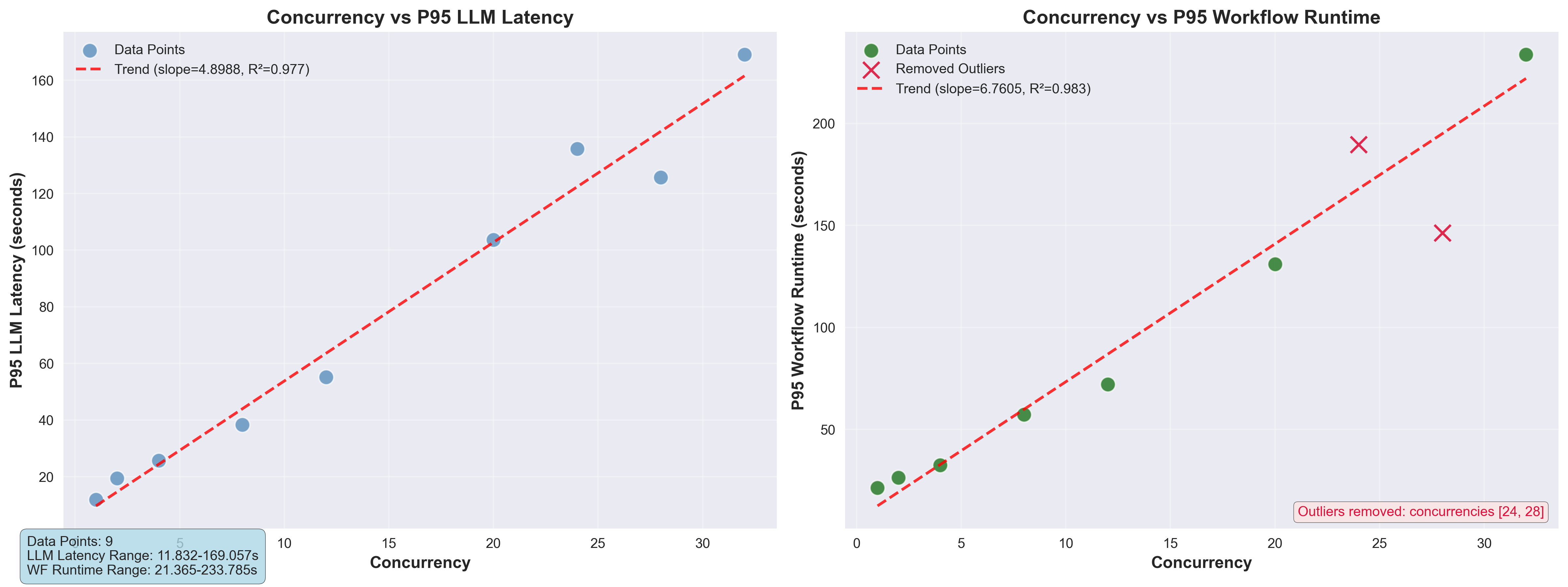
With the sizing metrics captured, you’ll be able to estimate the GPU cluster measurement for a particular concurrency and latency. For instance, to help 25 concurrent customers with a goal workflow runtime of fifty seconds, you’ll be able to run the calculator:
This workflow analyzes present efficiency metrics and generates a useful resource advice. In our instance state of affairs, the instrument calculates that to fulfill strict latency necessities for 25 simultaneous customers, roughly 30 GPUs are required primarily based on the next system:
The next is the output from the sizing estimation:
Manufacturing agent deployment to Amazon Bedrock AgentCore
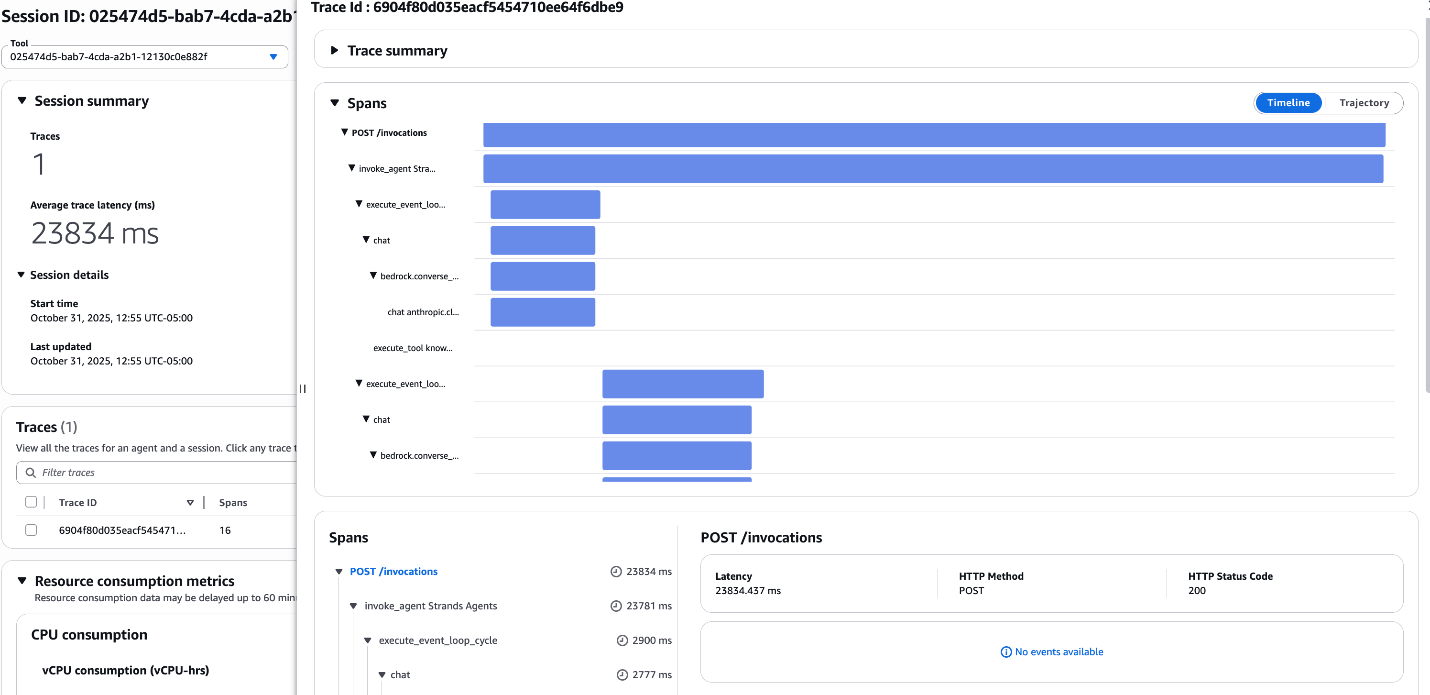
After evaluating, profiling, and optimizing your agent, deploy it to manufacturing. Though operating the agent domestically is ample for testing, enterprise deployment requires an agent runtime that helps present safety, scalability, and strong reminiscence administration with out the overhead of managing infrastructure. That is the place Amazon Bedrock AgentCore Runtime shines—offering enterprise-grade serverless agent runtime with out the infrastructure overhead. Seek advice from the step-by-step deployment information within the NeMo Agent Toolkit Repository. By packaging your optimized agent in a container and deploying it to the serverless Bedrock AgentCore Runtime, you elevate your prototype agent to a resilient software for long-running duties and concurrent person requests. After you deploy the agent, visibility turns into vital. This integration creates a unified observability expertise, remodeling opaque black-box execution into deep visibility. You achieve precise traces, spans, and latency breakdowns for each interplay in manufacturing, built-in into Bedrock AgentCore Observability utilizing OpenTelemetry.
The next screenshot reveals the Amazon CloudWatch dashboard displaying Amazon Bedrock AgentCore traces and spans, visualizing the execution path and latency of the deployed Strands agent.
Amazon Bedrock AgentCore providers prolong nicely past agent runtime administration and observability. Your deployed brokers can seamlessly use further Bedrock AgentCore providers, together with Amazon Bedrock AgentCore Identity for authentication and authorization, Amazon Bedrock AgentCore Gateway for instruments entry, Amazon Bedrock AgentCore Memory for context-awareness, Amazon Bedrock AgentCore Code Interpreter for safe code execution, and Amazon Bedrock AgentCore Browser for net interactions, to create enterprise-ready brokers.
Conclusion
Manufacturing AI brokers want efficiency visibility, optimization, and dependable infrastructure. For the instance use case, this integration delivered on all three fronts: attaining 20% token effectivity beneficial properties, 35% accuracy enhancements for the instance use case, and performance-tuned GPU infrastructure calibrated for goal concurrency. By combining Strands Brokers for foundational agent improvement and orchestration, the NVIDIA NeMo Agent Toolkit for deep agent profiling, optimization, and right-sizing manufacturing GPU infrastructure, and Amazon Bedrock AgentCore for safe, scalable agent infrastructure, builders can have an end-to-end resolution that helps present predictable outcomes. Now you can construct, consider, optimize, and deploy brokers at scale on AWS with this built-in resolution. To get began, take a look at the Strands Agents and NeMo Agent Toolkit integration example and deploying Strands Agents and NeMo Agent Toolkit to Amazon Bedrock AgentCore Runtime.
Concerning the authors
 Kosti Vasilakakis is a Principal PM at AWS on the Agentic AI staff, the place he has led the design and improvement of a number of Bedrock AgentCore providers from the bottom up, together with Runtime, Browser, Code Interpreter, and Id. He beforehand labored on Amazon SageMaker since its early days, launching AI/ML capabilities now utilized by 1000’s of corporations worldwide. Earlier in his profession, Kosti was a knowledge scientist. Exterior of labor, he builds private productiveness automations, performs tennis, and enjoys life together with his spouse and children.
Kosti Vasilakakis is a Principal PM at AWS on the Agentic AI staff, the place he has led the design and improvement of a number of Bedrock AgentCore providers from the bottom up, together with Runtime, Browser, Code Interpreter, and Id. He beforehand labored on Amazon SageMaker since its early days, launching AI/ML capabilities now utilized by 1000’s of corporations worldwide. Earlier in his profession, Kosti was a knowledge scientist. Exterior of labor, he builds private productiveness automations, performs tennis, and enjoys life together with his spouse and children.
 Sagar Murthy is an agentic AI GTM chief at AWS, the place he collaborates with frontier basis mannequin companions, agentic frameworks, startups, and enterprise prospects to evangelize AI and knowledge improvements, open-source options, and scale impactful partnerships. With collaboration experiences spanning knowledge, cloud and AI, he brings a mix of technical options background and enterprise outcomes focus to please builders and prospects.
Sagar Murthy is an agentic AI GTM chief at AWS, the place he collaborates with frontier basis mannequin companions, agentic frameworks, startups, and enterprise prospects to evangelize AI and knowledge improvements, open-source options, and scale impactful partnerships. With collaboration experiences spanning knowledge, cloud and AI, he brings a mix of technical options background and enterprise outcomes focus to please builders and prospects.
 Chris Smith is a Options Architect at AWS specializing in AI-powered automation and enterprise AI agent orchestration. With over a decade of expertise architecting options on the intersection of generative AI, cloud computing, and programs integration, he helps organizations design and deploy agent programs that rework rising applied sciences into measurable enterprise outcomes. His work spans technical structure, security-first implementation, and cross-functional staff management.
Chris Smith is a Options Architect at AWS specializing in AI-powered automation and enterprise AI agent orchestration. With over a decade of expertise architecting options on the intersection of generative AI, cloud computing, and programs integration, he helps organizations design and deploy agent programs that rework rising applied sciences into measurable enterprise outcomes. His work spans technical structure, security-first implementation, and cross-functional staff management.
 Ranjit Rajan is a Senior Options Architect at NVIDIA, the place he helps prospects design and construct options spanning generative AI, agentic AI, and accelerated multi-modal knowledge processing pipelines for pre-training and fine-tuning basis fashions.
Ranjit Rajan is a Senior Options Architect at NVIDIA, the place he helps prospects design and construct options spanning generative AI, agentic AI, and accelerated multi-modal knowledge processing pipelines for pre-training and fine-tuning basis fashions.
 Abdullahi Olaoye is a Senior AI Options Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and merchandise with cloud AI providers and open-source instruments to optimize AI mannequin deployment, inference, and generative AI workflows. He collaborates with AWS to reinforce AI workload efficiency and drive adoption of NVIDIA-powered AI and generative AI options.
Abdullahi Olaoye is a Senior AI Options Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and merchandise with cloud AI providers and open-source instruments to optimize AI mannequin deployment, inference, and generative AI workflows. He collaborates with AWS to reinforce AI workload efficiency and drive adoption of NVIDIA-powered AI and generative AI options.
 Abhishek Sawarkar is a product supervisor within the NVIDIA AI Enterprise staff engaged on Agentic AI. He focuses on product technique and roadmap of integrating Agentic AI library in associate platforms & enhancing person expertise on accelerated computing for AI Brokers.
Abhishek Sawarkar is a product supervisor within the NVIDIA AI Enterprise staff engaged on Agentic AI. He focuses on product technique and roadmap of integrating Agentic AI library in associate platforms & enhancing person expertise on accelerated computing for AI Brokers.






