The right way to Implement a Fundamental Reranking System in RAG


Picture by Creator | Ideogram
Reranking methods considerably improve the relevance and accuracy of data retrieval methods, together with language fashions endowed with retrieval augmented era (RAG), to prioritize probably the most contextually related and exact responses, refining the generated outputs by aligning them nearer with consumer intent.
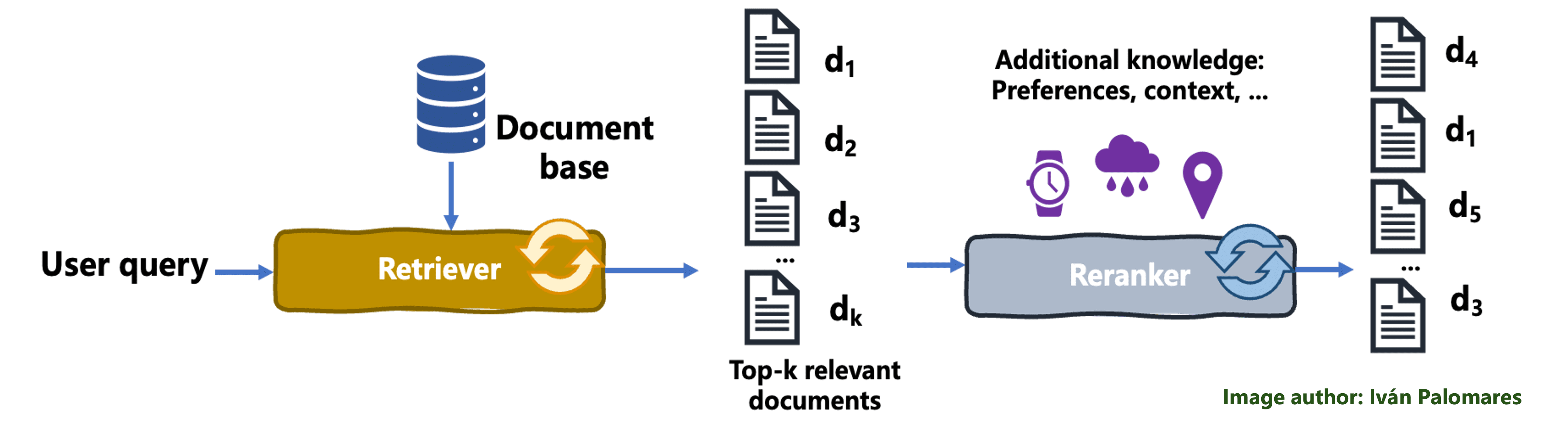
A primary reranking system in RAG
This tutorial walks you thru constructing a primary reranker appropriate for RAG methods in Python. The implementation proven is extremely modular and centered on clearly understanding the reranking course of itself.
Step-by-Step Reranking Course of
We begin by importing the packages that shall be wanted all through the code.
from dataclasses import dataclass
from typing import Checklist, Tuple
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
Subsequent, we outline one of many predominant lessons for the reranking system: the Doc class:
@dataclass
class Doc:
"""A doc with its textual content content material, metadata, and preliminary relevance rating"""
content material: str
embedding: np.ndarray
initial_score: float
metadata: dict = None
@dataclass is a decorator that simplifies the category definition by implicitly creating key strategies like __init__, __repr__, and __eq__.
We now outline the perform for reranking paperwork as a standalone perform simply built-in with a RAG system.
def rerank_documents(
query_embedding: np.ndarray,
paperwork: Checklist[Document],
semantic_weight: float = 0.5,
initial_weight: float = 0.5
) -> Checklist[Tuple[Document, float]]:
# Normalizing weights
total_weight = semantic_weight + initial_weight
semantic_weight = semantic_weight / total_weight
initial_weight = initial_weight / total_weight
# Stack doc embeddings right into a matrix
doc_embeddings = np.vstack([doc.embedding for doc in documents])
# Calculate semantic similarities to consumer question embedding
semantic_scores = cosine_similarity(
query_embedding.reshape(1, -1),
doc_embeddings
)[0]
# Get preliminary scores and normalize all scores to 0-1
initial_scores = np.array([doc.initial_score for doc in documents])
semantic_scores = (semantic_scores - semantic_scores.min()) / (semantic_scores.max() - semantic_scores.min())
initial_scores = (initial_scores - initial_scores.min()) / (initial_scores.max() - initial_scores.min())
# Calculate closing scores as weighted averages
final_scores = (semantic_weight * semantic_scores) + (initial_weight * initial_scores)
# Create sorted record of (doc, rating) tuples
ranked_results = record(zip(paperwork, final_scores))
ranked_results.kind(key=lambda x: x[1], reverse=True)
return ranked_results
The perform returns an inventory of document-score pairs, and takes 4 inputs:
- A vector illustration (embedding) of the consumer question.
- A listing of paperwork to rerank: in a RAG system, these are sometimes the paperwork obtained by the retriever part.
- The semantic weight controls the significance given to semantic similarity or doc closeness to the question embedding.
- The significance weight given to the preliminary retrieved paperwork’ scores.
Let’s break the perform physique down step-by-step:
- After normalizing weights to sum as much as 1, the perform stacks the enter paperwork’ embeddings right into a matrix to ease computations.
- The semantic similarities between paperwork and the consumer question are then calculated.
- Entry the preliminary doc scores and normalize each preliminary and semantic scores. In a full-RAG resolution, the preliminary scores are yielded by the retriever, typically utilizing a keyword-based similarity strategy like BM25.
- Compute closing scores for reranking as a weighted common of preliminary and semantic scores.
- Construct and return an inventory of document-score pairs, sorted by closing scores in descending order.
Now it solely stays making an attempt our reranking perform out. Let’s first outline some instance “retrieved” paperwork and consumer question:
def example_reranking():
# Simulate some "retrieved" paperwork with preliminary scores
paperwork = [
Document(
content="The quick brown fox",
embedding=np.array([0.1, 0.2, 0.3]),
initial_score=0.8,
),
Doc(
content material="Jumps over the lazy canine",
embedding=np.array([0.2, 0.3, 0.4]),
initial_score=0.6,
),
Doc(
content material="The canine sleeps peacefully",
embedding=np.array([0.3, 0.4, 0.5]),
initial_score=0.9,
),
]
# Simulate a consumer question embedding
query_embedding = np.array([0.15, 0.25, 0.35])
Then, apply the reranking perform and present the outcomes. By specifying the 2 weights, you’ll be able to customise the way in which your reranking system will work:
reranked_docs = rerank_documents(
query_embedding=query_embedding,
paperwork=paperwork,
semantic_weight=0.7,
initial_weight=0.3
)
print("nReranked paperwork:")
for doc, rating in reranked_docs:
print(f"Rating: {rating:.3f} - Content material: {doc.content material}")
if __name__ == "__main__":
example_reranking()
Output:
Reranked paperwork:
Rating: 0.723 - Content material: The short brown fox
Rating: 0.700 - Content material: Jumps over the lazy canine
Rating: 0.300 - Content material: The canine sleeps peacefully
Now that you’re accustomed to reranking, the following transfer could be integrating your reranker with a RAG-LLM system.
Iván Palomares Carrascosa is a pacesetter, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the true world.





