AMD Releases AMD-135M: AMD’s First Small Language Mannequin Sequence Skilled from Scratch on AMD Intuition™ MI250 Accelerators Using 670B Tokens

AMD has not too long ago launched its new language mannequin, AMD-135M or AMD-Llama-135M, which is a major addition to the panorama of AI fashions. Based mostly on the LLaMA2 mannequin structure, this language mannequin boasts a strong construction with 135 million parameters and is optimized for efficiency on AMD’s newest GPUs, particularly the MI250. This launch marks a vital milestone for AMD in its endeavor to determine a powerful foothold within the aggressive AI trade.
Background and Technical Specs
The AMD-135M is constructed on the LLaMA2 mannequin structure and is built-in with superior options to assist numerous functions, notably in textual content era and language comprehension. The mannequin is designed to work seamlessly with the Hugging Face Transformers library, making it accessible for builders and researchers. The mannequin can deal with complicated duties with a hidden dimension of 768, 12 layers (blocks), and 12 consideration heads whereas sustaining excessive effectivity. The activation operate used is the Swiglu operate, and the layer normalization is predicated on RMSNorm. Its positional embedding is designed utilizing the RoPE methodology, enhancing its means to know and generate contextual info precisely.
The discharge of this mannequin isn’t just in regards to the {hardware} specs but in addition in regards to the software program and datasets that energy it. AMD-135M has been pretrained on two key datasets: the SlimPajama and Mission Gutenberg datasets. SlimPajama is a deduplicated model of RedPajama, which incorporates sources similar to Commoncrawl, C4, GitHub, Books, ArXiv, Wikipedia, and StackExchange. The Mission Gutenberg dataset supplies entry to an enormous repository of classical texts, enabling the mannequin to know numerous language buildings and vocabularies.
Key Options of AMD-135M
AMD-135M has exceptional options that set it aside from different fashions out there. A few of these key options embrace:
- Parameter Dimension: 135 million parameters, permitting for environment friendly processing and era of textual content.
- Variety of Layers: 12 layers with 12 consideration heads for in-depth evaluation and contextual understanding.
- Hidden Dimension: 768, providing the potential to deal with numerous language modeling duties.
- Consideration Sort: Multi-Head Consideration, enabling the mannequin to give attention to totally different features of the enter knowledge concurrently.
- Context Window Dimension: 2048, guaranteeing the mannequin can successfully handle bigger enter knowledge sequences.
- Pretraining and Finetuning Datasets: The SlimPajama and Mission Gutenberg datasets are utilized for pretraining, and the StarCoder dataset is used for finetuning, guaranteeing complete language understanding.
- Coaching Configuration: The mannequin employs a studying price 6e-4 with a cosine studying price schedule, and it has undergone a number of epochs for efficient coaching and finetuning.
Deployment and Utilization
The AMD-135M may be simply deployed and used by way of the Hugging Face Transformers library. For deployment, customers can load the mannequin utilizing the `LlamaForCausalLM` and the `AutoTokenizer` modules. This ease of integration makes it a positive possibility for builders seeking to incorporate language modeling capabilities into their functions. Moreover, the mannequin is appropriate with speculative decoding for AMD’s CodeLlama, additional extending its usability for code era duties. This function makes AMD-135M notably helpful for builders engaged on programming-related textual content era or different NLP functions.
Efficiency Analysis
The efficiency of AMD-135M has been evaluated utilizing the lm-evaluation-harness on numerous NLP benchmarks, similar to SciQ, WinoGrande, and PIQA. The outcomes point out the mannequin is extremely aggressive, providing comparable efficiency to different fashions in its parameter vary. For example, it achieved a move price of roughly 32.31% on the Humaneval dataset utilizing MI250 GPUs, a powerful efficiency indicator for a mannequin of this dimension. This reveals that AMD-135M generally is a dependable mannequin for analysis and business functions in pure language processing.
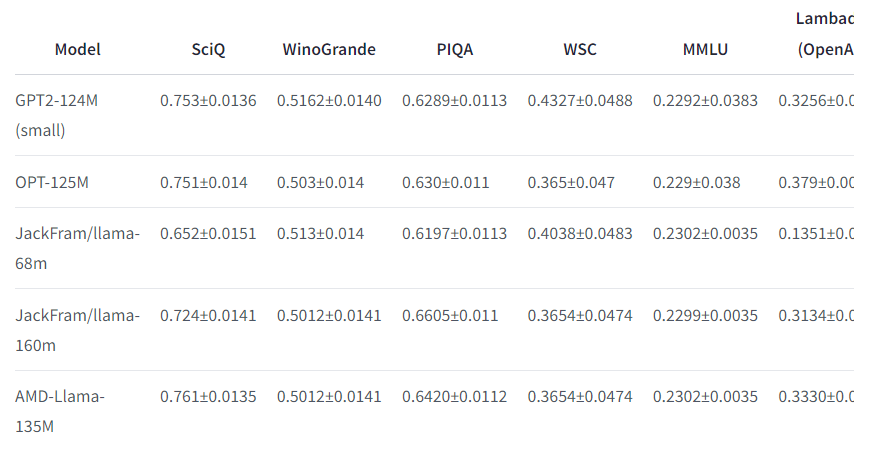
In conclusion, the discharge of AMD-135M underscores AMD’s dedication to advancing AI applied sciences and offering accessible, high-performance fashions for the analysis neighborhood. Its strong structure and superior coaching strategies place AMD-135M as a formidable competitor within the quickly evolving panorama of AI fashions.
Try the Model on Hugging Face and Details. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.





