ADOPT: A Common Adaptive Gradient Technique for Dependable Convergence with out Hyperparameter Tuning

Adam is broadly utilized in deep studying as an adaptive optimization algorithm, but it surely struggles with convergence except the hyperparameter β2 is adjusted primarily based on the particular drawback. Makes an attempt to repair this, like AMSGrad, require the impractical assumption of uniformly bounded gradient noise, which doesn’t maintain in instances with Gaussian noise, as seen in variational autoencoders and diffusion fashions. Different strategies, corresponding to AdaShift, deal with convergence in restricted eventualities however aren’t efficient for normal issues. Latest research recommend Adam can converge by fine-tuning β2 per job, although this method is advanced and problem-specific, warranting additional exploration for common options.
Researchers from The College of Tokyo launched ADOPT. This new adaptive gradient technique achieves optimum convergence at an O(1/√T) price with out requiring particular decisions for β2 or the bounded noise assumption. ADOPT addresses Adam’s non-convergence by excluding the present gradient from the second second estimate and adjusting the order of momentum and normalization updates. Experiments throughout various duties—corresponding to picture classification, generative modeling, language processing, and reinforcement studying—present ADOPT’s superior efficiency over Adam and its variants. The tactic additionally converges reliably in difficult instances, together with eventualities the place Adam and AMSGrad battle.
This research focuses on minimizing an goal perform that is dependent upon a parameter vector by utilizing first-order stochastic optimization strategies. Fairly than working with the precise gradient, they depend on an estimate generally known as the stochastic gradient. For the reason that perform could also be nonconvex, the aim is to discover a stationary level the place the gradient is zero. Customary analyses for convergence on this space typically make a number of key assumptions: the perform has a minimal certain, the stochastic gradient gives an unbiased estimate of the gradient, the perform modifications easily, and the variance of the stochastic gradient is uniformly restricted. For adaptive strategies like Adam, an extra assumption concerning the gradient variance is commonly made to simplify convergence proofs. The researchers apply a set of assumptions to research how adaptive gradient strategies converge with out counting on the stricter assumption that the gradient noise stays bounded.
Prior analysis means that whereas primary stochastic gradient descent usually converges in nonconvex settings, adaptive gradient strategies like Adam are broadly utilized in deep studying because of their flexibility. Nonetheless, Adam typically must converge, particularly in convex instances. A modified model referred to as AMSGrad was developed to handle this, which introduces a non-decreasing scaling of the educational price by updating the second-moment estimate with a most perform. Nonetheless, AMSGrad’s convergence is predicated on the stronger assumption of uniformly bounded gradient noise, which isn’t legitimate in all eventualities, corresponding to in sure generative fashions. Subsequently, the researchers suggest a brand new adaptive gradient replace method that goals to make sure dependable convergence with out counting on stringent assumptions about gradient noise, addressing Adam’s limitations relating to convergence and optimizing parameter dependencies.
The ADOPT algorithm is evaluated throughout numerous duties to confirm its efficiency and robustness in comparison with Adam and AMSGrad. Beginning with a toy drawback, ADOPT efficiently converges the place Adam doesn’t, particularly beneath high-gradient noise circumstances. Testing with an MLP on the MNIST dataset and a ResNet on CIFAR-10 reveals that ADOPT achieves quicker and extra secure convergence. ADOPT additionally outperforms Adam in purposes corresponding to Swin Transformer-based ImageNet classification, NVAE generative modeling, and GPT-2 pretraining beneath noisy gradient circumstances and yields improved scores in LLaMA-7B language mannequin finetuning on the MMLU benchmark.
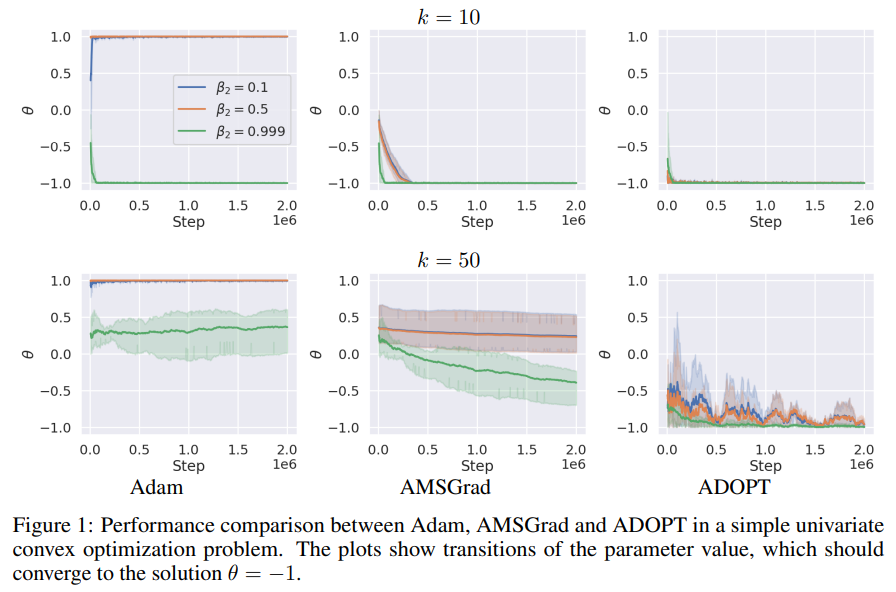
The research addresses the theoretical limitations of adaptive gradient strategies like Adam, which want particular hyperparameter settings to converge. To resolve this, the authors introduce ADOPT, an optimizer that achieves optimum convergence charges throughout numerous duties with out problem-specific tuning. ADOPT overcomes Adam’s limitations by altering the momentum replace order and excluding the present gradient from second-moment calculations, making certain stability throughout duties like picture classification, NLP, and generative modeling. The work bridges idea and software in adaptive optimization, though future analysis might discover extra relaxed assumptions to generalize ADOPT’s effectiveness additional.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.




