Construct Your Personal AI Coding Assistant in JupyterLab with Ollama and Hugging Face
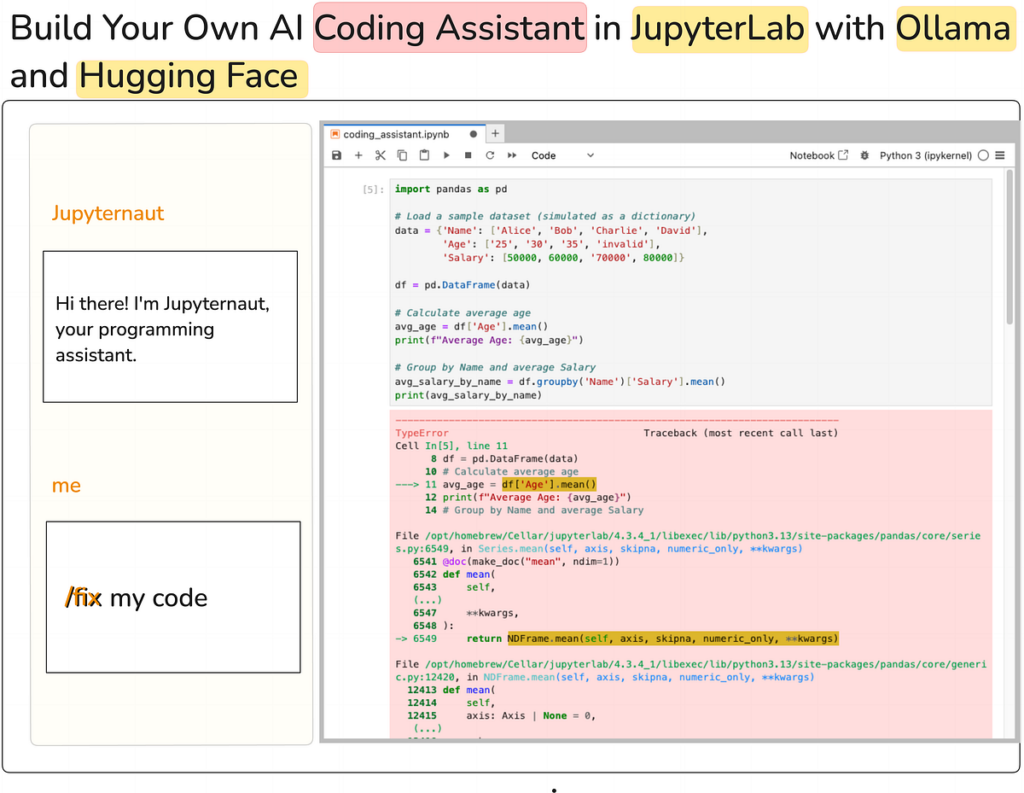
Jupyter AI brings generative AI capabilities proper into the interface. Having an area AI assistant ensures privateness, reduces latency, and offers offline performance, making it a robust instrument for builders. On this article, we’ll discover ways to arrange an area AI coding assistant in JupyterLab utilizing Jupyter AI, Ollama and Hugging Face. By the top of this text, you’ll have a completely useful coding assistant in JupyterLab able to autocompleting code, fixing errors, creating new notebooks from scratch, and rather more, as proven within the screenshot under.

Jupyter AI remains to be below heavy growth, so some options might break. As of writing this text, I’ve examined the setup to substantiate it really works, however count on potential changes because the venture evolves. Additionally the efficiency of the assistant will depend on the mannequin that you choose so be sure you select the one that’s match in your use case.
First issues first — what’s Jupyter AI? Because the title suggests, Jupyter AI is a JupyterLab extension for generative AI. This highly effective instrument transforms your commonplace Jupyter notebooks or JupyterLab surroundings right into a generative AI playground. One of the best half? It additionally works seamlessly in environments like Google Colaboratory and Visible Studio Code. This extension does all of the heavy lifting, offering entry to a wide range of mannequin suppliers (each open and closed supply) proper inside your Jupyter surroundings.

Establishing the surroundings includes three foremost parts:
- JupyterLab
- The Jupyter AI extension
- Ollama (for Native Mannequin Serving)
- [Optional] Hugging Face (for GGUF fashions)
Actually, getting the assistant to resolve coding errors is the simple half. What is hard is guaranteeing all of the installations have been carried out accurately. It’s due to this fact important you comply with the steps accurately.
1. Putting in the Jupyter AI Extension
It’s really helpful to create a new environment particularly for Jupyter AI to maintain your present surroundings clear and organised. As soon as carried out comply with the subsequent steps. Jupyter AI requires JupyterLab 4.x or Jupyter Pocket book 7+, so be sure you have the most recent model of Jupyter Lab put in. You’ll be able to set up/improve JupyterLab with pip or conda:
# Set up JupyterLab 4 utilizing pip
pip set up jupyterlab~=4.0Subsequent, set up the Jupyter AI extension as follows.
pip set up "jupyter-ai[all]"That is the best methodology for set up because it contains all supplier dependencies (so it helps Hugging Face, Ollama, and so on., out of the field). To this point, Jupyter AI helps the next model providers :

If you happen to encounter errors through the Jupyter AI set up, manually set up Jupyter AI utilizing pip with out the [all] optionally available dependency group. This fashion you’ll be able to management which fashions can be found in your Jupyter AI surroundings. For instance, to put in Jupyter AI with solely added assist for Ollama fashions, use the next:
pip set up jupyter-ai langchain-ollamaThe dependencies depend on the mannequin suppliers (see desk above). Subsequent, restart your JupyterLab occasion. If you happen to see a chat icon on the left sidebar, this implies every little thing has been put in completely. With Jupyter AI, you’ll be able to chat with fashions or use inline magic instructions instantly inside your notebooks.

2. Setting Up Ollama for Native Fashions
Now that Jupyter AI is put in, we have to configure it with a mannequin. Whereas Jupyter AI integrates with Hugging Face fashions instantly, some fashions may not work properly. As a substitute, Ollama offers a extra dependable strategy to load fashions regionally.
Ollama is a useful instrument for operating Large Language Models regionally. It enables you to obtain pre-configured AI fashions from its library. Ollama helps all main platforms (macOS, Home windows, Linux), so select the tactic in your OS and obtain and set up it from the official website. After set up, confirm that it’s arrange accurately by operating:
Ollama --version
------------------------------
ollama model is 0.6.2Additionally, be sure that your Ollama server should be operating which you’ll verify by calling ollama serve on the terminal:
$ ollama serve
Error: pay attention tcp 127.0.0.1:11434: bind: handle already in useIf the server is already energetic, you will notice an error like above confirming that Ollama is operating and in use.
Choice 1: Utilizing Pre-Configured Fashions
Ollama offers a library of pre-trained fashions you could obtain and run regionally. To begin utilizing a mannequin, obtain it utilizing the pull command. For instance, to make use of qwen2.5-coder:1.5b, run:
ollama pull qwen2.5-coder:1.5bThis can obtain the mannequin in your native surroundings. To verify if the mannequin has been downloaded, run:
ollama recordThis can record all of the fashions you’ve downloaded and saved regionally in your system utilizing Ollama.
Choice 2: Loading a Customized Mannequin
If the mannequin you want isn’t out there in Ollama’s library, you’ll be able to load a customized mannequin by making a Model File that specifies the mannequin’s supply.For detailed directions on this course of, confer with the Ollama Import Documentation.
Choice 3: Operating GGUF Fashions instantly from Hugging Face
Ollama now helps GGUF models directly from the Hugging Face Hub, together with each private and non-private fashions. This implies if you wish to use GGUF mannequin instantly from Hugging Face Hub you are able to do so with out requiring a customized Mannequin File as talked about in Choice 2 above.
For instance, to load a 4-bit quantized Qwen2.5-Coder-1.5B-Instruct mannequin from Hugging Face:
1. First, allow Ollama below your Local Apps settings.

2. On the mannequin web page, select Ollama from the Use this mannequin dropdown as proven under.

We’re nearly there. In JupyterLab, open the Jupyter AI chat interface on the sidebar. On the high of the chat panel or in its settings (gear icon), there’s a dropdown or area to pick out the Mannequin supplier and mannequin ID. Select Ollama because the supplier, and enter the mannequin title precisely as proven by Ollama record within the terminal (e.g. qwen2.5-coder:1.5b). Jupyter AI will hook up with the native Ollama server and cargo that mannequin for queries. No API keys are wanted since that is native.
- Set Language mannequin, Embedding mannequin and inline completions fashions based mostly on the fashions of your alternative.
- Save the settings and return to the chat interface.

This configuration hyperlinks Jupyter AI to the regionally operating mannequin by way of Ollama. Whereas inline completions ought to be enabled by this course of, if that doesn’t occur, you are able to do it manually by clicking on the Jupyternaut icon, which is positioned within the backside bar of the JupyterLab interface to the left of the Mode indicator (e.g., Mode: Command). This opens a dropdown menu the place you’ll be able to choose Allow completions by Jupyternaut to activate the characteristic.

As soon as arrange, you need to use the AI coding assistant for varied duties like code autocompletion, debugging assist, and producing new code from scratch. It’s necessary to notice right here you could work together with the assistant both via the chat sidebar or instantly in pocket book cells utilizing %%ai magic instructions. Let’s have a look at each the methods.
Coding assistant by way of Chat interface
That is fairly easy. You’ll be able to merely chat with the mannequin to carry out an motion. As an illustration, right here is how we will ask the mannequin to clarify the error within the code after which subsequently repair the error by choosing code within the pocket book.

You may as well ask the AI to generate code for a activity from scratch, simply by describing what you want in pure language. Here’s a Python perform that returns all prime numbers as much as a given optimistic integer N, generated by Jupyternaut.

Coding assistant by way of pocket book cell or IPython shell:
You may as well work together with fashions instantly inside a Jupyter pocket book. First, load the IPython extension:
%load_ext jupyter_ai_magicsNow, you need to use the %%ai cell magic to work together along with your chosen language mannequin utilizing a specified immediate. Let’s replicate the above instance however this time inside the pocket book cells.

For extra particulars and choices you’ll be able to confer with the official documentation.
As you’ll be able to gauge from this text, Jupyter AI makes it straightforward to arrange a coding assistant, supplied you’ve the suitable installations and setup in place. I used a comparatively small mannequin, however you’ll be able to select from a wide range of fashions supported by Ollama or Hugging Face. The important thing benefit right here is that utilizing an area mannequin affords important advantages: it enhances privateness, reduces latency, and reduces dependence on proprietary mannequin suppliers. Nonetheless, operating large fashions regionally with Ollama may be resource-intensive so guarantee that you’ve ample RAM. With the fast tempo at which open-source fashions are bettering, you’ll be able to obtain comparable efficiency even with these alternate options.






