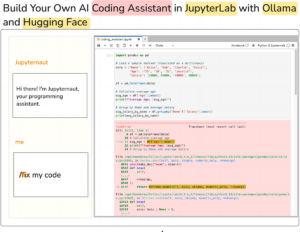
A Coding Implementation to Construct a Doc Search Agent (DocSearchAgent) with Hugging Face, ChromaDB, and Langchain

In at the moment’s information-rich world, discovering related paperwork shortly is essential. Conventional keyword-based search techniques usually fall brief when coping with semantic that means. This tutorial demonstrates learn how to construct a strong doc search engine utilizing:
- Hugging Face’s embedding fashions to transform textual content into wealthy vector representations
- Chroma DB as our vector database for environment friendly similarity search
- Sentence transformers for high-quality textual content embeddings
This implementation allows semantic search capabilities – discovering paperwork primarily based on that means somewhat than simply key phrase matching. By the top of this tutorial, you’ll have a working doc search engine that may:
- Course of and embed textual content paperwork
- Retailer these embeddings effectively
- Retrieve essentially the most semantically comparable paperwork to any question
- Deal with quite a lot of doc sorts and search wants
Please observe the detailed steps talked about under in sequence to implement DocSearchAgent.
First, we have to set up the required libraries.
!pip set up chromadb sentence-transformers langchain datasetsLet’s begin by importing the libraries we’ll use:
import os
import numpy as np
import pandas as pd
from datasets import load_dataset
import chromadb
from chromadb.utils import embedding_functions
from sentence_transformers import SentenceTransformer
from langchain.text_splitter import RecursiveCharacterTextSplitter
import timeFor this tutorial, we’ll use a subset of Wikipedia articles from the Hugging Face datasets library. This offers us a various set of paperwork to work with.
dataset = load_dataset("wikipedia", "20220301.en", cut up="prepare[:1000]")
print(f"Loaded {len(dataset)} Wikipedia articles")
paperwork = []
for i, article in enumerate(dataset):
doc = {
"id": f"doc_{i}",
"title": article["title"],
"textual content": article["text"],
"url": article["url"]
}
paperwork.append(doc)
df = pd.DataFrame(paperwork)
df.head(3)Now, let’s cut up our paperwork into smaller chunks for extra granular looking out:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
chunks = []
chunk_ids = []
chunk_sources = []
for i, doc in enumerate(paperwork):
doc_chunks = text_splitter.split_text(doc["text"])
chunks.lengthen(doc_chunks)
chunk_ids.lengthen([f"chunk_{i}_{j}" for j in range(len(doc_chunks))])
chunk_sources.lengthen([doc["title"]] * len(doc_chunks))
print(f"Created {len(chunks)} chunks from {len(paperwork)} paperwork")We’ll use a pre-trained sentence transformer mannequin from Hugging Face to create our embeddings:
model_name = "sentence-transformers/all-MiniLM-L6-v2"
embedding_model = SentenceTransformer(model_name)
sample_text = "It is a pattern textual content to check our embedding mannequin."
sample_embedding = embedding_model.encode(sample_text)
print(f"Embedding dimension: {len(sample_embedding)}")Now, let’s arrange Chroma DB, a light-weight vector database good for our search engine:
chroma_client = chromadb.Consumer()
embedding_function = embedding_functions.SentenceTransformerEmbeddingFunction(model_name=model_name)
assortment = chroma_client.create_collection(
title="document_search",
embedding_function=embedding_function
)
batch_size = 100
for i in vary(0, len(chunks), batch_size):
end_idx = min(i + batch_size, len(chunks))
batch_ids = chunk_ids[i:end_idx]
batch_chunks = chunks[i:end_idx]
batch_sources = chunk_sources[i:end_idx]
assortment.add(
ids=batch_ids,
paperwork=batch_chunks,
metadatas=[{"source": source} for source in batch_sources]
)
print(f"Added batch {i//batch_size + 1}/{(len(chunks)-1)//batch_size + 1} to the gathering")
print(f"Complete paperwork in assortment: {assortment.depend()}")Now comes the thrilling half – looking out via our paperwork:
def search_documents(question, n_results=5):
"""
Seek for paperwork just like the question.
Args:
question (str): The search question
n_results (int): Variety of outcomes to return
Returns:
dict: Search outcomes
"""
start_time = time.time()
outcomes = assortment.question(
query_texts=[query],
n_results=n_results
)
end_time = time.time()
search_time = end_time - start_time
print(f"Search accomplished in {search_time:.4f} seconds")
return outcomes
queries = [
"What are the effects of climate change?",
"History of artificial intelligence",
"Space exploration missions"
]
for question in queries:
print(f"nQuery: {question}")
outcomes = search_documents(question)
for i, (doc, metadata) in enumerate(zip(outcomes['documents'][0], outcomes['metadatas'][0])):
print(f"nResult {i+1} from {metadata['source']}:")
print(f"{doc[:200]}...") Let’s create a easy operate to offer a greater consumer expertise:
def interactive_search():
"""
Interactive search interface for the doc search engine.
"""
whereas True:
question = enter("nEnter your search question (or 'give up' to exit): ")
if question.decrease() == 'give up':
print("Exiting search interface...")
break
n_results = int(enter("What number of outcomes would you want? "))
outcomes = search_documents(question, n_results)
print(f"nFound {len(outcomes['documents'][0])} outcomes for '{question}':")
for i, (doc, metadata, distance) in enumerate(zip(
outcomes['documents'][0],
outcomes['metadatas'][0],
outcomes['distances'][0]
)):
relevance = 1 - distance
print(f"n--- Outcome {i+1} ---")
print(f"Supply: {metadata['source']}")
print(f"Relevance: {relevance:.2f}")
print(f"Excerpt: {doc[:300]}...")
print("-" * 50)
interactive_search()
Let’s add the power to filter our search outcomes by metadata:
def filtered_search(question, filter_source=None, n_results=5):
"""
Search with non-compulsory filtering by supply.
Args:
question (str): The search question
filter_source (str): Elective supply to filter by
n_results (int): Variety of outcomes to return
Returns:
dict: Search outcomes
"""
where_clause = {"supply": filter_source} if filter_source else None
outcomes = assortment.question(
query_texts=[query],
n_results=n_results,
the place=where_clause
)
return outcomes
unique_sources = listing(set(chunk_sources))
print(f"Out there sources for filtering: {len(unique_sources)}")
print(unique_sources[:5])
if len(unique_sources) > 0:
filter_source = unique_sources[0]
question = "essential ideas and rules"
print(f"nFiltered seek for '{question}' in supply '{filter_source}':")
outcomes = filtered_search(question, filter_source=filter_source)
for i, doc in enumerate(outcomes['documents'][0]):
print(f"nResult {i+1}:")
print(f"{doc[:200]}...") In conclusion, we show learn how to construct a semantic doc search engine utilizing Hugging Face embedding fashions and ChromaDB. The system retrieves paperwork primarily based on that means somewhat than simply key phrases by remodeling textual content into vector representations. The implementation processes Wikipedia articles chunks them for granularity, embeds them utilizing sentence transformers, and shops them in a vector database for environment friendly retrieval. The ultimate product options interactive looking out, metadata filtering, and relevance rating.
Right here is the Colab Notebook. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 80k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.