Construct Agentic Workflows with OpenAI GPT OSS on Amazon SageMaker AI and Amazon Bedrock AgentCore
OpenAI has launched two open-weight fashions, gpt-oss-120b (117 billion parameters) and gpt-oss-20b (21 billion parameters), each constructed with a Combination of Specialists (MoE) design and a 128K context window. These fashions are the main open supply fashions, in response to Artificial Analysis benchmarks, and excel at reasoning and agentic workflows. With Amazon SageMaker AI, you’ll be able to fine-tune or customise fashions and deploy along with your selection of framework by means of a completely managed service. Amazon SageMaker Inference offers you the flexibleness to deliver your individual inference code and framework with out having to construct and preserve your individual clusters.
Though giant language fashions (LLMs) excel at understanding language and producing content material, constructing real-world agentic functions requires complicated workflow administration, software calling capabilities, and context administration. Multi-agent architectures tackle these challenges by breaking down complicated programs into specialised parts, however they introduce new complexities in agent coordination, reminiscence administration, and workflow orchestration.
On this publish, we present easy methods to deploy gpt-oss-20b mannequin to SageMaker managed endpoints and display a sensible inventory analyzer agent assistant instance with LangGraph, a strong graph-based framework that handles state administration, coordinated workflows, and chronic reminiscence programs. We are going to then deploy our brokers to Amazon Bedrock AgentCore, a unified orchestration layer that abstracts away infrastructure and means that you can securely deploy and function AI brokers at scale.
Answer overview
On this answer, we construct an agentic inventory analyzer with the next key parts:
- The GPT OSS 20B mannequin deployed to a SageMaker endpoint utilizing vLLM, an open supply serving framework for LLMs
- LangGraph to construct a multi-agent orchestration framework
- Amazon Bedrock AgentCore to deploy the brokers
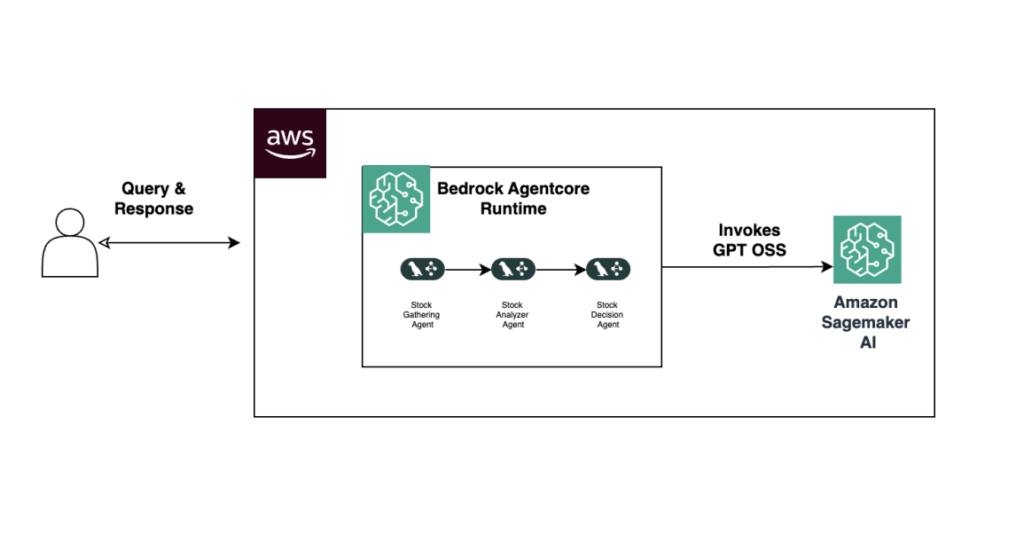
The next diagram illustrates the answer structure.

This structure illustrates a multi-agent workflow hosted on Amazon Bedrock AgentCore Runtime working on AWS. A person submits a question, which is dealt with by a pipeline of specialised brokers—Information Gathering Agent, Inventory Efficiency Analyzer Agent, and Inventory Report Era Agent—which are every liable for a definite a part of the inventory analysis course of.
These brokers collaborate inside Amazon Bedrock AgentCore Runtime, and when language understanding or era is required, they invoke a GPT OSS mannequin hosted on SageMaker AI. The mannequin processes the enter and returns structured outputs that inform agent actions, enabling a completely serverless, modular, and scalable agentic system utilizing open-source fashions.
Conditions
- Guarantee that you’ve got required quota for G6e cases to deploy the mannequin. Request quota here if you don’t.
- If that is your first time working with Amazon SageMaker Studio, you first have to create a SageMaker domain.
- Guarantee your IAM function has required permissions to deploy SageMaker Fashions and Endpoints. For extra data, see How Amazon SageMaker AI works with IAM within the SageMaker Developer Information.
Deploy GPT-OSS fashions to SageMaker Inference
Clients who need to customise their fashions and frameworks can deploy utilizing serverful deployments, however this requires entry to GPUs, serving frameworks, load balancers, and infrastructure setup. SageMaker AI supplies a completely managed internet hosting platform that takes care of provisioning the infrastructure with the required drivers, downloads the fashions, and deploys them. OpenAI’s GPT-OSS fashions are launched with a 4-bit quantization scheme (MXFP4), enabling quick inference whereas preserving useful resource utilization low. These fashions can run on P5(H100), P6(H200), and P4(A100) and G6e(L40) cases.The GPT-OSS fashions are sparse MoE architectures with 128 consultants (120B) or 32 consultants (20B), the place every token is routed to 4 consultants with no shared knowledgeable. Utilizing MXFP4 for MoE weights alone reduces the mannequin sizes to 63 GB (120B) and 14 GB (20B), making them runnable on a single H100 GPU.
To deploy these fashions successfully, you want a strong serving framework like vLLM. To deploy the mannequin, we construct a vLLM container with the most recent model that helps GPT OSS fashions on SageMaker AI.
You should use the next Docker file and script to construct the container and push it to an area Amazon Elastic Container Registry (Amazon ECR). The really helpful method is to do that instantly from Amazon SageMaker Studio, which supplies a managed JupyterLab setting with AWS CLI entry the place you’ll be able to construct and push photographs to ECR as a part of your SageMaker workflow. Alternatively, you too can carry out the identical steps on an Amazon Elastic Compute Cloud (Amazon EC2) occasion with Docker put in.
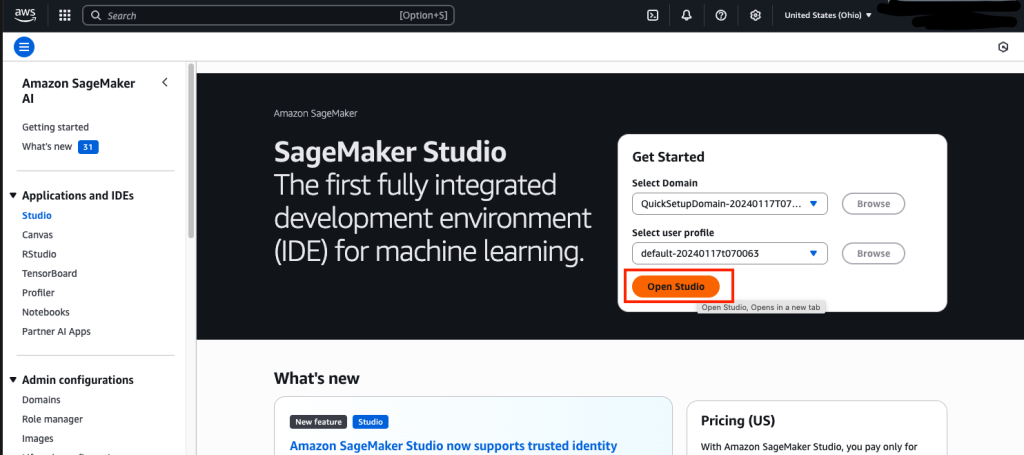
After you will have constructed and pushed the container to Amazon ECR, you’ll be able to open Amazon SageMaker Studio by going to the SageMaker AI console, as proven within the following screenshot.
You possibly can then create a Jupyter house or use an current one to launch JupyterLab and run notebooks.
Clone the next notebook and run “Choice 3: Deploying from HF utilizing BYOC.” Replace the required parameters, such because the inference picture within the pocket book with the container picture. We additionally present needed setting variables, as proven within the following code.
After you arrange the deployment configuration, you’ll be able to deploy to SageMaker AI utilizing the next code:
Now you can run an inference instance:
Use LangGraph to construct a inventory analyzer agent
For our inventory analyzing multi-agent system, we use LangGraph to orchestrate the workflow. Jupyter pocket book for the code is situated on this github repository. The system includes three specialised instruments that work collectively to research shares comprehensively:
- The
gather_stock_datasoftware collects complete inventory information for a given ticker image, together with present worth, historic efficiency, monetary metrics, and market information. It returns formatted data protecting worth historical past, firm fundamentals, buying and selling metrics, and up to date information headlines. - The
analyze_stock_performancesoftware performs detailed technical and elementary evaluation of inventory information, calculating metrics like worth tendencies, volatility, and general funding scores. It evaluates a number of components together with P/E ratios, revenue margins, and dividend yields to offer a complete efficiency evaluation - The
generate_stock_reportsoftware creates skilled PDF reviews from the gathered inventory information and evaluation, robotically importing them to Amazon S3 with organized date-based folders.
For native testing, you should utilize a simplified model of the system by importing the required features out of your native script. For instance:
This manner, you’ll be able to iterate shortly in your agent’s logic earlier than deploying it to a scalable platform, ensuring every part features appropriately and the general workflow produces the anticipated outcomes for various kinds of shares.
Deploy to Amazon Bedrock AgentCore
After you will have developed and examined your LangGraph framework regionally, you’ll be able to deploy it to Amazon Bedrock AgentCore Runtime. Amazon Bedrock AgentCore handles the heavy lifting of container orchestration, session administration, scalability and abstracting the administration of infrastructure. It supplies persistent execution environments that may preserve an agent’s state throughout a number of invocations.
Earlier than deploying our inventory analyzer agent to Amazon Bedrock AgentCore Runtime, we have to create an AWS Identity and Access Management IAM function with the suitable permissions. This function permits Amazon Bedrock AgentCore to invoke your SageMaker endpoint for GPT-OSS mannequin inference, handle ECR repositories for storing container photographs, write Amazon CloudWatch logs for monitoring and debugging, entry Amazon Bedrock AgentCore workload providers for runtime operations, and ship telemetry information to AWS X-Ray and CloudWatch for observability. See the next code:
After creating the function, you should utilize the Amazon Bedrock AgentCore Starter Toolkit to deploy your agent. The toolkit simplifies the deployment course of by packaging your code, creating the required container picture, and configuring the runtime setting:
Once you’re utilizing BedrockAgentCoreApp, it robotically creates an HTTP server that listens on port 8080, implements the required /invocations endpoint for processing the agent’s necessities, implements the/ping endpoint for well being checks (which is essential for asynchronous brokers), handles correct content material varieties and response codecs, and manages error dealing with in response to AWS requirements.
After you deploy to Amazon Bedrock AgentCore Runtime, it is possible for you to to see the standing present as Prepared on the Amazon Bedrock AgentCore console.
Invoke the agent
After you create the agent, you should arrange the agent invocation entry level. With Amazon AgentCore Runtime, we embellish the invocation a part of our agent with the @app.entrypoint decorator and use it because the entry level for our runtime. After you deploy the agent to Amazon AgentCore Runtime, you’ll be able to invoke it utilizing the AWS SDK:
After invoking the inventory analyzer agent by means of Amazon Bedrock AgentCore Runtime, you should parse and format the response for clear presentation. The response processing includes the next steps:
- Decode the byte stream from Amazon Bedrock AgentCore into readable textual content.
- Parse the JSON response containing the whole inventory evaluation.
- Extract three predominant sections utilizing regex sample matching:
- Inventory Information Gathering Part: Extracts core inventory data together with image, firm particulars, present pricing, market metrics, monetary ratios, buying and selling information, and up to date information headlines.
- Efficiency Evaluation part: Analyzes technical indicators, elementary metrics, and volatility measures to generate complete inventory evaluation.
- Inventory Report Era Part: Generates an in depth PDF report with all of the Inventory Technical Evaluation.
The system additionally consists of error dealing with that gracefully handles JSON parsing errors, falls again to plain textual content show if structured parsing fails, and supplies debugging data for troubleshooting parsing problems with the inventory evaluation response.
This formatted output makes it simple to evaluation the agent’s decision-making course of and current skilled inventory evaluation outcomes to stakeholders, finishing the end-to-end workflow from mannequin deployment to significant enterprise output:
Clear up
You possibly can delete the SageMaker endpoint to keep away from accruing prices after your testing by working the next cells in the identical pocket book:
You can too delete Amazon Bedrock AgentCore assets utilizing the next instructions:
Conclusion
On this publish, we constructed an end-to-end answer for deploying OpenAI’s open-weight fashions on a single G6e(L40s) GPU, making a multi-agent inventory evaluation system with LangGraph and deploying it seamlessly with Amazon Bedrock AgentCore. This implementation demonstrates how organizations can now use highly effective open supply LLMs cost-effectively with environment friendly serving frameworks resembling vLLM. Past the technical implementation, enhancing this workflow can present important enterprise worth, resembling discount in inventory evaluation processing time, elevated analyst productiveness by automating routine inventory assessments. Moreover, by releasing analysts from repetitive duties, organizations can redirect expert professionals towards complicated circumstances and relationship-building actions that drive enterprise development.
We invite you to check out our code samples and iterate your agentic workflows to satisfy your use circumstances.
In regards to the authors
 Vivek Gangasani is a Worldwide Lead GenAI Specialist Options Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product technique for SageMaker Inference. He additionally helps enterprises and startups deploy, handle, and scale their GenAI fashions with SageMaker and GPUs. Presently, he’s centered on creating methods and options for optimizing inference efficiency and GPU effectivity for internet hosting Massive Language Fashions. In his free time, Vivek enjoys mountain climbing, watching motion pictures, and making an attempt totally different cuisines.
Vivek Gangasani is a Worldwide Lead GenAI Specialist Options Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product technique for SageMaker Inference. He additionally helps enterprises and startups deploy, handle, and scale their GenAI fashions with SageMaker and GPUs. Presently, he’s centered on creating methods and options for optimizing inference efficiency and GPU effectivity for internet hosting Massive Language Fashions. In his free time, Vivek enjoys mountain climbing, watching motion pictures, and making an attempt totally different cuisines.
 Surya Kari is a Senior Generative AI Information Scientist at AWS, specializing in creating options leveraging state-of-the-art basis fashions. He has intensive expertise working with superior language fashions together with DeepSeek-R1, the Llama household, and Qwen, specializing in their fine-tuning and optimization for particular scientific functions. His experience extends to implementing environment friendly coaching pipelines and deployment methods utilizing AWS SageMaker, enabling the scaling of basis fashions from growth to manufacturing. He collaborates with clients to design and implement generative AI options, serving to them navigate mannequin choice, fine-tuning approaches, and deployment methods to realize optimum efficiency for his or her particular use circumstances.
Surya Kari is a Senior Generative AI Information Scientist at AWS, specializing in creating options leveraging state-of-the-art basis fashions. He has intensive expertise working with superior language fashions together with DeepSeek-R1, the Llama household, and Qwen, specializing in their fine-tuning and optimization for particular scientific functions. His experience extends to implementing environment friendly coaching pipelines and deployment methods utilizing AWS SageMaker, enabling the scaling of basis fashions from growth to manufacturing. He collaborates with clients to design and implement generative AI options, serving to them navigate mannequin choice, fine-tuning approaches, and deployment methods to realize optimum efficiency for his or her particular use circumstances.