How IDIADA optimized its clever chatbot with Amazon Bedrock
This submit is co-written with Xavier Vizcaino, Diego Martín Montoro, and Jordi Sánchez Ferrer from Applus+ Idiada.
In 2021, Applus+ IDIADA, a worldwide associate to the automotive business with over 30 years of expertise supporting prospects in product improvement actions by design, engineering, testing, and homologation providers, established the Digital Options division. This strategic transfer aimed to drive innovation by utilizing digital instruments and processes. Since then, we have now optimized knowledge methods, developed personalized options for patrons, and ready for the technological revolution reshaping the business.
AI now performs a pivotal function within the improvement and evolution of the automotive sector, by which Applus+ IDIADA operates. Inside this panorama, we developed an clever chatbot, AIDA (Applus Idiada Digital Assistant)— an Amazon Bedrock powered digital assistant serving as a flexible companion to IDIADA’s workforce.
Amazon Bedrock is a totally managed service that provides a alternative of high-performing basis fashions (FMs) from main AI firms like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon by a single API, together with a broad set of capabilities to construct generative AI purposes with safety, privateness, and accountable AI.
With Amazon Bedrock, AIDA assists with a mess of duties, from addressing inquiries to tackling complicated technical challenges spanning code, arithmetic, and translation. Its capabilities are really boundless.
With AIDA, we take one other step in direction of our imaginative and prescient of offering international and built-in digital options that add worth for our prospects. Its inner deployment strengthens our management in creating knowledge evaluation, homologation, and automobile engineering options. Moreover, within the medium time period, IDIADA plans to supply AIDA as an integrable product for patrons’ environments and develop “gentle” variations seamlessly integrable into present methods.
On this submit, we showcase the analysis course of undertaken to develop a classifier for human interactions on this AI-based atmosphere utilizing Amazon Bedrock. The target was to precisely determine the kind of interplay obtained by the clever agent to route the request to the suitable pipeline, offering a extra specialised and environment friendly service.
The problem: Optimize clever chatbot responses, allocate sources extra successfully, and improve the general person expertise
Constructed on a versatile and safe structure, AIDA affords a flexible atmosphere for integrating a number of knowledge sources, together with structured knowledge from enterprise databases and unstructured knowledge from inner sources like Amazon Simple Storage Service (Amazon S3). It boasts superior capabilities like chat with knowledge, superior Retrieval Augmented Technology (RAG), and brokers, enabling complicated duties comparable to reasoning, code execution, or API calls.
As AIDA’s interactions with people proliferated, a urgent want emerged to ascertain a coherent system for categorizing these various exchanges.
Initially, customers have been making easy queries to AIDA, however over time, they began to request extra particular and sophisticated duties. These included doc translations, inquiries about IDIADA’s inner providers, file uploads, and different specialised requests.
The principle motive for this categorization was to develop distinct pipelines that would extra successfully tackle varied forms of requests. By sorting interactions into classes, AIDA could possibly be optimized to deal with particular sorts of duties extra effectively. This strategy permits for tailor-made responses and processes for several types of person wants, whether or not it’s a easy query, a doc translation, or a posh inquiry about IDIADA’s providers.
The first goal is to supply a extra specialised service by the creation of devoted pipelines for varied contexts, comparable to dialog, doc translation, and providers to supply extra correct, related, and environment friendly responses to customers’ more and more various and specialised requests.
Answer overview
By categorizing the interactions into three major teams—dialog, providers, and doc translation—the system can higher perceive the person’s intent and reply accordingly. The Dialog class encompasses common inquiries and exchanges, the Providers class covers requests for particular functionalities or help, and the Document_Translation class handles textual content translation wants.
The specialised pipelines, designed particularly for every use case, permit for a major enhance in effectivity and accuracy of AIDA’s responses. That is achieved in a number of methods:
- Enhanced effectivity – By having devoted pipelines for particular forms of duties, AIDA can course of requests extra shortly. Every pipeline is optimized for its explicit use case, which reduces the computation time wanted to generate an applicable response.
- Elevated accuracy – The specialised pipelines are outfitted with particular instruments and data for every kind of activity. This enables AIDA to supply extra correct and related responses, as a result of it makes use of probably the most applicable sources for every kind of request.
- Optimized useful resource allocation – By classifying interactions, AIDA can allocate computational sources extra effectively, directing the suitable processing energy to every kind of activity.
- Improved response time – The mixture of higher effectivity and optimized useful resource allocation ends in sooner response occasions for customers.
- Enhanced adaptability – This technique permits AIDA to raised adapt to several types of requests, from easy queries to complicated duties comparable to doc translations or specialised inquiries about IDIADA providers.
The analysis and improvement of this huge language mannequin (LLM) primarily based classifier is a crucial step within the steady enchancment of the clever agent’s capabilities throughout the Applus IDIADA atmosphere.
For this event, we use a set of 1,668 examples of pre-classified human interactions. These have been divided into 666 for coaching and 1,002 for testing. A 40/60 cut up has been utilized, giving vital significance to the take a look at set.
The next desk reveals some examples.
| SAMPLE | CLASS |
| Are you able to make a abstract of this textual content? “Laws for the Australian Authorities’s …” | Dialog |
| No, solely concentrate on this sentence : Braking approach to allow most brake software velocity | Dialog |
| In a manufacturing facility give me synonyms of a limiting useful resource of actions | Dialog |
| We want a translation of the file “Company_Bylaws.pdf” into English, might you deal with it? | Document_Translation |
| Please translate the file “Product_Manual.xlsx” into English | Document_Translation |
| May you change the doc “Data_Privacy_Policy.doc’ into English, please? | Document_Translation |
| Register my username within the IDIADA’s human sources database | Providers |
| Ship a mail to random_user@mail.com to schedule a gathering for the subsequent weekend | Providers |
| E-book an electrical automotive charger for me at IDIADA | Providers |
We current three totally different classification approaches: two primarily based on LLMs and one utilizing a traditional machine studying (ML) algorithm. The goal is to grasp which strategy is best suited for addressing the offered problem.
LLM-based classifier: Easy immediate
On this case, we developed an LLM-based classifier to categorize inputs into three lessons: Dialog, Providers, and Document_Translation. As a substitute of counting on predefined, inflexible definitions, our strategy follows the precept of understanding a set. This precept includes analyzing the frequent traits and patterns current within the examples or situations that belong to every class. By finding out the shared traits of inputs inside a category, we are able to derive an understanding of the category itself, with out being constrained by preconceived notions.
It’s necessary to notice that the discovered definitions would possibly differ from frequent expectations. For example, the Dialog class encompasses not solely typical conversational exchanges but in addition duties like textual content summarization, which share comparable linguistic and contextual traits with conversational inputs.
By following this data-driven strategy, the classifier can precisely categorize new inputs primarily based on their similarity to the discovered traits of every class, capturing the nuances and variety inside every class.
The code consists of the next key parts: libraries, a immediate, mannequin invocation, and an output parser.
Libraries
The programming language used on this code is Python, complemented by the LangChain module, which is particularly designed to facilitate the combination and use of LLMs. This module gives a complete set of instruments and abstractions that streamline the method of incorporating and deploying these superior AI fashions.
To reap the benefits of the ability of those language fashions, we use Amazon Bedrock. The combination with Amazon Bedrock is achieved by the Boto3 Python module, which serves as an interface to the AWS, enabling seamless interplay with Amazon Bedrock and the deployment of the classification mannequin.
Immediate
The duty is to assign one in every of three lessons (Dialog, Providers, or Document_Translation) to a given sentence, represented by query:
- Dialog class – This class encompasses informal messages, summarization requests, common questions, affirmations, greetings, and comparable forms of textual content. It additionally contains requests for textual content translation, summarization, or specific inquiries in regards to the which means of phrases or sentences in a selected language.
- Providers class – Texts belonging to this class encompass specific requests for providers comparable to room reservations, resort bookings, eating providers, cinema data, tourism-related inquiries, and comparable service-oriented requests.
- Document_Translation class – This class is characterised by requests for the interpretation of a doc to a selected language. In contrast to the
Dialogclass, these requests don’t contain summarization. Moreover, the identify of the doc to be translated and the goal language are specified.
The immediate suggests a hierarchical strategy to the classification course of. First, the sentence needs to be evaluated to find out if it may be labeled as a dialog. If the sentence doesn’t match the Dialog class, one of many different two lessons (Providers or Document_Translation) needs to be assigned.
The precedence for the Dialog class stems from the truth that 99% of the interactions are literally easy questions relating to varied issues.
Mannequin invocation
We use Anthropic’s Claude 3 Sonnet mannequin for the pure language processing activity. This LLM mannequin has a context window of 200,000 tokens, enabling it to handle totally different languages and retrieve extremely correct solutions. We use two key parameters:
- max_tokens – This parameter limits the utmost variety of tokens (phrases or subwords) that the language mannequin can generate in its output to 50.
- temperature – This parameter controls the randomness of the language mannequin’s output. A temperature of 0.0 signifies that the mannequin will produce the most definitely output in line with its coaching, with out introducing randomness.
Output parser
One other necessary element is the output parser, which permits us to collect the specified data in JSON format. To realize this, we use the LangChain parameter output_parsers.
The next code illustrates a easy immediate strategy:
LLM-based classifier: Instance augmented inference
We use RAG strategies to reinforce the mannequin’s response capabilities. As a substitute of relying solely on compressed definitions, we offer the mannequin with a quasi-definition by extension. Particularly, we current the mannequin with a various set of examples for every class, permitting it to be taught the inherent traits and patterns that outline every class. For example, along with a concise definition of the Dialog class, the mannequin is uncovered to numerous conversational inputs, enabling it to determine frequent traits comparable to casual language, open-ended questions, and back-and-forth exchanges. This instance-driven strategy enhances the preliminary descriptions supplied, permitting the mannequin to seize the nuances and variety inside every class. By combining concise definitions with consultant examples, the RAG approach helps the mannequin develop a extra complete understanding of the lessons, enhancing its skill to precisely categorize new inputs primarily based on their inherent nature and traits.
The next code gives examples in JSON format for RAG:
The whole variety of examples supplied for every class is as follows:
- Dialog – 500 examples. That is the most typical class, and solely 500 samples are given to the mannequin because of the huge quantity of data, which might trigger infrastructure overflow (very excessive delays, throttling, connection shutouts). This can be a essential level to notice as a result of it represents a major bottleneck. Offering extra examples to this strategy might probably enhance efficiency, however the query stays: What number of examples? Certainly, a considerable quantity could be required.
- Providers – 26 examples. That is the least frequent class, and on this case, all accessible coaching knowledge has been used.
- Document_Translation – 140 examples. Once more, all accessible coaching knowledge has been used for this class.
One of many key challenges with this strategy is scalability. Though the mannequin’s efficiency improves with extra coaching examples, the computational calls for shortly develop into overwhelming for our present infrastructure. The sheer quantity of knowledge required can result in quota points with Amazon Bedrock and unacceptably lengthy response occasions. Fast response occasions are important for offering a passable person expertise, and this strategy falls brief in that regard.
On this case, we have to modify the code to embed all of the examples. The next code reveals the modifications utilized to the primary model of the classifier. The immediate is modified to incorporate all of the examples in JSON format below the “Right here you’ve got some examples” part.
Ok-NN-based classifier: Amazon Titan Embeddings
On this case, we take a special strategy by recognizing that regardless of the multitude of doable interactions, they typically share similarities and repetitive patterns. As a substitute of treating every enter as completely distinctive, we are able to use a distance-based strategy like k-nearest neighbors (k-NN) to assign a category primarily based on probably the most comparable examples surrounding the enter. To make this work, we have to remodel the textual interactions right into a format that enables algebraic operations. That is the place embeddings come into play. Embeddings are vector representations of textual content that seize semantic and contextual data. We are able to calculate the semantic similarity between totally different interactions by changing textual content into these vector representations and evaluating their vectors and figuring out their proximity within the embedding area.
To accommodate this strategy, we have to modify the code accordingly:
We used the Amazon Titan Textual content Embeddings G1 mannequin, which generates vectors of 1,536 dimensions. This mannequin is skilled to just accept a number of languages whereas retaining the semantic which means of the embedded phrases.
For the classfier, we employed a traditional ML algorithm, k-NN, utilizing the scikit-learn Python module. This methodology takes a parameter, which we set to three.
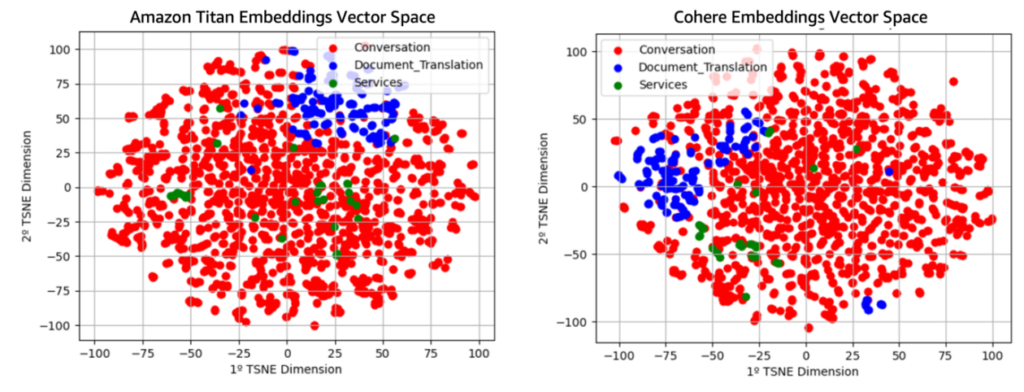
The next determine illustrates the F1 scores for every class plotted towards the variety of neighbors (okay) used within the k-NN algorithm. Because the graph reveals, the optimum worth for okay is 3, which yields the very best F1 rating for probably the most prevalent class, Document_Translation. Though it’s not absolutely the highest rating for the Providers class, Document_Translation is considerably extra frequent, making okay=3 the perfect total alternative to maximise efficiency throughout all lessons.
Ok-NN-based classifier: Cohere’s multilingual embeddings mannequin
Within the earlier part, we used the favored Amazon Titan Textual content Embeddings G1 mannequin to generate textual content embeddings. Nevertheless, different fashions would possibly provide totally different benefits. On this part, we discover the usage of Cohere’s multilingual mannequin on Amazon Bedrock for producing embeddings. We selected the Cohere mannequin attributable to its glorious functionality in dealing with a number of languages with out compromising the vectorization of phrases. As we are going to show, this mannequin doesn’t introduce vital variations within the generated vectors in comparison with different fashions, making it extra appropriate to be used in a multilingual atmosphere like AIDA.
To make use of the Cohere mannequin, we have to change the model_id:
We use Cohere’s multilingual embeddings mannequin to generate vectors with 1,024 dimensions. This mannequin is skilled to just accept a number of languages and retain the semantic which means of the embedded phrases.
For the classifier, we make use of k-NN, utilizing the scikit-learn Python module. This methodology takes a parameter, which we have now set to 11.
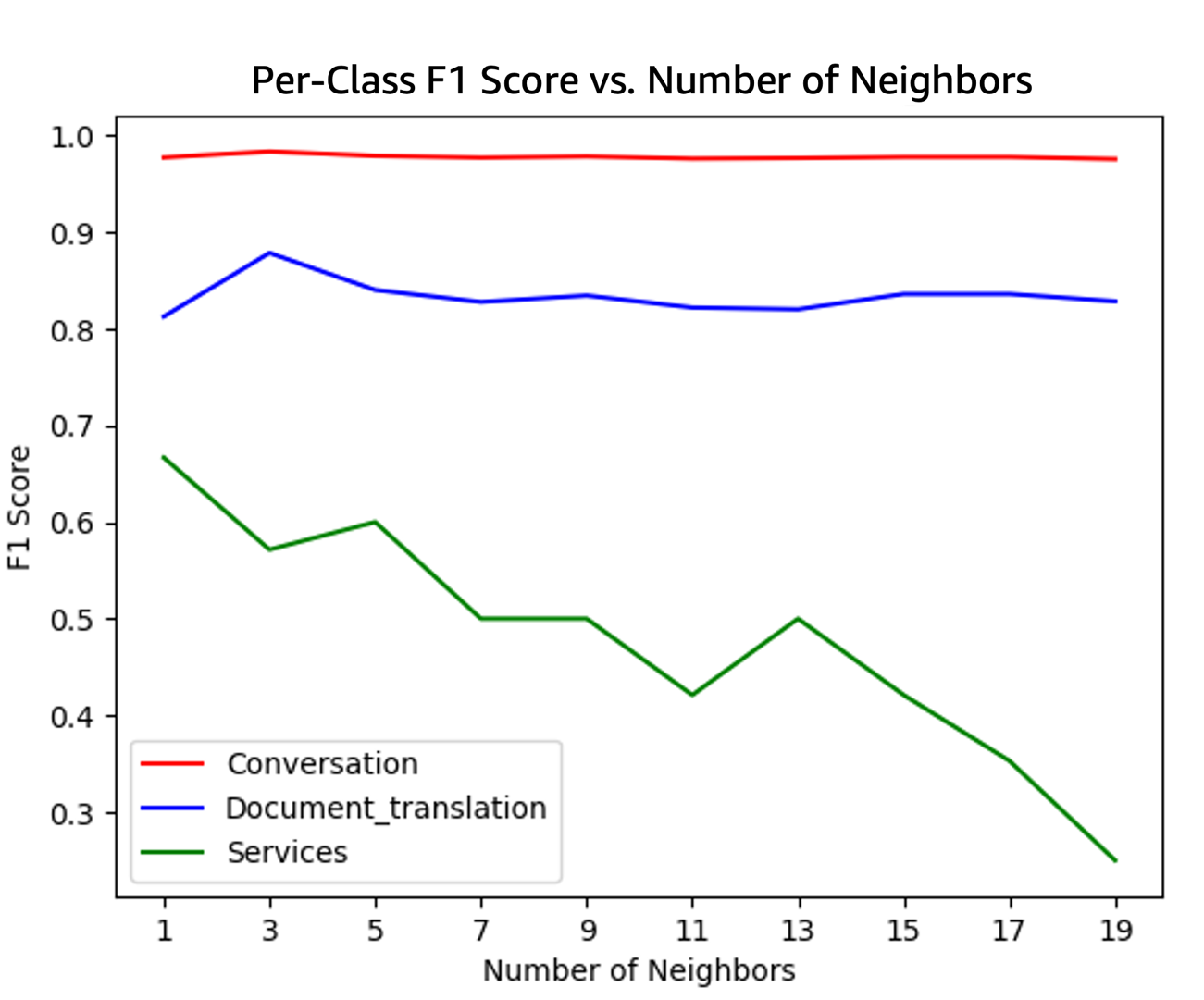
The next determine illustrates the F1 scores for every class plotted towards the variety of neighbors used. As depicted, the optimum level is okay=11, reaching the very best worth for Document_Translation and the second-highest for Providers. On this occasion, the trade-off between Documents_Translation and Providers is favorable.
Amazon Titan Embeddings vs. Cohere’s multilingual embeddings mannequin
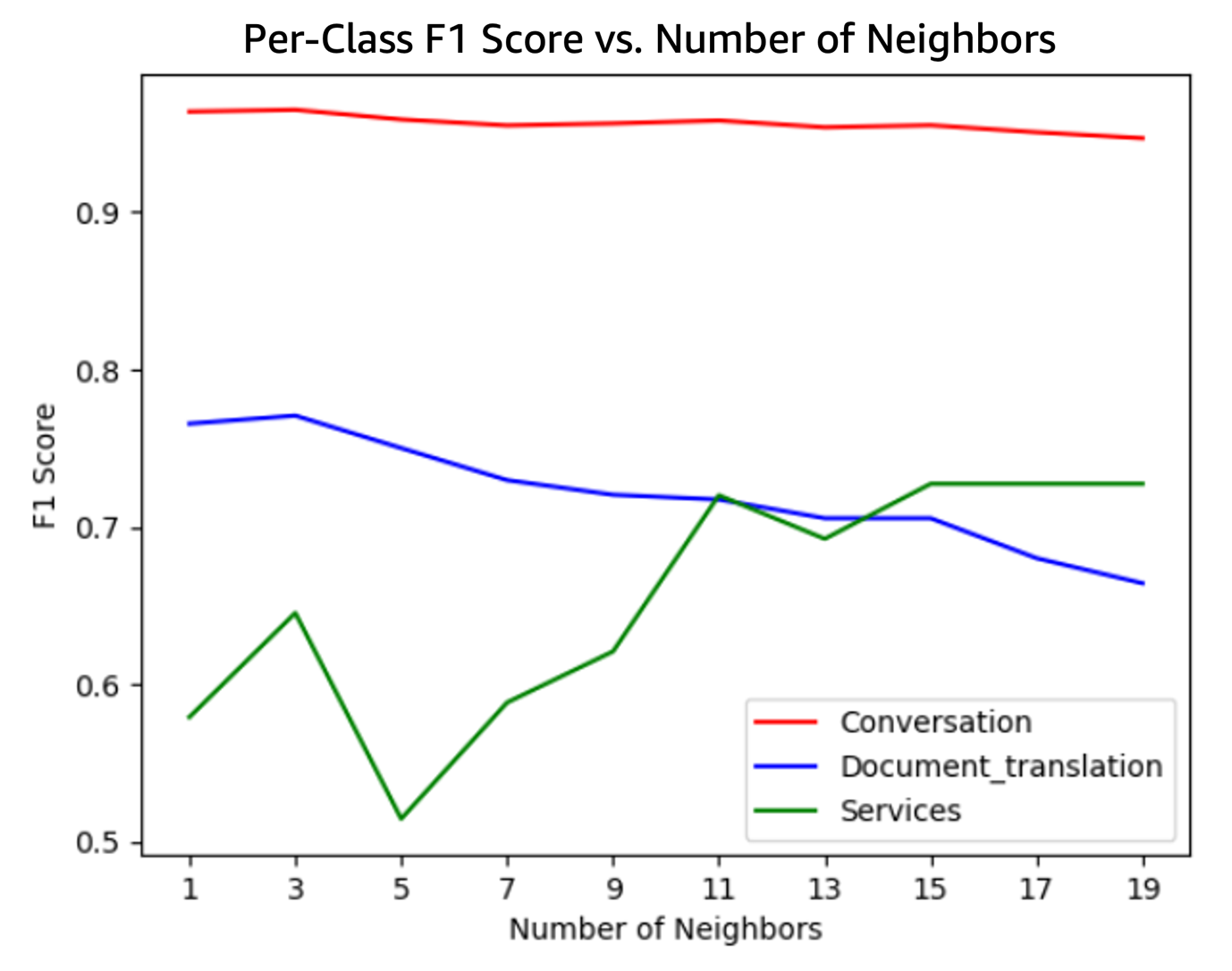
On this part, we delve deeper into the embeddings generated by each fashions, aiming to grasp their nature and consequently comprehend the outcomes obtained. To realize this, we have now carried out dimensionality discount to visualise the vectors obtained in each circumstances in 2D.
Cohere’s multilingual embeddings mannequin has a limitation on the scale of the textual content it may vectorize, posing a major constraint. Due to this fact, within the implementation showcased within the earlier part, we utilized a filter to solely embrace interactions as much as 1,500 characters (excluding circumstances that exceed this restrict).
The next determine illustrates the vector areas generated in every case.
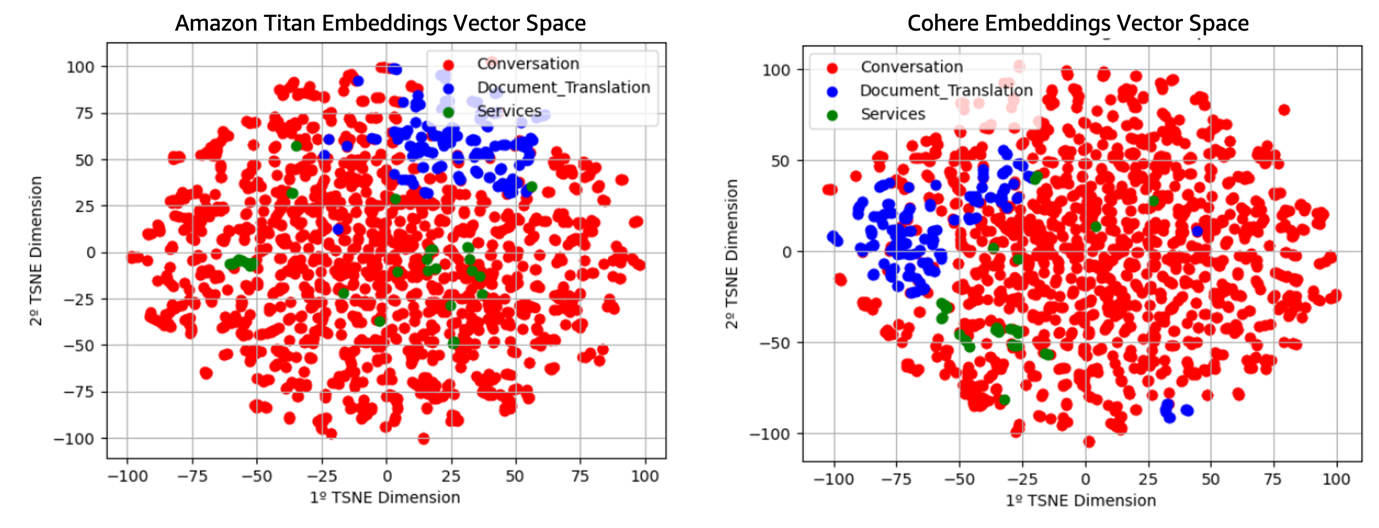
As we are able to observe, the generated vector areas are comparatively comparable, initially showing to be analogous areas with a rotation between each other. Nevertheless, upon nearer inspection, it turns into evident that the route of most variance within the case of Cohere’s multilingual embeddings mannequin is distinct (deducible from observing the relative place and form of the totally different teams). This sort of scenario, the place excessive class overlap is noticed, presents a perfect case for making use of algorithms comparable to k-NN.
As talked about within the introduction, most human interactions with AI are similar to one another throughout the identical class. This might clarify why k-NN-based fashions outperform LLM-based fashions.
SVM-based classifier: Amazon Titan Embeddings
On this situation, it’s doubtless that person interactions belonging to the three major classes (Dialog, Providers, and Document_Translation) type distinct clusters or teams throughout the embedding area. Every class possesses explicit linguistic and semantic traits that will be mirrored within the geometric construction of the embedding vectors. The earlier visualization of the embeddings area displayed solely a 2D transformation of this area. This doesn’t suggest that clusters coudn’t be extremely separable in increased dimensions.
Classification algorithms like help vector machines (SVMs) are particularly well-suited to make use of this implicit geometry of the info. SVMs search to search out the optimum hyperplane that separates the totally different teams or lessons within the embedding area, maximizing the margin between them. This skill of SVMs to make use of the underlying geometric construction of the info makes them an intriguing possibility for this person interplay classification downside.
Moreover, SVMs are a sturdy and environment friendly algorithm that may successfully deal with high-dimensional datasets, comparable to textual content embeddings. This makes them significantly appropriate for this situation, the place the embedding vectors of the person interactions are anticipated to have a excessive dimensionality.
The next code illustrates the implementation:
We use Amazon Titan Textual content Embeddings G1. This mannequin generates vectors of 1,536 dimensions, and is skilled to just accept a number of languages and to retain the semantic which means of the phrases embedded.
To implement the classifier, we employed a traditional ML algorithm, SVM, utilizing the scikit-learn Python module. The SVM algorithm requires the tuning of a number of parameters to realize optimum efficiency. To find out the perfect parameter values, we performed a grid search with 10-fold cross-validation, utilizing the F1 multi-class rating because the analysis metric. This systematic strategy allowed us to determine the next set of parameters that yielded the very best efficiency for our classifier:
- C – We set this parameter to 1. This parameter controls the trade-off between permitting coaching errors and forcing inflexible margins. It acts as a regularization parameter. The next worth of C (for instance, 10) signifies a better penalty for misclassification errors. This ends in a extra complicated mannequin that tries to suit the coaching knowledge extra carefully. The next C worth may be useful when the lessons within the knowledge are properly separated, as a result of it permits the algorithm to create a extra intricate choice boundary to precisely classify the samples. Alternatively, a C worth of 1 signifies an affordable stability between becoming the coaching set and the mannequin’s generalization skill. This worth is perhaps applicable when the info has a easy construction, and a extra versatile mannequin isn’t essential to seize the underlying relationships. In our case, the chosen C worth of 1 means that the info has a comparatively easy construction, and a balanced mannequin with average complexity is enough for correct classification.
- class_weight – We set this parameter to
None. This parameter adjusts the weights of every class in the course of the coaching course of. Settingclass_weighttobalancedmechanically adjusts the weights inversely proportional to the category frequencies within the enter knowledge. That is significantly helpful when coping with imbalanced datasets, the place one class is considerably extra prevalent than the others. In our case, the worth ofNonefor theclass_weightparameter means that the minor lessons don’t have a lot relevance or impression on the general classification activity. This alternative implies that the implicit geometry or choice boundaries discovered by the mannequin may not be optimized for separating the totally different lessons successfully. - Kernel – We set this parameter to
linear. This parameter specifies the kind of kernel perform for use by the SVC algorithm. Thelinearkernel is an easy and environment friendly alternative as a result of it assumes that the choice boundary between lessons may be represented by a linear hyperplane within the characteristic area. This worth means that, in a better dimension vector area, the classes could possibly be linearly separated by an hyperplane.
SVM-based classifier: Cohere’s multilingual embeddings mannequin
The implementation particulars of the classifier are offered within the following code:
We use the Amazon Titan Textual content Embeddings G1 mannequin, which generates vectors of 1,536 dimensions. This mannequin is skilled to just accept a number of languages and retain the semantic which means of the embedded phrases.
For the classifier, we make use of SVM, utilizing the scikit-learn Python module. To acquire the optimum parameters, we carried out a grid search with 10-fold cross-validation primarily based on the multi-class F1 rating, ensuing within the following chosen parameters (as detailed within the earlier part):
- C – We set this parameter to 1, which signifies an affordable stability between becoming the coaching set and the mannequin’s generalization skill. This setting means that the info has a easy construction and {that a} extra versatile mannequin may not be essential to seize the underlying relationships.
- class_weight – We set this parameter to
None. A price ofNonemeans that the minor lessons don’t have a lot relevance, which in flip implies that the implicit geometry may not be appropriate for separating the totally different lessons. - kernel – We set this parameter to
linear. This worth means that in a higher-dimensional vector area, the classes could possibly be linearly separated by a hyperplane.
ANN-based classifier: Amazon Titan and Cohere’s multilingual embeddings mannequin
Given the promising outcomes obtained with SVMs, we determined to discover one other geometry-based methodology by using an Synthetic Neural Community (ANN) strategy.
On this case, we carried out normalization of the enter vectors to make use of some great benefits of normalization when utilizing neural networks. Normalizing the enter knowledge is a vital step when working with ANNs, as a result of it may assist enhance the mannequin’s throughout coaching. We utilized min/max scaling for normalization.
The usage of an ANN-based strategy gives the flexibility to seize complicated non-linear relationships within the knowledge, which could not be simply modeled utilizing conventional linear strategies like SVMs. The mixture of the geometric insights and the normalization of inputs can probably result in improved predictive accuracy in comparison with the earlier SVM outcomes.
This strategy consists of the next parameters:
- Mannequin definition – We outline a sequential deep studying mannequin utilizing the Keras library from TensorFlow.
- Mannequin structure – The mannequin consists of three densely related layers. The primary layer has 16 neurons and makes use of the ReLU activation perform. The second layer has 8 neurons and employs the ReLU activation perform. The third layer has 3 neurons and makes use of the softmax activation perform.
- Mannequin compilation – We compile the mannequin utilizing the
categorical_crossentropyloss perform, the Adam optimizer with a studying fee of 0.01, and thecategorical_accuracy. We incorporate anEarlyStoppingcallback to cease the coaching if thecategorical_accuracymetric doesn’t enhance for 25 epochs. - Mannequin coaching – We practice the mannequin for a most of 500 epochs utilizing the coaching set and validate it on the take a look at set. The batch measurement is about to 64. The efficiency metric used is the utmost classification accuracy (
categorical_accuracy) obtained in the course of the coaching.
We utilized the identical methodology, however utilizing the embeddings generated by Cohere’s multilingual embeddings mannequin after being normalized by min/max scaling. In each circumstances, we employed the identical preprocessing steps:
To assist keep away from ordinal assumptions, we employed a one-hot encoding illustration for the output of the community. One-hot encoding doesn’t make any assumptions in regards to the inherent order or hierarchy among the many classes. That is significantly helpful when the specific variable doesn’t have a transparent ordinal relationship, as a result of the mannequin can be taught the relationships with out being biased by any assumed ordering.
The next code illustrates the implementation:
Outcomes
We performed a comparative evaluation utilizing the beforehand offered code and knowledge. The fashions have been assessed primarily based on their F1 scores for the dialog, providers, and doc translation duties, in addition to their runtimes. The next desk summarizes our outcomes.
| MODEL | CONVERSATION F1 | SERVICES F1 | DOCUMENT_ TRANSLATION F1 | RUNTIME (Seconds) |
| LLM | 0.81 | 0.22 | 0.46 | 1.2 |
| LLM with examples | 0.86 | 0.13 | 0.68 | 18 |
| KNN – Amazon Titan Embedding | 0.98 | 0.57 | 0.88 | 0.35 |
| KNN – Cohere Embedding | 0.96 | 0.72 | 0.72 | 0.35 |
| SVM Amazon Titan Embedding | 0.98 | 0.69 | 0.82 | 0.3 |
| SVM Cohere Embedding | 0.99 | 0.80 | 0.93 | 0.3 |
| ANN Amazon Titan Embedding | 0.98 | 0.60 | 0.87 | 0.15 |
| ANN Cohere Embedding | 0.99 | 0.77 | 0.96 | 0.15 |
As illustrated within the desk, the SVM and ANN fashions utilizing Cohere’s multilingual embeddings mannequin demonstrated the strongest total efficiency. The SVM with Cohere’s multilingual embeddings mannequin achieved the very best F1 scores in two out of three duties, reaching 0.99 for Dialog, 0.80 for Providers, and 0.93 for Document_Translation. Equally, the ANN with Cohere’s multilingual embeddings mannequin additionally carried out exceptionally properly, with F1 scores of 0.99, 0.77, and 0.96 for the respective duties.
In distinction, the LLM exhibited comparatively decrease F1 scores, significantly for the providers (0.22) and doc translation (0.46) duties. Nevertheless, the efficiency of the LLM improved when supplied with examples, with the F1 rating for doc translation growing from 0.46 to 0.68.
Relating to runtime, the k-NN, SVM, and ANN fashions demonstrated considerably sooner inference occasions in comparison with the LLM. The k-NN and SVM fashions with each Amazon Titan and Cohere’s multilingual embeddings mannequin had runtimes of roughly 0.3–0.35 seconds. The ANN fashions have been even sooner, with runtimes of roughly 0.15 seconds. In distinction, the LLM required roughly 1.2 seconds for inference, and the LLM with examples took round 18 seconds.
These outcomes recommend that the SVM and ANN fashions utilizing Cohere’s multilingual embeddings mannequin provide the perfect stability of efficiency and effectivity for the given duties. The superior F1 scores of those fashions, coupled with their sooner runtimes, make them promising candidates for software. The potential advantages of offering examples to the LLM mannequin are additionally noteworthy, as a result of this strategy can assist enhance its efficiency on particular duties.
Conclusion
The optimization of AIDA, Applus IDIADA’s clever chatbot powered by Amazon Bedrock, has been a convincing success. By creating devoted pipelines to deal with several types of person interactions—from common conversations to specialised service requests and doc translations—AIDA has considerably improved its effectivity, accuracy, and total person expertise. The modern use of LLMs, embeddings, and superior classification algorithms has allowed AIDA to adapt to the evolving wants of IDIADA’s workforce, offering a flexible and dependable digital assistant. AIDA now handles over 1,000 interactions per day, with a 95% accuracy fee in routing requests to the suitable pipeline and driving a 20% enhance of their staff’s productiveness.
Trying forward, IDIADA plans to supply AIDA as an built-in product for buyer environments, additional increasing the attain and impression of this transformative expertise.
Amazon Bedrock affords a complete strategy to safety, compliance, and accountable AI improvement that empowers IDIADA and different prospects to harness the complete potential of generative AI with out compromising on security and belief. As this superior expertise continues to quickly evolve, Amazon Bedrock gives the clear framework wanted to construct modern purposes that encourage confidence.
Unlock new development alternatives by creating customized, safe AI fashions tailor-made to your group’s distinctive wants. Take step one in your generative AI transformation—join with an AWS professional right now to start your journey.
In regards to the Authors
 Xavier Vizcaino is the pinnacle of the DataLab, within the Digital Options division of Applus IDIADA. DataLab is the unit centered on the event of options for producing worth from the exploitation of knowledge by synthetic intelligence.
Xavier Vizcaino is the pinnacle of the DataLab, within the Digital Options division of Applus IDIADA. DataLab is the unit centered on the event of options for producing worth from the exploitation of knowledge by synthetic intelligence.
 Diego Martín Montoro is an AI Skilled and Machine Studying Engineer at Applus+ Idiada Datalab. With a Laptop Science diploma and a Grasp’s in Knowledge Science, Diego has constructed his profession within the area of synthetic intelligence and machine studying. His expertise contains roles as a Machine Studying Engineer at firms like AppliedIT and Applus+ IDIADA, the place he has labored on creating superior AI methods and anomaly detection options.
Diego Martín Montoro is an AI Skilled and Machine Studying Engineer at Applus+ Idiada Datalab. With a Laptop Science diploma and a Grasp’s in Knowledge Science, Diego has constructed his profession within the area of synthetic intelligence and machine studying. His expertise contains roles as a Machine Studying Engineer at firms like AppliedIT and Applus+ IDIADA, the place he has labored on creating superior AI methods and anomaly detection options.
 Jordi Sánchez Ferrer is the present Product Proprietor of the Datalab at Applus+ Idiada. A Laptop Engineer with a Grasp’s diploma in Knowledge Science, Jordi’s trajectory contains roles as a Enterprise Intelligence developer, Machine Studying engineer, and lead developer in Datalab. In his present function, Jordi combines his technical experience with product administration abilities, main strategic initiatives that align knowledge science and AI initiatives with enterprise targets at Applus+ Idiada.
Jordi Sánchez Ferrer is the present Product Proprietor of the Datalab at Applus+ Idiada. A Laptop Engineer with a Grasp’s diploma in Knowledge Science, Jordi’s trajectory contains roles as a Enterprise Intelligence developer, Machine Studying engineer, and lead developer in Datalab. In his present function, Jordi combines his technical experience with product administration abilities, main strategic initiatives that align knowledge science and AI initiatives with enterprise targets at Applus+ Idiada.
 Daniel Colls is knowledgeable with greater than 25 years of expertise who has lived by the digital transformation and the transition from the on-premises mannequin to the cloud from totally different views within the IT sector. For the previous 3 years, as a Options Architect at AWS, he has made this expertise accessible to his prospects, serving to them efficiently implement or transfer their workloads to the cloud.
Daniel Colls is knowledgeable with greater than 25 years of expertise who has lived by the digital transformation and the transition from the on-premises mannequin to the cloud from totally different views within the IT sector. For the previous 3 years, as a Options Architect at AWS, he has made this expertise accessible to his prospects, serving to them efficiently implement or transfer their workloads to the cloud.





