Fixing the Traditional Betting on the World Sequence Drawback Utilizing Hill Climbing | by W Brett Kennedy | Nov, 2024
A easy instance of hill climbing — and fixing an issue that’s troublesome to unravel with out optimization methods
Betting on the World Sequence is an outdated, fascinating, and difficult puzzle. It’s additionally a pleasant downside to show an optimization method known as hill climbing, which I’ll cowl on this article.
Hill climbing is a well-established, and comparatively easy optimization method. There are numerous different examples on-line utilizing it, however I assumed this downside allowed for an fascinating utility of the method and is value taking a look at.
One place the puzzle may be seen in on a web page hosted by UC Davis. To save lots of you wanting it up, I’ll repeat it right here:
[E. Berlekamp] Betting on the World Sequence. You’re a dealer; your job is to accommodate your shopper’s needs with out inserting any of your private capital in danger. Your shopper needs to put a good $1,000 guess on the end result of the World Sequence, which is a baseball contest determined in favor of whichever of two groups first wins 4 video games. That’s, the shopper deposits his $1,000 with you prematurely of the collection. On the finish of the collection he should obtain from you both $2,000 if his staff wins, or nothing if his staff loses. No market exists for bets on the complete world collection. Nevertheless, you’ll be able to place even bets, in any quantity, on every sport individually. What’s your technique for putting bets on the person video games to be able to obtain the cumulative end result demanded by your shopper?
So, it’s essential to guess on the video games one after the other (although additionally doable to abstain from betting on some video games, merely betting $0 on these). After every sport, we’ll both acquire or lose precisely what we guess on that sport. We begin with the $1000 offered by our shopper. The place our staff wins the total collection, we wish to finish with $2000; the place they lose, we wish to finish with $0.
When you’ve not seen this downside earlier than and want to attempt to resolve it manually, now’s your probability earlier than we go into an outline of fixing this programmatically. It’s a good downside in itself, and may be worthwhile taking a look at fixing it instantly earlier than continuing with a hill-climbing resolution.
For this downside, I’m going to imagine it’s okay to briefly go unfavorable. That’s, if we’re ever, through the world collection, under zero {dollars}, that is okay (we’re a bigger brokerage and might experience this out), as long as we will reliably finish with both $0 or $2000. We then return to the shopper the $0 or $2000.
It’s comparatively easy to provide you with options for this that work more often than not, however not essentially for each situation. Actually, I’ve seen a number of descriptions of this puzzle on-line that present some sketches of an answer, however seem to not be utterly examined for each doable sequence of wins and losses.
An instance of a coverage to guess on the (at most) seven video games could also be to guess: $125, $250, $500, $125, $250, $500, $1000. On this coverage, we guess $125 on the primary sport, $250 on the second sport, and so forth, as much as as many video games as are performed. If the collection lasts 5 video games, for instance, we guess: $125, $250, $500, $125, $250. This coverage will work, truly, usually, although not all.
Contemplate the next sequence: 1111, the place 0 signifies Workforce 0 wins a single sport and 1 signifies Workforce 1 wins a single sport. On this sequence, Workforce 1 wins all 4 video games, so wins the collection. Let’s say, our staff is Workforce 1, so we have to finish with $2000.
Trying on the video games, bets, and {dollars} held after every sport, we now have:
Sport Guess End result Cash Held
---- --- ---- ----------
Begin - - 1000
1 125 1 1125
2 250 1 1375
3 500 1 1875
4 125 1 2000
That’s, we begin with $1000. We guess $125 on the primary sport. Workforce 1 wins that sport, so we win $125, and now have $1125. We then guess $250 on the second sport. Workforce 1 wins this, so we win $250 and now have $1375. And so forth for the following two video games, betting $500 and $125 on these. Right here, we appropriately finish with $2000.
Testing the sequence 0000 (the place Workforce 0 wins in 4 video games):
Sport Guess End result Cash Held
---- --- ---- ----------
Begin - - 1000
1 125 0 875
2 250 0 625
3 500 0 125
4 125 0 0
Right here we appropriately (given Workforce 0 wins the collection) finish with $0.
Testing the sequence 0101011 (the place Workforce 1 wins in seven video games):
Sport Guess End result Cash Held
---- --- ---- ----------
Begin - - 1000
1 125 0 875
2 250 1 1125
3 500 0 625
4 125 1 750
5 250 0 500
6 500 1 1000
7 1000 1 2000
Right here we once more appropriately finish with $2000.
Nevertheless, with the sequence 1001101, this coverage doesn’t work:
Sport Guess End result Cash Held
---- --- ---- ----------
Begin - - 1000
1 125 1 1125
2 250 0 875
3 500 0 375
4 125 1 500
5 250 1 750
6 500 0 250
7 1000 1 1250
Right here, although Workforce 1 wins the collection (with 4 wins in 7 video games), we finish with solely $1250, not $2000.
Since there are lots of doable sequences of video games, that is troublesome to check manually (and fairly tedious if you’re testing many doable polices), so we’ll subsequent develop a perform to check if a given coverage works correctly: if it appropriately ends with at the very least $2000 for all doable collection the place Workforce 1 wins the collection, and at the very least $0 for all doable collection the place Workforce 0 wins the collection.
This takes a coverage within the type of an array of seven numbers, indicating how a lot to guess on every of the seven video games. In collection with solely 4, 5, or six video games, the values within the final cells of the coverage are merely not used. The above coverage may be represented as [125, 250, 500, 125, 250, 500, 1000].
def evaluate_policy(coverage, verbose=False):
if verbose: print(coverage)
total_violations = 0for i in vary(int(math.pow(2, 7))):
s = str(bin(i))[2:]
s = '0'*(7-len(s)) + s # Pad the string to make sure it covers 7 video games
if verbose:
print()
print(s)
cash = 1000
number_won = 0
number_lost = 0
winner = None
for j in vary(7):
current_bet = coverage[j]
# Replace the cash
if s[j] == '0':
number_lost += 1
cash -= current_bet
else:
number_won += 1
cash += current_bet
if verbose: print(f"Winner: {s[j]}, guess: {current_bet}, now have: {cash}")
# Finish the collection if both staff has gained 4 video games
if number_won == 4:
winner = 1
break
if number_lost == 4:
winner = 0
break
if verbose: print("winner:", winner)
if (winner == 0) and (cash < 0):
total_violations += (0 - cash)
if (winner == 1) and (cash < 2000):
total_violations += (2000 - cash)
return total_violations
This begins by making a string illustration of every doable sequence of wins and losses. This creates a set of 2⁷ (128) strings, beginning with ‘0000000’, then ‘0000001’, and so forth, to ‘1111111’. A few of these are redundant, since some collection will finish earlier than all seven video games are performed — as soon as one staff has gained 4 video games. In manufacturing, we’d doubtless clear this as much as cut back execution time, however for simplicity, we merely loop by way of all 2⁷ combos. This does have some profit later, because it treats all 2⁷ (equally doubtless) combos equally.
For every of those doable sequences, we apply the coverage to find out the guess for every sport within the sequence, and maintain a working depend of the cash held. That’s, we loop by way of all 2⁷ doable sequences of wins and losses (quitting as soon as one staff has gained 4 video games), and for every of those sequences, we loop by way of the person video games within the sequence, betting on every of the video games one after the other.
In the long run, if Workforce 0 gained the collection, we ideally have $0; and if Workforce 1 gained the collection, we ideally have $2000, although there is no such thing as a penalty (or profit) if we now have extra.
If we don’t finish a sequence of video games with the right amount of cash, we decide what number of {dollars} we’re brief; that’s the price of that sequence of video games. We sum these shortages up over all doable sequences of video games, which provides us an analysis of how properly the coverage works total.
To find out if any given coverage works correctly or not, we will merely name this methodology with the given coverage (within the type of an array) and test if it returns 0 or not. Something larger signifies that there’s a number of sequences the place the dealer ends with too little cash.
I gained’t go into an excessive amount of element about hill climbing, because it’s pretty well-understood, and properly documented many locations, however will describe the essential thought in a short time. Hill climbing is an optimization method. We sometimes begin by producing a candidate resolution to an issue, then modify this in small steps, with every step getting to higher and higher options, till we finally attain the optimum level (or get caught in an area optima).
To resolve this downside, we will begin with any doable coverage. For instance, we will begin with: [-1000, -1000, -1000, -1000, -1000, -1000, -1000]. This specific coverage is definite to work poorly — we’d truly guess closely towards Workforce 1 all seven video games. However, that is okay. Hill climbing works by beginning wherever after which progressively shifting in direction of higher options, so even beginning with a poor resolution, we’ll ideally finally attain a robust resolution. Although, in some circumstances, we might not, and it’s typically needed (or at the very least helpful) to re-run hill climbing algorithms from completely different beginning factors. On this case, beginning with a really poor preliminary coverage works high quality.
Enjoying with this puzzle manually earlier than coding it, we might conclude {that a} coverage must be a bit extra advanced than a single array of seven values. That type of coverage determines the dimensions of every guess totally based mostly on which sport it’s, ignoring the numbers of wins and losses thus far. What we have to symbolize the coverage is definitely a second array, resembling:
[[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000]]
There are different methods to do that, however, as we’ll present under, this methodology works fairly properly.
Right here, the rows symbolize the variety of wins thus far for Workforce 1: both 0, 1, 2, or 3. The columns, as earlier than, point out the present sport quantity: both 1, 2, 3, 4, 5, 6, or 7.
Once more, with the coverage proven, we might guess $1000 towards Workforce 1 each sport it doesn’t matter what, so nearly any random coverage is certain to be at the very least barely higher.
This coverage has 4×7, or 28, values. Although, some are pointless and this may very well be optimized considerably. I’ve opted for simplicity over effectivity right here, however usually we’d optimize this a bit extra in a manufacturing setting. On this case, we will take away some unattainable circumstances, like having 0 wins by video games 5, 6, or 7 (with no wins for Workforce 1 by sport 5, Workforce 0 should have 4 wins, thus ending the collection). Twelve of the 28 cells are successfully unreachable, with the remaining 16 related.
For simplicity, it’s not used on this instance, however the fields which might be truly related are the next, the place I’ve positioned a -1000:
[[-1000, -1000, -1000, -1000, n/a, n/a, n/a ],
[ n/a, -1000, -1000, -1000, -1000, n/a, n/a ],
[ n/a, n/a, -1000, -1000, -1000, -1000, n/a ],
[ n/a, n/a, n/a, -1000, -1000, -1000, -1000]]
The cells marked ‘n/a’ should not related. For instance, on the primary sport, it’s unattainable to have already had 1, 2, or 3 wins; solely 0 wins is feasible at that time. Alternatively, by sport 4, it’s doable to have 0, 1, 2, or 3 earlier wins.
Additionally enjoying with this manually earlier than coding something, it’s doable to see that every guess is probably going a a number of of both halves of $1000, quarters of $1000, eights, sixteenths, and so forth. Although, this isn’t essentially the optimum resolution, I’m going to imagine that each one bets are multiples of $500, $250, $125, $62.50, or $31.25, and that they might be $0.
I’ll, although, assume that there’s by no means a case to guess towards Workforce 1; whereas the preliminary coverage begins out with unfavorable bets, the method to generate new candidate insurance policies makes use of solely bets between $0 and $1000, inclusive.
There are, then, 33 doable values for every guess (every a number of of $31.25 from $0 to $1000). Given the total 28 cells, and assuming bets are multiples of 31.25, there are 33²⁸ doable combos for the coverage. So, testing all of them is infeasible. Limiting this to the 16 used cells, there are nonetheless 33¹⁶ doable combos. There could also be additional optimizations doable, however there would, nonetheless, be an especially massive variety of combos to test exhaustively, way over could be possible. That’s, instantly fixing this downside could also be doable programmatically, however a brute-force strategy, utilizing solely the assumptions said right here, could be intractable.
So, an optimization method resembling hill climbing may be fairly acceptable right here. By beginning at a random location on the answer panorama (a random coverage, within the type of a 4×7 matrix), and continuously (metaphorically) shifting uphill (every step we transfer to an answer that’s higher, even when solely barely, than the earlier), we finally attain the best level, on this case a workable coverage for the World Sequence Betting Drawback.
Provided that the insurance policies can be represented as second matrices and never 1d arrays, the code above to find out the present guess will modified from:
current_bet = coverage[j]
to:
current_bet = coverage[number_won][j]
That’s, we decide the present guess based mostly on each the variety of video games gained thus far and the quantity of the present sport. In any other case, the evaluate_policy() methodology is as above. The code above to judge a coverage is definitely the majority of the code.
We subsequent present the principle code, which begins with a random coverage, after which loops (as much as 10,000 occasions), every time modifying and (hopefully) enhancing this coverage. Every iteration of the loop, it generates 10 random variations of the current-best resolution, takes one of the best of those as the brand new present resolution (or retains the present resolution if none are higher, and easily retains looping till we do have a greater resolution).
import numpy as np
import math
import copycoverage = [[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000],
[-1000, -1000, -1000, -1000, -1000, -1000, -1000]]
best_policy = copy.deepcopy(coverage)
best_policy_score = evaluate_policy(coverage)
print("beginning rating:", best_policy_score)
for i in vary(10_000):
if i % 100 == 0: print(i)
# Every iteration, generate 10 candidate options much like the
# present finest resolution and take one of the best of those (if any are higher
# than the present finest).
for j in vary(10):
policy_candidate = vary_policy(coverage)
policy_score = evaluate_policy(policy_candidate)
if policy_score <= best_policy_score:
best_policy_score = policy_score
best_policy = policy_candidate
coverage = copy.deepcopy(best_policy)
print(best_policy_score)
show(coverage)
if best_policy_score == 0:
print(f"Breaking after {i} iterations")
break
print()
print("FINAL")
print(best_policy_score)
show(coverage)
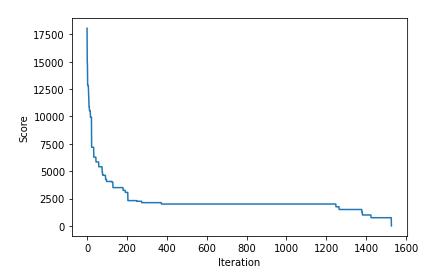
Working this, the principle loop executed 1,541 occasions earlier than discovering an answer. Every iteration, it calls vary_policy() (described under) ten occasions to generate ten variations of the present coverage. It then calls evaluate_policy() to judge every. This was outlined above, and offers a rating (in {dollars}), of how brief the dealer can come up utilizing this coverage in a median set of 128 situations of the world collection (we will divide this by 128 to get the anticipated loss for any single world collection). The decrease the rating, the higher.
The preliminary resolution had a rating of 153,656.25, so fairly poor, as anticipated. It quickly improves from there, shortly dropping to round 100,000, then 70,000, then 50,000, and so forth. Printing one of the best insurance policies discovered so far because the code executes additionally presents more and more extra smart insurance policies.
The next code generates a single variation on the present coverage:
def vary_policy(coverage):
new_policy = copy.deepcopy(coverage)
num_change = np.random.randint(1, 10)
for _ in vary(num_change):
win_num = np.random.alternative(4)
game_num = np.random.alternative(7)
new_val = np.random.alternative([x*31.25 for x in range(33)])
new_policy[win_num][game_num] = new_val
return new_policy
Right here we first choose the variety of cells within the 4×7 coverage to vary, between 1 and 10. It’s doable to switch fewer cells, and this may enhance efficiency when the scores are getting near zero. That’s, as soon as we now have a robust coverage, we doubtless want to change it lower than we might close to the start of the method, the place the options are typically weak and there may be extra emphasis on exploring the search area.
Nevertheless, constantly modifying a small, fastened variety of cells does enable getting caught in native optima (typically there is no such thing as a modification to a coverage that modifies precisely, say, 1 or 2 cells that may work higher, and it’s needed to vary extra cells to see an enchancment), and doesn’t all the time work properly. Randomly choosing a variety of cells to switch avoids this. Although, setting the utmost quantity right here to 10 is only for demonstration, and isn’t the results of any tuning.
If we had been to restrict ourselves to the 16 related cells of the 4×7 matrix for modifications, this code would want solely minor modifications, merely skipping updates to these cells, and marking them with a particular image (equal to ‘n/a’, resembling np.NaN) for readability when displaying the matrices.
In the long run, the algorithm was capable of finding the next coverage. That’s, within the first sport, we may have no wins, so will guess $312.50. Within the second sport, we may have both zero or one win, however in both case can be $312.50. Within the third sport, we may have both zero, one, or two wins, so will guess $250, $375, or $250, and so forth, as much as, at most, seven video games. If we attain sport 7, we should have 3 wins, and can guess $1000 on that sport.
[[312.5, 312.5, 250.0, 125.0, 718.75, 31.25, 281.25],
[375.0, 312.5, 375.0, 375.0, 250.0, 312.5, 343.75],
[437.5, 156.25, 250.0, 375.0, 500.0, 500.0, 781.25],
[750.0, 718.75, 343.75, 125.0, 250.0, 500.0, 1000.0]]
I’ve additionally created a plot of how the scores for one of the best coverage discovered thus far drops (that’s, improves — smaller is best) over the 1,541 iterations:

It is a bit exhausting to see because the rating is initially fairly massive, so we plot this once more, skipping first 15 steps:

We are able to see the rating initially persevering with to drop shortly, even after the primary 15 steps, then going into a protracted interval of little enchancment till it will definitely finds a small modification to the present coverage that improves it, adopted by extra drops till we finally attain an ideal rating of 0 (being $0 brief for any doable sequence of wins & losses).
The issue we labored on right here is an instance of what’s generally known as a constraints satisfaction downside, the place we merely want to discover a resolution that covers all of the given constraints (on this case, we take the constraints as exhausting constraints — it’s needed to finish appropriately with both $0 or $2000 for any doable legitimate sequence of video games).
Given two or extra full options to the issue, there is no such thing as a sense of 1 being higher than the opposite; any that works is sweet, and we will cease as soon as we now have a workable coverage. The N Queens downside and Sudoku, are two different examples of issues of this sort.
Different sorts of issues might have a way of optimality. For instance, with the Travelling Salesperson Drawback, any resolution that visits each metropolis precisely as soon as is a sound resolution, however every resolution has a unique rating, and a few are strictly higher than others. In that sort of downside, it’s by no means clear once we’ve reached the very best resolution, and we often merely attempt for a hard and fast variety of iterations (or period of time), or till we’ve reached an answer with at the very least some minimal stage of high quality. Hill climbing will also be used with all these issues.
It’s additionally doable to formulate an issue the place it’s needed to seek out, not only one, however all workable options. Within the case of the Betting on World Sequence downside, it was easy to discover a single workable resolution, however discovering all options could be a lot more durable, requiring an exhaustive search (although optimized to shortly take away circumstances which might be equal, or to stop analysis early the place insurance policies have a transparent consequence).
Equally, we might re-formulate Betting on World Sequence downside to easily require a very good, however not good, resolution. For instance, we might settle for options the place the dealer comes out even more often than not, and solely barely behind in different circumstances. In that case, hill climbing can nonetheless be used, however one thing like a random search or grid search are additionally doable — taking one of the best coverage discovered after a hard and fast variety of trials, may go sufficiently in that case.
In issues more durable than the Betting on World Sequence downside, easy hill climbing as we’ve used right here is probably not adequate. It might be needed, for instance, to keep up a reminiscence of earlier insurance policies, or to incorporate a course of known as simulated annealing (the place we take, now and again, a sub-optimal subsequent step — a step that will even have decrease high quality than the present resolution — to be able to assist break free from native optima).
For extra advanced issues, it might be higher to make use of Bayesian Optimization, Evolutionary Algorithms, Particle Swarm Intelligence, or different extra superior strategies. I’ll hopefully cowl these in future articles, however this was a comparatively easy downside, and straight-forward hill climbing labored fairly properly (although as indicated, can simply be optimized to work higher).
This text offered a easy instance of hill climbing. The issue was comparatively straight-forward, so hopefully straightforward sufficient to undergo for anybody not beforehand accustomed to hill climbing, or as a pleasant instance even the place you might be accustomed to the method.
What’s fascinating, I feel, is that regardless of this downside being solvable in any other case, optimization methods resembling used listed here are doubtless the best and simplest means to strategy this. Whereas difficult to unravel in any other case, this downside was fairly easy to unravel utilizing hill climbing.
All photos by writer