Tencent Hunyuan Releases HunyuanOCR: a 1B Parameter Finish to Finish OCR Skilled VLM
Tencent Hunyuan has launched HunyuanOCR, a 1B parameter imaginative and prescient language mannequin that’s specialised for OCR and doc understanding. The mannequin is constructed on Hunyuan’s native multimodal structure and runs recognizing, parsing, info extraction, visible query answering, and textual content picture translation by way of a single finish to finish pipeline.
HunyuanOCR is a light-weight different to normal VLMs equivalent to Gemini 2.5 and Qwen3 VL that also matches or surpasses them on OCR centric duties. It targets manufacturing use instances like doc parsing, card and receipt extraction, video subtitle extraction, and multilingual doc translation.
Structure, Native Decision ViT plus Light-weight LLM
HunyuanOCR makes use of 3 fundamental modules, a Native Decision Visible Encoder referred to as Hunyuan ViT, an Adaptive MLP Connector, and a Light-weight Language Mannequin. The encoder is predicated on SigLIP-v2-400M and is prolonged to help arbitrary enter resolutions by way of adaptive patching that preserves the unique facet ratio. Photographs are break up into patches based on their native proportions and processed with world consideration, which improves recognition on lengthy textual content strains, lengthy paperwork, and low high quality scans.
The Adaptive MLP Connector performs learnable pooling on the spatial dimension. It compresses the dense visible tokens right into a shorter sequence, whereas maintaining info from textual content dense areas. This reduces sequence size handed to the language mannequin and lowers compute, whereas preserving OCR related particulars.
The language mannequin is predicated on the densely architected Hunyuan 0.5B mannequin and makes use of XD RoPE. XD RoPE splits rotary place embeddings into 4 subspaces for textual content, peak, width, and time. This offers the mannequin a local solution to align 1D token order with 2D format and 3D spatiotemporal construction. In consequence, the identical stack can deal with multi column pages, cross web page flows, and sequences of video frames.
Coaching and inference comply with a totally finish to finish paradigm. There is no such thing as a exterior format evaluation or submit processing mannequin within the loop. All duties are expressed as pure language prompts and dealt with in a single ahead go. This design removes error propagation throughout pipeline levels and simplifies deployment.

Knowledge and Pre Coaching Recipe
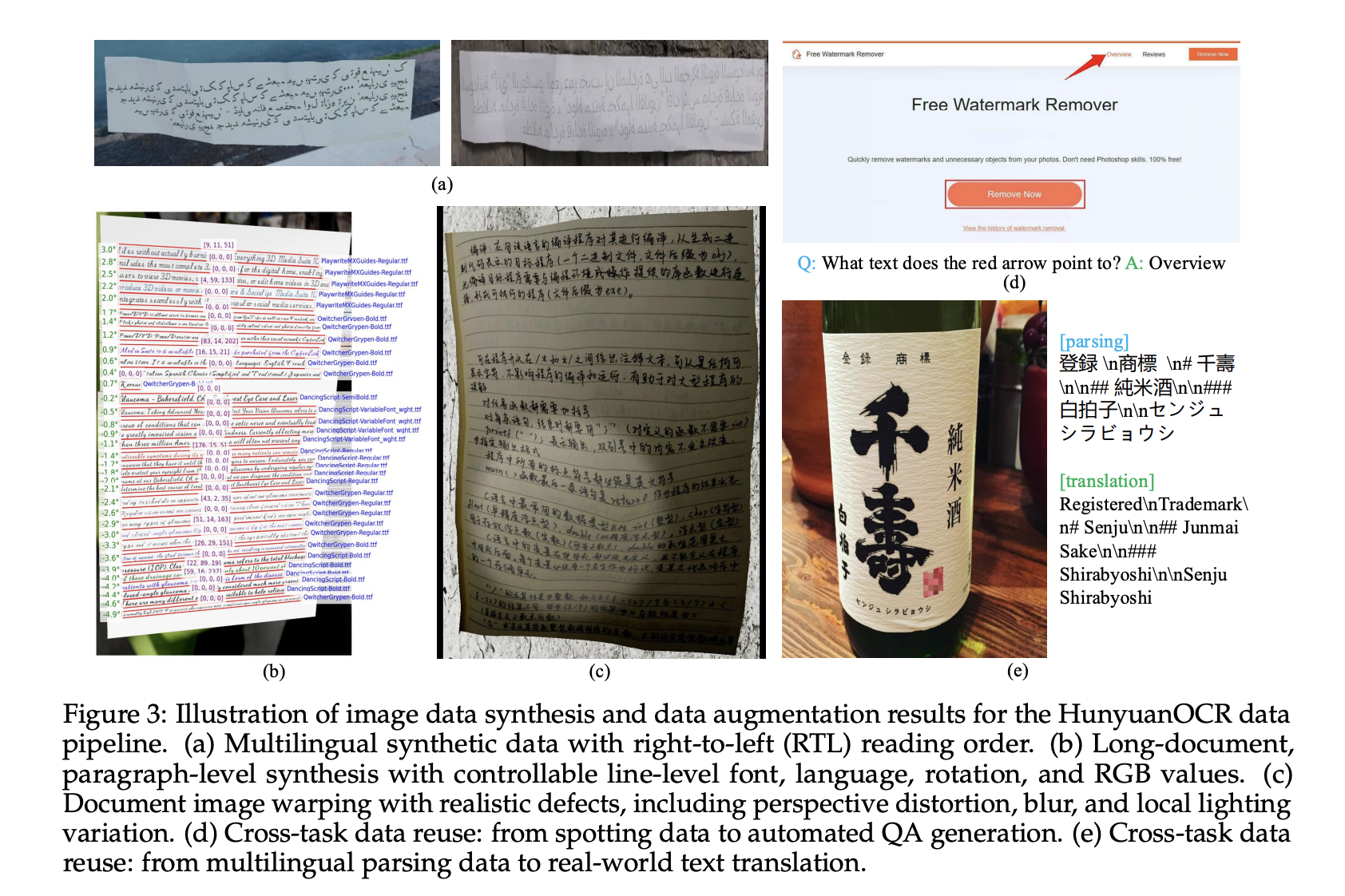
The info pipeline builds greater than 200M picture textual content pairs, throughout 9 actual world situations, together with road views, paperwork, commercials, handwritten textual content, screenshots, playing cards and certificates and invoices, recreation interfaces, video frames, and creative typography. The corpus covers greater than 130 languages.
Artificial knowledge comes from a multilingual generator that helps proper to left scripts and paragraph degree rendering. The pipeline controls font, language, rotation, and RGB values, and applies warping, blur, and native lighting adjustments to simulate cellular captures and different onerous circumstances.
Pre coaching follows 4 levels. Stage-1 performs imaginative and prescient language alignment with pure textual content, artificial parsing and recognition knowledge, and normal caption knowledge, utilizing 50B tokens and 8k context. Stage-2 runs multimodal pre coaching on 300B tokens that blend pure textual content with artificial recognizing, parsing, translation, and VQA samples. Stage-3 extends context size to 32k with 80B tokens centered on lengthy paperwork and lengthy textual content. Stage-4 is software oriented supervised superb tuning on 24B tokens of human annotated and onerous unfavourable knowledge, maintaining 32k context and unified instruction templates.
Reinforcement Studying with Verifiable Rewards
After supervised coaching, HunyuanOCR is additional optimized with reinforcement studying. The analysis group use Group Relative Coverage Optimization GRPO and a Reinforcement Studying with Verifiable Rewards setup for structured duties. For textual content recognizing, the reward is predicated on intersection over union matching of packing containers mixed with normalized edit distance over textual content. For doc parsing, the reward makes use of normalized edit distance between the generated construction and the reference.
For VQA and translation, the system makes use of an LLM as a choose. VQA makes use of a binary reward that checks semantic match. Translation makes use of a COMET type scoring LLM with scores in [0, 5], normalized to [0, 1]. The coaching framework enforces size limits and strict codecs, and assigns zero reward when outputs overflow or break schema, which stabilizes optimization and encourages legitimate JSON or structured outputs.
Benchmark Outcomes, a 1B Mannequin Competing with Bigger VLMs
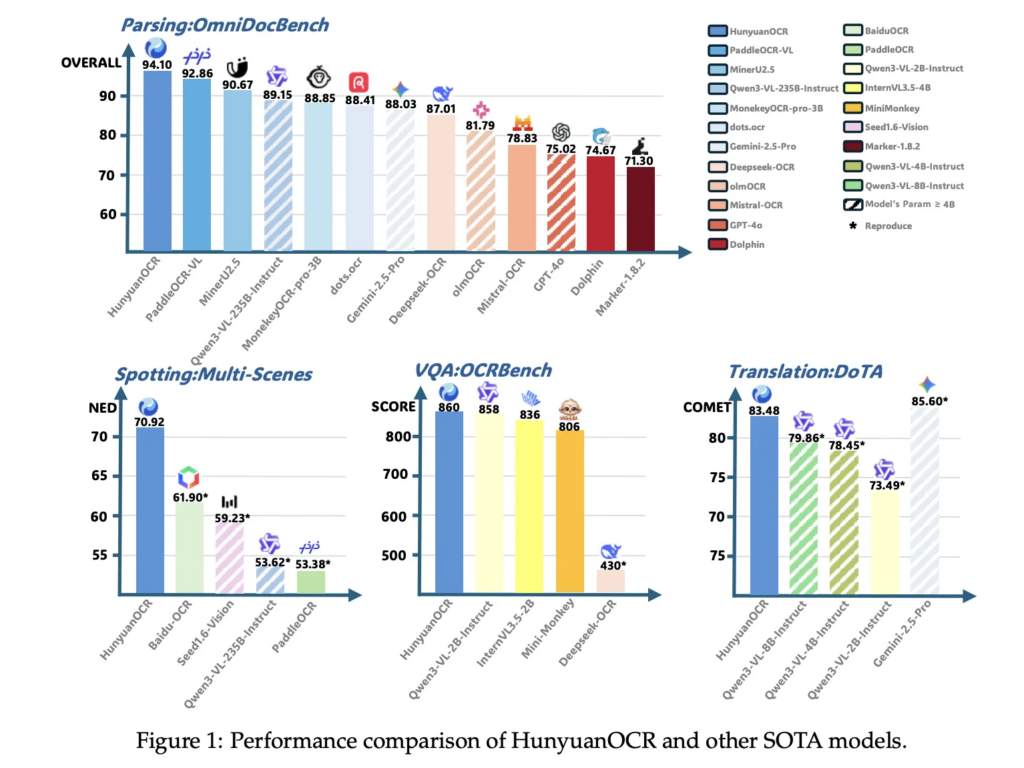
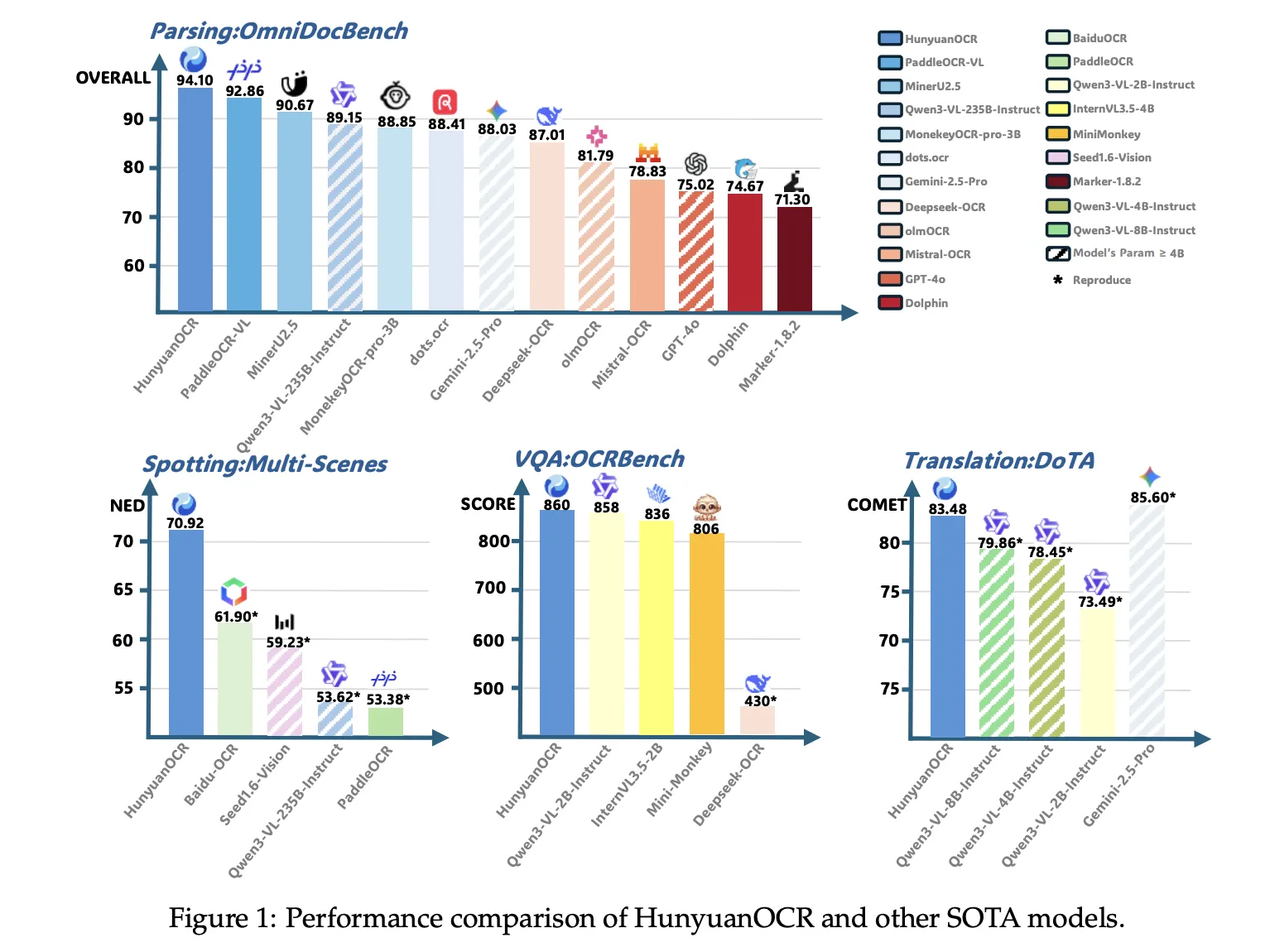
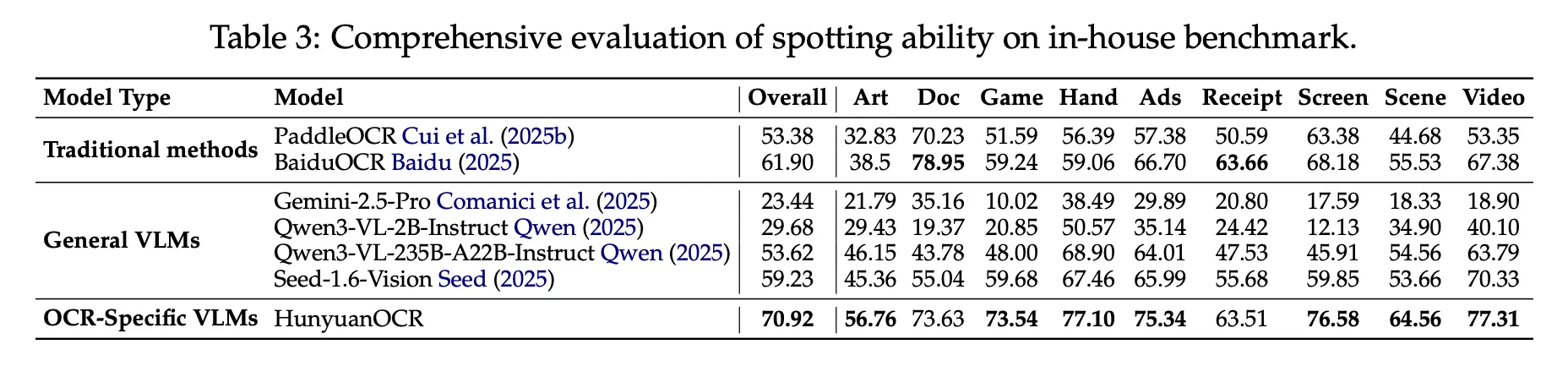
On the inner textual content recognizing benchmark of 900 pictures throughout 9 classes, HunyuanOCR reaches an total rating of 70.92. It outperforms conventional pipeline strategies like PaddleOCR and BaiduOCR and in addition normal VLMs equivalent to Gemini 2.5 Professional, Qwen3 VL 2B, Qwen3 VL 235B, and Seed 1.6 Imaginative and prescient, regardless of utilizing far fewer parameters.
On OmniDocBench, HunyuanOCR achieves 94.10 total, with 94.73 on formulation and 91.81 on tables. On the Wild OmniDocBench variant, which prints and recaptures paperwork beneath folds and lighting adjustments, it scores 85.21 total. On DocML, a multilingual parsing benchmark throughout 14 non Chinese language and non English languages, it reaches 91.03, and the paper experiences state-of-the-art outcomes throughout all 14 languages.
For info extraction and VQA, HunyuanOCR reaches 92.29 accuracy on playing cards, 92.53 on receipts, and 92.87 on video subtitles. On OCRBench, it scores 860, increased than DeepSeek OCR at related scale and near bigger normal VLMs like Qwen3 VL 2B Instruct and Gemini 2.5 Professional.
In textual content picture translation, HunyuanOCR makes use of the DoTA benchmark and a DocML based mostly inner set. It achieves a powerful COMET rating on DoTA for English to Chinese language doc translation, and the mannequin wins first place in Observe 2.2 OCR free Small Mannequin of the ICDAR 2025 DIMT competitors.
Key Takeaways
- Compact finish to finish OCR VLM: HunyuanOCR is a 1B parameter OCR centered imaginative and prescient language mannequin that connects a 0.4B native decision ViT to a 0.5B Hunyuan language mannequin by way of an MLP adapter, and runs recognizing, parsing, info extraction, VQA and translation in a single finish to finish instruction pushed pipeline with out exterior format or detection modules.
- Unified help for various OCR situations: The mannequin is educated on greater than 200M picture textual content pairs throughout 9 situations, together with paperwork, road views, commercials, handwritten content material, screenshots, playing cards and invoices, recreation interfaces and video frames, with protection of over 130 languages in coaching and help for greater than 100 languages in deployment.
- Knowledge pipeline plus reinforcement studying: Coaching makes use of a 4 stage recipe, imaginative and prescient language alignment, multimodal pre coaching, lengthy context pre coaching and software oriented supervised superb tuning, adopted by reinforcement studying with group relative coverage optimization and verifiable rewards for recognizing, parsing, VQA and translation.
- Robust benchmark outcomes for sub 3B fashions
HunyuanOCR reaches 94.1 on OmniDocBench for doc understanding, and achieves 860 on OCRBench, which is reported as state-of-the-art amongst imaginative and prescient language fashions with fewer than 3B parameters, whereas additionally outperforming a number of industrial OCR APIs and bigger open fashions equivalent to Qwen3 VL 4B on core OCR benchmarks.
Editorial Notes
HunyuanOCR is a powerful sign that OCR particular VLMs are maturing into sensible infrastructure, not simply benchmarks. Tencent combines a 1B parameter finish to finish structure with Native Imaginative and prescient Transformer, Adaptive MLP Connector and RL with verifiable rewards to ship a single mannequin that covers recognizing, parsing, IE, VQA and translation throughout greater than 100 languages, and it does so whereas reaching main scores on OCRBench for sub 3B fashions and 94.1 on OmniDocBench. General, HunyuanOCR marks an vital shift towards compact, instruction pushed OCR engines which can be reasonable for manufacturing deployment.
Try the Paper, Model weight and Repo. Be at liberty to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The submit Tencent Hunyuan Releases HunyuanOCR: a 1B Parameter End to End OCR Expert VLM appeared first on MarkTechPost.