Combine generative AI capabilities into Microsoft Workplace utilizing Amazon Bedrock
Generative AI is quickly reworking the fashionable office, providing unprecedented capabilities that increase how we work together with textual content and information. At Amazon Net Providers (AWS), we acknowledge that lots of our prospects depend on the acquainted Microsoft Workplace suite of purposes, together with Phrase, Excel, and Outlook, because the spine of their day by day workflows. On this weblog put up, we showcase a strong answer that seamlessly integrates AWS generative AI capabilities within the type of giant language fashions (LLMs) primarily based on Amazon Bedrock into the Workplace expertise. By harnessing the most recent developments in generative AI, we empower workers to unlock new ranges of effectivity and creativity throughout the instruments they already use day by day. Whether or not it’s drafting compelling textual content, analyzing complicated datasets, or gaining extra in-depth insights from data, integrating generative AI with Workplace suite transforms the best way groups strategy their important work. Be part of us as we discover how your group can leverage this transformative know-how to drive innovation and increase worker productiveness.
Answer overview

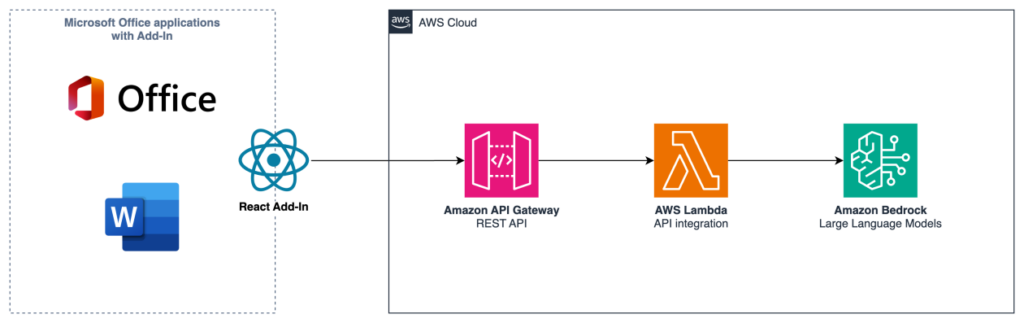
Determine 1: Answer structure overview
The answer structure in Determine 1 reveals how Workplace purposes work together with a serverless backend hosted on the AWS Cloud by an Add-In. This structure permits customers to leverage Amazon Bedrock’s generative AI capabilities straight from throughout the Workplace suite, enabling enhanced productiveness and insights inside their current workflows.
Parts deep-dive
Workplace Add-ins
Office Add-ins enable extending Workplace merchandise with customized extensions constructed on commonplace net applied sciences. Utilizing AWS, organizations can host and serve Workplace Add-ins for customers worldwide with minimal infrastructure overhead.
An Workplace Add-in consists of two parts:
The code snippet beneath demonstrates a part of a operate that might run each time a person invokes the plugin, performing the next actions:
- Provoke a request to the generative AI backend, offering the person immediate and obtainable context within the request physique
- Combine the outcomes from the backend response into the Phrase doc utilizing Microsoft’s Office JavaScript APIs. Observe that these APIs use objects as namespaces, assuaging the necessity for express imports. As an alternative, we use the globally obtainable namespaces, akin to
Phrase, to straight entry related APIs, as proven in following instance snippet.
Generative AI backend infrastructure
The AWS Cloud backend consists of three parts:
- Amazon API Gateway acts as an entry level, receiving requests from the Workplace purposes’ Add-in. API Gateway helps multiple mechanisms for controlling and managing access to an API.
- AWS Lambda handles the REST API integration, processing the requests and invoking the suitable AWS providers.
- Amazon Bedrock is a completely managed service that makes basis fashions (FMs) from main AI startups and Amazon obtainable through an API, so you possibly can select from a variety of FMs to search out the mannequin that’s finest suited in your use case. With Bedrock’s serverless expertise, you will get began rapidly, privately customise FMs with your personal information, and rapidly combine and deploy them into your purposes utilizing the AWS instruments with out having to handle infrastructure.
LLM prompting
Amazon Bedrock means that you can select from a wide selection of foundation models for prompting. Right here, we use Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock for completions. The system immediate we used on this instance is as follows:
You're an workplace assistant serving to people to put in writing textual content for his or her paperwork.
[When preparing the answer, take into account the following text: <text>{context}</text>]
Earlier than answering the query, assume by it step-by-step throughout the <pondering></pondering> tags.
Then, detect the person's language from their query and retailer it within the type of an ISO 639-1 code throughout the <user_language></user_language> tags.
Then, develop your reply within the person’s language throughout the <response></response> tags.
Within the immediate, we first give the LLM a persona, indicating that it’s an workplace assistant serving to people. The second, non-obligatory line comprises textual content that has been chosen by the person within the doc and is offered as context to the LLM. We particularly instruct the LLM to first mimic a step-by-step thought course of for arriving on the reply (chain-of-thought reasoning), an efficient measure of prompt-engineering to enhance the output high quality. Subsequent, we instruct it to detect the person’s language from their query so we are able to later discuss with it. Lastly, we instruct the LLM to develop its reply utilizing the beforehand detected person language inside response tags, that are used as the ultimate response. Whereas right here, we use the default configuration for inference parameters akin to temperature, that may rapidly be configured with each LLM immediate. The person enter is then added as a person message to the immediate and despatched through the Amazon Bedrock Messages API to the LLM.
Implementation particulars and demo setup in an AWS account
As a prerequisite, we have to be sure that we’re working in an AWS Area with Amazon Bedrock support for the foundation model (right here, we use Anthropic’s Claude 3.5 Sonnet). Additionally, access to the required relevant Amazon Bedrock foundation models must be added. For this demo setup, we describe the guide steps taken within the AWS console. If required, this setup will also be outlined in Infrastructure as Code.
To arrange the mixing, observe these steps:
- Create an AWS Lambda operate with Python runtime and beneath code to be the backend for the API. Guarantee that we’ve got Powertools for AWS Lambda (Python) obtainable in our runtime, for instance, by attaching aLambda layer to our operate. Guarantee that the Lambda operate’s IAM function offers entry to the required FM, for instance:
The next code block reveals a pattern implementation for the REST API Lambda integration primarily based on a Powertools for AWS Lambda (Python) REST API event handler:
- Create an API Gateway REST API with a Lambda proxy integration to reveal the Lambda operate through a REST API. You may observe this tutorial for making a REST API for the Lambda operate by utilizing the API Gateway console. By making a Lambda proxy integration with a proxy resource, we are able to route requests to the sources to the Lambda operate. Observe the tutorial to deploy the API and be aware of the API’s invoke URL. Make certain to configure satisfactory access control for the REST API.
We are able to now invoke and test our function through the API’s invoke URL. The next instance makes use of curl to ship a request (be certain that to exchange all placeholders in curly braces as required), and the response generated by the LLM:
If required, the created sources will be cleaned up by 1) deleting the API Gateway REST API, and a pair of) deleting the REST API Lambda operate and related IAM function.
Instance use circumstances
To create an interactive expertise, the Workplace Add-in integrates with the cloud back-end that implements conversational capabilities with help for added context retrieved from the Office JavaScript API.
Subsequent, we display two completely different use circumstances supported by the proposed answer, textual content technology and textual content refinement.
Textual content technology

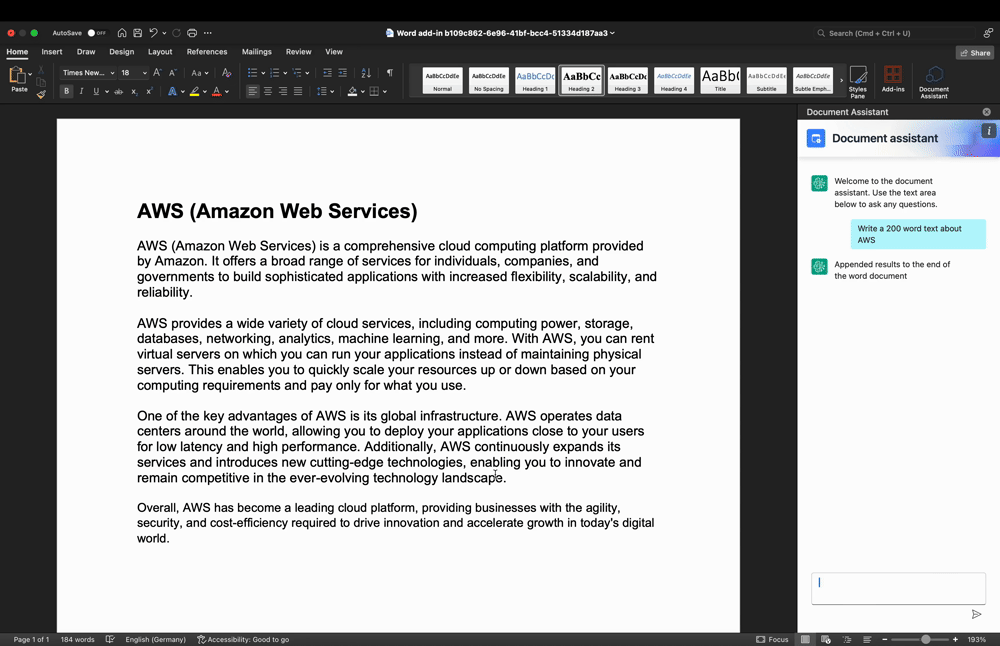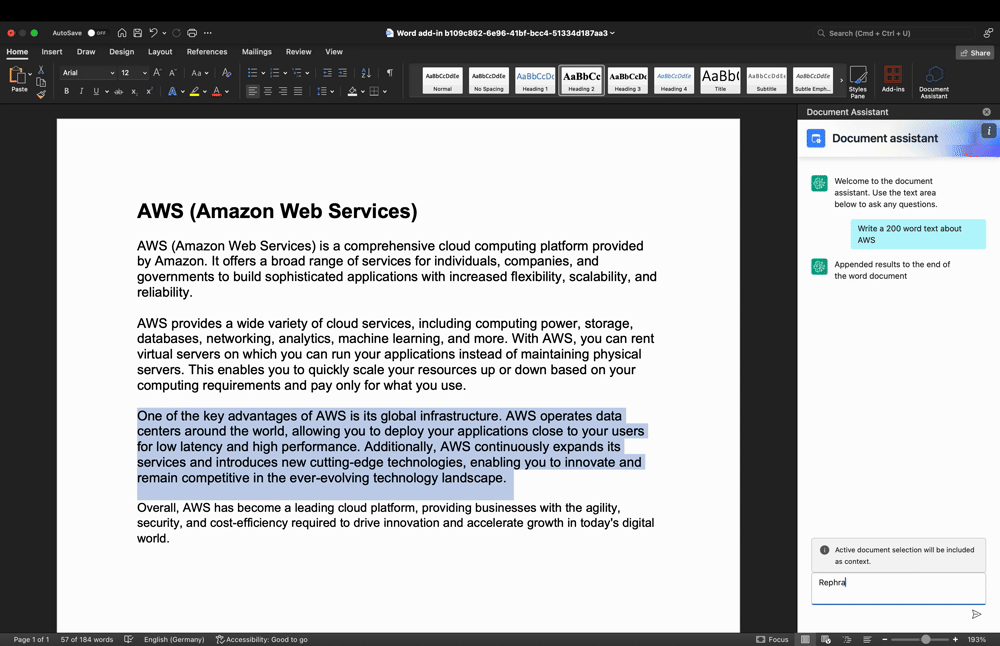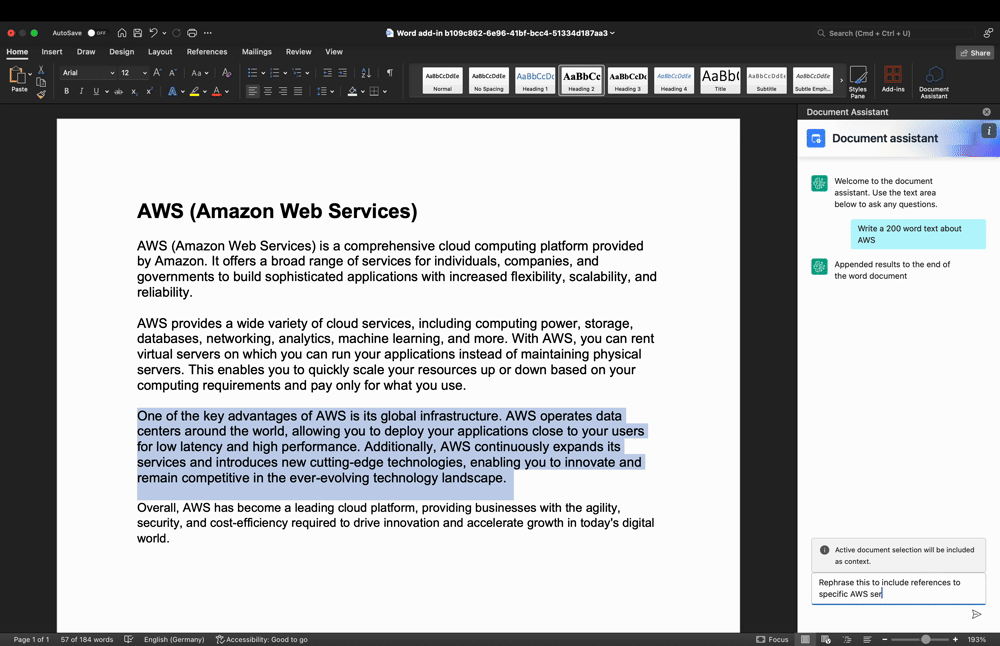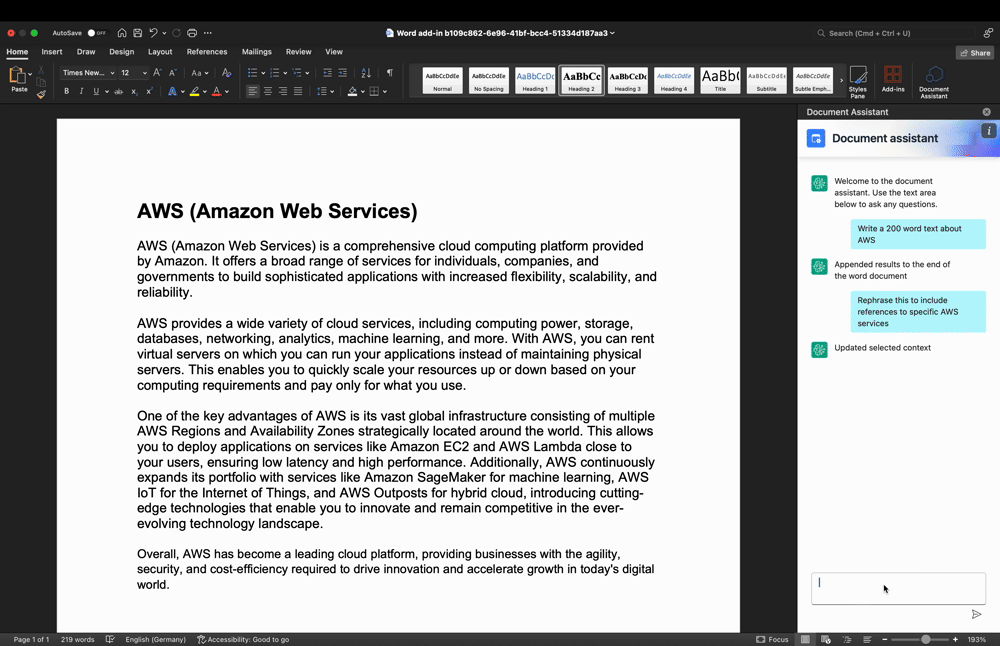
Determine 2: Textual content technology use-case demo
Within the demo in Determine 2, we present how the plug-in is prompting the LLM to supply a textual content from scratch. The person enters their question with some context into the Add-In textual content enter space. Upon sending, the backend will immediate the LLM to generate respective textual content, and return it again to the frontend. From the Add-in, it’s inserted into the Phrase doc on the cursor place utilizing the Workplace JavaScript API.
Textual content refinement
Determine 3: Textual content refinement use-case demo
In Determine 3, the person highlighted a textual content phase within the work space and entered a immediate into the Add-In textual content enter space to rephrase the textual content phase. Once more, the person enter and highlighted textual content are processed by the backend and returned to the Add-In, thereby changing the beforehand highlighted textual content.
Conclusion
This weblog put up showcases how the transformative energy of generative AI will be integrated into Workplace processes. We described an end-to-end pattern of integrating Workplace merchandise with an Add-in for textual content technology and manipulation with the ability of LLMs. In our instance, we used managed LLMs on Amazon Bedrock for textual content technology. The backend is hosted as a completely serverless utility on the AWS cloud.
Textual content technology with LLMs in Workplace helps workers by streamlining their writing course of and boosting productiveness. Workers can leverage the ability of generative AI to generate and edit high-quality content material rapidly, liberating up time for different duties. Moreover, the mixing with a well-recognized device like Phrase offers a seamless person expertise, minimizing disruptions to current workflows.
To be taught extra about boosting productiveness, constructing differentiated experiences, and innovating quicker with AWS go to the Generative AI on AWS web page.
In regards to the Authors
 Martin Maritsch is a Generative AI Architect at AWS ProServe specializing in Generative AI and MLOps. He helps enterprise prospects to realize enterprise outcomes by unlocking the complete potential of AI/ML providers on the AWS Cloud.
Martin Maritsch is a Generative AI Architect at AWS ProServe specializing in Generative AI and MLOps. He helps enterprise prospects to realize enterprise outcomes by unlocking the complete potential of AI/ML providers on the AWS Cloud.
 Miguel Pestana is a Cloud Utility Architect within the AWS Skilled Providers group with over 4 years of expertise within the automotive trade delivering cloud native options. Outdoors of labor Miguel enjoys spending its days on the seashore or with a padel racket in a single hand and a glass of sangria on the opposite.
Miguel Pestana is a Cloud Utility Architect within the AWS Skilled Providers group with over 4 years of expertise within the automotive trade delivering cloud native options. Outdoors of labor Miguel enjoys spending its days on the seashore or with a padel racket in a single hand and a glass of sangria on the opposite.
 Carlos Antonio Perea Gomez is a Builder with AWS Skilled Providers. He allows prospects to change into AWSome throughout their journey to the cloud. When not up within the cloud he enjoys scuba diving deep within the waters.
Carlos Antonio Perea Gomez is a Builder with AWS Skilled Providers. He allows prospects to change into AWSome throughout their journey to the cloud. When not up within the cloud he enjoys scuba diving deep within the waters.





