BioMed-VITAL: A Clinician-Aligned AI Framework for Biomedical Visible Instruction Tuning
Current advances in multimodal basis fashions like GPT-4V have proven robust efficiency typically visible and textual information duties. Nonetheless, adapting these fashions to specialised domains like biomedicine requires massive, domain-specific instruction datasets. Whereas computerized dataset era has been explored, these datasets typically want extra alignment with skilled data, limiting their real-world applicability. Instruction tuning, which fine-tunes fashions utilizing task-specific prompts, has been efficient however depends on in depth, pricey datasets. Challenges embody the shortage of publicly out there information mills and restricted clinician-annotated information, hindering the event of expert-aligned fashions for specialised purposes.
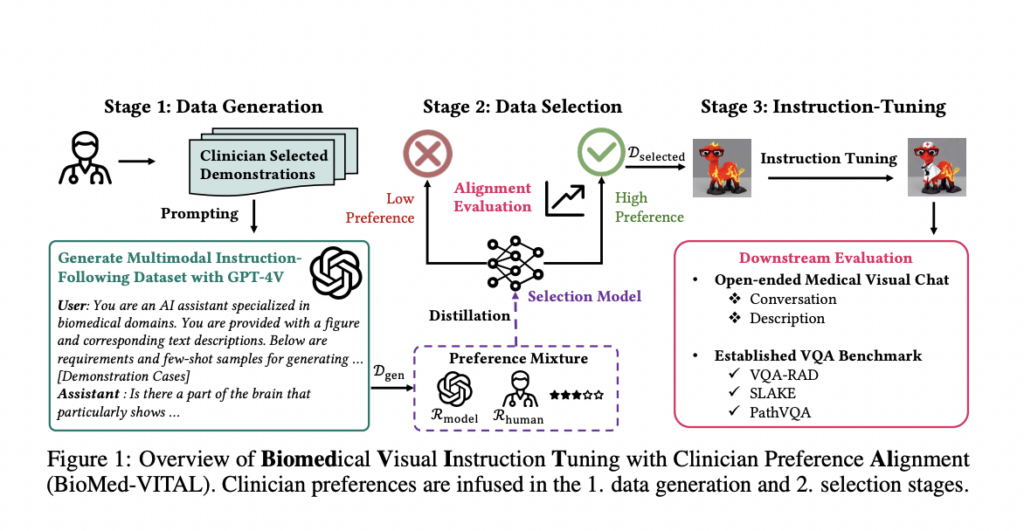
Researchers from Stanford College and Harvard Medical College have developed a framework referred to as Biomedical Visible Instruction Tuning with Clinician Desire Alignment (BioMed-VITAL). This data-centric strategy integrates clinician preferences in producing and choosing instruction information for biomedical multimodal basis fashions. Initially, clinician-selected demonstrations information the era of related information utilizing GPT-4V. Subsequently, a range mannequin, knowledgeable by clinician-annotated and model-annotated information, ranks the generated samples based mostly on high quality. The framework considerably enhances mannequin efficiency, attaining an 18.5% enchancment in open visible chat and an 81.73% win price in biomedical visible query answering.
Instruction tuning has change into a strong method for adapting pre-trained language fashions to numerous pure language duties by offering task-specific directions and examples. Notable research like FLANT5, LLaMA, and LLaMA2 have demonstrated its effectiveness with out in depth fine-tuning. Current approaches counsel utilizing strong language fashions to robotically generate high-quality instruction information, enabling cost-effective coaching, as seen with Stanford Alpaca’s use of text-davinci-003 to instruction-tune LLaMA. Adapting vision-language fashions poses challenges within the biomedical discipline resulting from restricted coaching information. This work goals to create a data-centric technique that aligns clinician experience with tutorial information for improved instruction tuning.
The BioMed-VITAL framework for clinician-aligned biomedical visible instruction tuning consists of three phases: information era, information choice, and instruction tuning. Within the first stage, various expert-selected demonstrations are used with the GPT-4V mannequin to create an tutorial dataset. The second stage entails coaching a knowledge choice mannequin that distills clinician preferences from human annotations and model-based evaluations to filter out low-quality samples. Lastly, within the instruction tuning part, the curated dataset adapts a normal multimodal mannequin for biomedical duties, enhancing its efficiency by way of focused studying on clinician-relevant information.
The research on BioMed-VITAL generated multi-round QA tutorial information from image-text pairs within the PMC-15M dataset utilizing the GPT-4 imaginative and prescient API and BiomedCLIP. Instruction tuning employed the llava-v1.5-13b mannequin to reinforce alignment with clinician preferences. The optimum coaching information combination was a ratio of 1:400 between human and mannequin preferences, attaining peak efficiency at a weight of 400. BioMed-VITAL outperformed the LLaVA-Med baseline in open-ended medical visible chat evaluations, excelling in accuracy and recall throughout benchmarks like VQA-RAD, SLAKE, and PathVQA, demonstrating the effectiveness of incorporating clinician preferences in information era and choice.
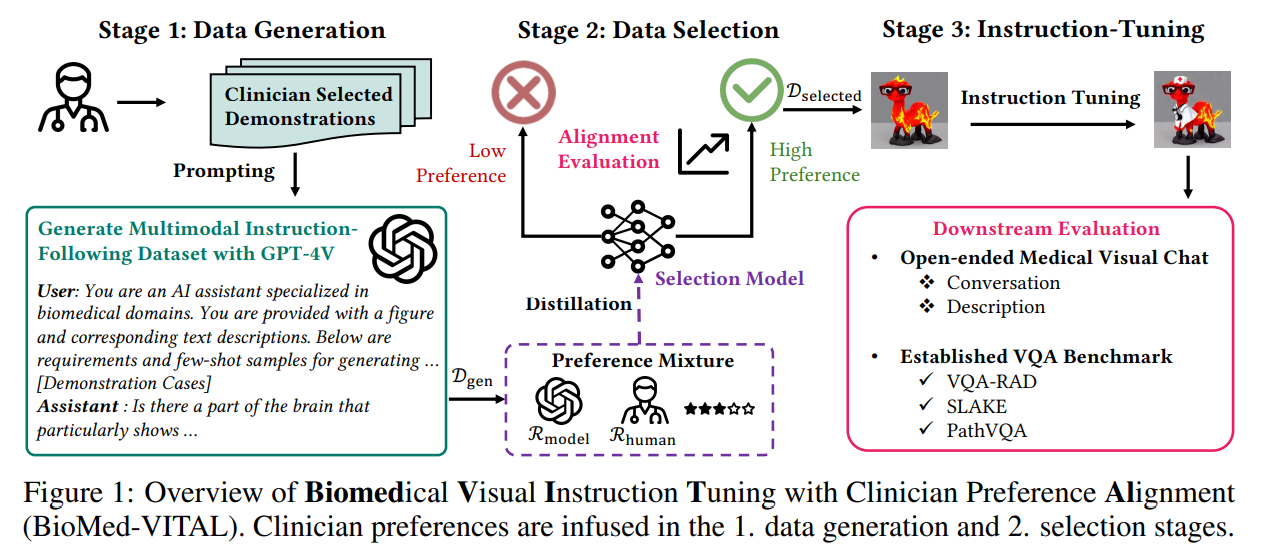
In conclusion, the research presents BioMed-VITAL, a data-centric framework designed for biomedical visible instruction tuning that aligns intently with clinician preferences. By integrating clinician experience into information era and choice processes, BioMed-VITAL creates high-quality datasets that improve the efficiency of visible instruction tuning fashions in biomedicine. The era part makes use of quite a lot of clinician-selected demonstrations to information the GPT-4V generator. In distinction, the choice part entails a devoted mannequin that refines clinician preferences to establish essentially the most related information. This strategy results in notable enhancements in downstream duties, with a big efficiency enhance in open visible chat and medical visible query answering.
Try the Paper and Project Page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our 52k+ ML SubReddit.
We’re inviting startups, firms, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report will probably be launched in late October/early November 2024. Click here to set up a call!
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.





