GenAI for Aerospace: Empowering the workforce with knowledgeable data on Amazon Q and Amazon Bedrock
Aerospace corporations face a generational workforce problem at present. With the sturdy post-COVID restoration, producers are committing to document manufacturing charges, requiring the sharing of extremely specialised area data throughout extra employees. On the identical time, sustaining the headcount and expertise stage of the workforce is more and more difficult, as a technology of subject material specialists (SMEs) retires and elevated fluidity characterizes the post-COVID labor market. This area data is historically captured in reference manuals, service bulletins, high quality ticketing programs, engineering drawings, and extra, however the amount and complexity of paperwork is rising and takes time to study. You merely can’t practice new SMEs in a single day. And not using a mechanism to handle this information switch hole, productiveness throughout all phases of the lifecycle would possibly undergo from dropping knowledgeable data and repeating previous errors.
Generative AI is a contemporary type of machine studying (ML) that has just lately proven vital features in reasoning, content material comprehension, and human interplay. It may be a major drive multiplier to assist the human workforce rapidly digest, summarize, and reply advanced questions from giant technical doc libraries, accelerating your workforce growth. AWS is uniquely positioned that can assist you handle these challenges via generative AI, with a broad and deep vary of AI/ML companies and over 20 years of expertise in creating AI/ML applied sciences.
This publish exhibits how aerospace clients can use AWS generative AI and ML-based companies to handle this document-based data use case, utilizing a Q&A chatbot to offer expert-level steerage to technical employees primarily based on giant libraries of technical paperwork. We concentrate on using two AWS companies:
- Amazon Q will help you get quick, related solutions to urgent questions, resolve issues, generate content material, and take actions utilizing the info and experience present in your organization’s info repositories, code, and enterprise programs.
- Amazon Bedrock is a completely managed service that provides a alternative of high-performing basis fashions (FMs) from main AI corporations like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, together with a broad set of capabilities to construct generative AI functions with safety, privateness, and accountable AI.
Though Amazon Q is a good way to get began with no code for enterprise customers, Amazon Bedrock Knowledge Bases provides extra flexibility on the API stage for generative AI builders; we discover each these options within the following sections. However first, let’s revisit some primary ideas round Retrieval Augmented Technology (RAG) functions.
Generative AI constraints and RAG
Though generative AI holds nice promise for automating advanced duties, our aerospace clients usually specific issues about using the expertise in such a safety- and security-sensitive business. They ask questions similar to:
- “How do I preserve my generative AI functions safe?”
- “How do I ensure my business-critical information isn’t used to coach proprietary fashions?”
- “How do I do know that solutions are correct and solely drawn from authoritative sources?” (Avoiding the well-known drawback of hallucination.)
- “How can I hint the reasoning of my mannequin again to supply paperwork to construct consumer belief?”
- “How do I preserve my generative AI functions updated with an ever-evolving data base?”
In lots of generative AI functions constructed on proprietary technical doc libraries, these issues could be addressed by utilizing the RAG structure. RAG helps preserve the accuracy of responses, retains up with the speedy tempo of doc updates, and supplies traceable reasoning whereas holding your proprietary information non-public and safe.
This structure combines a general-purpose giant language mannequin (LLM) with a customer-specific doc database, which is accessed via a semantic search engine. Reasonably than fine-tuning the LLM to the particular software, the doc library is loaded with the related reference materials for that software. In RAG, these data sources are sometimes called a data base.
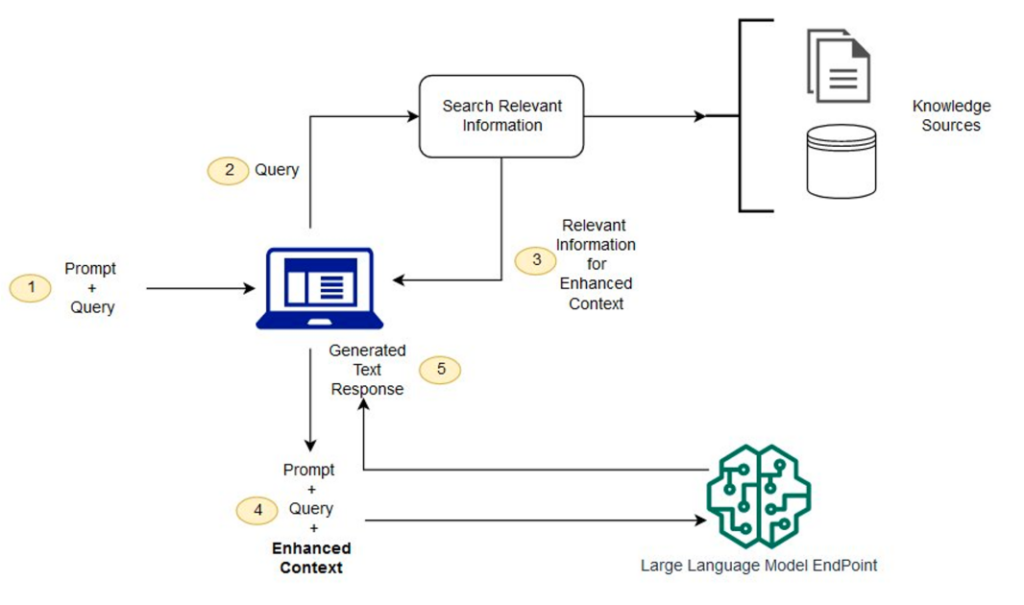
A high-level RAG structure is proven within the following determine. The workflow consists of the next steps:
- When the technician has a query, they enter it on the chat immediate.
- The technician’s query is used to look the data base.
- The search outcomes embrace a ranked listing of most related supply documentation.
- These documentation snippets are added to the unique question as context, and despatched to the LLM as a mixed immediate.
- The LLM returns the reply to the query, as synthesized from the supply materials within the immediate.
As a result of RAG makes use of a semantic search, it may possibly discover extra related materials within the database than only a key phrase match alone. For extra particulars on the operation of RAG programs, seek advice from Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart.

This structure addresses the issues listed earlier in few key methods:
- The underlying LLM doesn’t require customized coaching as a result of the domain-specialized data is contained in a separate data base. Because of this, the RAG-based system could be stored updated, or retrained to utterly new domains, just by altering the paperwork within the data base. This mitigates the numerous price usually related to coaching customized LLMs.
- Due to the document-based prompting, generative AI solutions could be constrained to solely come from trusted doc sources, and supply direct attribution again to these supply paperwork to confirm.
- RAG-based programs can securely handle entry to totally different data bases by role-based entry management. Proprietary data in generative AI stays non-public and guarded in these data bases.
AWS supplies clients in aerospace and different high-tech domains the instruments they should quickly construct and securely deploy generative AI options at scale, with world-class safety. Let’s take a look at how you need to use Amazon Q and Amazon Bedrock to construct RAG-based options in two totally different use instances.
Use case 1: Create a chatbot “knowledgeable” for technicians with Amazon Q
Aerospace is a high-touch business, and technicians are the entrance line of that workforce. Technician work seems at each lifecycle stage for the plane (and its parts), engineering prototype, qualification testing, manufacture, high quality inspection, upkeep, and restore. Technician work is demanding and extremely specialised; it requires detailed data of extremely technical documentation to ensure merchandise meet security, useful, and price necessities. Data administration is a excessive precedence for a lot of corporations, searching for to unfold area data from specialists to junior staff to offset attrition, scale manufacturing capability, and enhance high quality.
Our clients ceaselessly ask us how they’ll use personalized chatbots constructed on personalized generative AI fashions to automate entry to this info and assist technicians make better-informed selections and speed up their growth. The RAG structure proven on this publish is a superb answer to this use case as a result of it permits corporations to rapidly deploy domain-specialized generative AI chatbots constructed securely on their very own proprietary documentation. Amazon Q can deploy absolutely managed, scalable RAG programs tailor-made to handle a variety of enterprise issues. It supplies speedy, related info and recommendation to assist streamline duties, speed up decision-making, and assist spark creativity and innovation at work. It may well mechanically connect with over 40 totally different information sources, together with Amazon Simple Storage Service (Amazon S3), Microsoft SharePoint, Salesforce, Atlassian Confluence, Slack, and Jira Cloud.
Let’s take a look at an instance of how one can rapidly deploy a generative AI-based chatbot “knowledgeable” utilizing Amazon Q.
- Check in to the Amazon Q console.
Should you haven’t used Amazon Q earlier than, you could be greeted with a request for preliminary configuration.
- Beneath Join Amazon Q to IAM Identification Middle, select Create account occasion to create a customized credential set for this demo.
- Beneath Choose a bundle to get began, beneath Amazon Q Enterprise Lite, select Subscribe in Q Enterprise to create a take a look at subscription.
If in case you have beforehand used Amazon Q on this account, you possibly can merely reuse an present consumer or subscription for this walkthrough.

- After you create your AWS IAM Identity Center and Amazon Q subscription, select Get began on the Amazon Q touchdown web page.

- Select Create software.
- For Software identify, enter a reputation (for instance,
my-tech-assistant). - Beneath Service entry, choose Create and use a brand new service-linked position (SLR).
- Select Create.
This creates the applying framework.

- Beneath Retrievers, choose Use native retriever.
- Beneath Index provisioning, choose Starter for a primary, low-cost retriever.
- Select Subsequent.

Subsequent, we have to configure a knowledge supply. For this instance, we use Amazon S3 and assume that you’ve already created a bucket and uploaded paperwork to it (for extra info, see Step 1: Create your first S3 bucket). For this instance, we’ve uploaded some public area paperwork from the Federal Aviation Administration (FAA) technical library regarding software program, system requirements, instrument flight score, plane building and upkeep, and extra.
- For Knowledge sources, select Amazon S3 to level our RAG assistant to this S3 bucket.

- For Knowledge supply identify, enter a reputation in your information supply (impartial of the S3 bucket identify, similar to my-faa-docs).
- Beneath IAM position, select Create new service position (Advisable).
- Beneath Sync scope, select the S3 bucket the place you uploaded your paperwork.
- Beneath Sync run schedule, select Run on demand (or another choice, if you’d like your paperwork to be re-indexed on a set schedule).
- Select Add information supply.
- Depart the remaining settings as default and select Subsequent to complete including your Amazon S3 information supply.

Lastly, we have to create consumer entry permissions to our chatbot.
- Beneath Add teams and customers, select Add teams and customers.
- Within the popup that seems, you possibly can select to both create new customers or choose present ones. If you wish to use an present consumer, you possibly can skip the next steps:
- Choose Add new customers, then select Subsequent.
- Enter the brand new consumer info, together with a sound e-mail handle.
An e-mail will likely be despatched to that handle with a hyperlink to validate that consumer.
- Now that you’ve a consumer, choose Assign present customers and teams and select Subsequent.
- Select your consumer, then select Assign.

You need to now have a consumer assigned to your new chatbot software.
- Beneath Net expertise service entry, choose Create and use a brand new service position.
- Select Create software.

You now have a brand new generative AI software! Earlier than the chatbot can reply your questions, it’s important to run the indexer in your paperwork at the very least one time.
- On the Functions web page, select your software.

- Choose your information supply and select Sync now.
The synchronization course of takes a couple of minutes to finish.
- When the sync is full, on the Net expertise settings tab, select the hyperlink beneath Deployed URL.

Should you haven’t but, you may be prompted to log in utilizing the consumer credentials you created; use the e-mail handle because the consumer identify.
Your chatbot is now able to reply technical questions on the big library of paperwork you supplied. Attempt it out! You’ll discover that for every reply, the chatbot supplies a Sources possibility that signifies the authoritative reference from which it drew its reply.

Our absolutely personalized chatbot required no coding, no customized information schemas, and no managing of underlying infrastructure to scale! Amazon Q absolutely manages the infrastructure required to securely deploy your technician’s assistant at scale.
Use case 2: Use Amazon Bedrock Data Bases
As we demonstrated within the earlier use case, Amazon Q absolutely manages the end-to-end RAG workflow and permits enterprise customers to get began rapidly. However what if you happen to want extra granular management of parameters associated to the vector database, chunking, retrieval, and fashions used to generate ultimate solutions? Amazon Bedrock Data Bases permits generative AI builders to construct and work together with proprietary doc libraries for correct and environment friendly Q&A over paperwork. On this instance, we use the identical FAA paperwork as earlier than, however this time we arrange the RAG answer utilizing Amazon Bedrock Data Bases. We exhibit how to do that utilizing each APIs and the Amazon Bedrock console. The complete pocket book for following the API-based method could be downloaded from the GitHub repo.
The next diagram illustrates the structure of this answer.

Create your data base utilizing the API
To implement the answer utilizing the API, full the next steps:
- Create a job with the mandatory insurance policies to entry information from Amazon S3 and write embeddings to Amazon OpenSearch Serverless. This position will likely be utilized by the data base to retrieve related chunks for OpenSearch primarily based on the enter question.
- Create an empty OpenSearch Serverless index to retailer the doc embeddings and metadata. OpenSearch Serverless is a completely managed possibility that lets you run petabyte-scale workloads with out managing clusters.
- With the OpenSearch Serverless index arrange, now you can create the data base and affiliate it with a knowledge supply containing our paperwork. For brevity, we haven’t included the total code; to run this instance end-to-end, seek advice from the GitHub repo.
The ingestion job will fetch paperwork from the Amazon S3 information supply, preprocess and chunk the textual content, create embeddings for every chunk, and retailer them within the OpenSearch Serverless index.
- With the data base populated, now you can question it utilizing the
RetrieveAndGenerateAPI and get responses generated by LLMs like Anthropic’s Claude on Amazon Bedrock:
The RetrieveAndGenerate API converts the question into an embedding, searches the data base for related doc chunks, and generates a response by offering the retrieved context to the desired language mannequin. We requested the query “How are namespaces registered with the FAA for service suppliers?” Anthropic’s Claude 3 Sonnet makes use of the chunks retrieved from our OpenSearch vector index to reply as follows:
To register a namespace with the FAA as a service supplier, you should observe these steps:
- Develop the namespaces metadata based on FAA-STD-063 and submit it for registration within the FAA Knowledge Registry (FDR).
- The FDR registrar will carry out the namespace registration perform. The precise course of for
creating and registering a namespace within the FDR entails: - Looking the FDR for an present namespace that matches your corporation area. If none exists, work
with the FDR registrar to create a brand new one. - Create and doc the brand new namespace based on FAA-STD-063, following the rules for
group, internet service, or taxonomy namespaces. - Register the namespace within the FDR by both filling out a registration type and submitting it to the FDR
registrar, or requesting entry to enter the metadata straight into the FDR.
Create your data base on the Amazon Bedrock console
Should you favor, you possibly can construct the identical answer in Amazon Bedrock Data Bases utilizing the Amazon Bedrock console as a substitute of the API-based implementation proven within the earlier part. Full the next steps:
- Check in to your AWS account.
- On the Amazon Bedrock console, select Get began.

As a primary step, you should arrange your permissions to make use of the assorted LLMs in Amazon Bedrock.
- Select Mannequin entry within the navigation pane.
- Select Modify mannequin entry.

- Choose the LLMs to allow.
- Select Subsequent¸ then select Submit to finish your entry request.
You need to now have entry to the fashions you requested.

Now you possibly can arrange your data base.
- Select Data bases beneath Builder instruments within the navigation pane.
- Select Create data base.

- On the Present data base particulars web page, preserve the default settings and select Subsequent.
- For Knowledge supply identify, enter a reputation in your information supply or preserve the default.
- For S3 URI, select the S3 bucket the place you uploaded your paperwork.
- Select Subsequent.

- Beneath Embeddings mannequin, select the embeddings LLM to make use of (for this publish, we select Titan Textual content Embeddings).
- Beneath Vector database, choose Fast create a brand new vector retailer.
This feature makes use of OpenSearch Serverless because the vector retailer.
- Select Subsequent.

- Select Create data base to complete the method.
Your data base is now arrange! Earlier than interacting with the chatbot, you should index your paperwork. Ensure you have already loaded the specified supply paperwork into your S3 bucket; for this walkthrough, we use the identical public-domain FAA library referenced within the earlier part.
- Beneath Knowledge supply, choose the info supply you created, then select Sync.
- When the sync is full, select Choose mannequin within the Check data base pane, and select the mannequin you wish to attempt (for this publish, we use Anthropic Claude 3 Sonnet, however Amazon Bedrock provides you the pliability to experiment with many different fashions).

Your technician’s assistant is now arrange! You possibly can experiment with it utilizing the chat window within the Check data base pane. Experiment with totally different LLMs and see how they carry out. Amazon Bedrock supplies a easy API-based framework to experiment with totally different fashions and RAG parts so you possibly can tune them to assist meet your necessities in manufacturing workloads.

Clear up
Once you’re executed experimenting with the assistant, full the next steps to scrub up your created sources to keep away from ongoing prices to your account:
- On the Amazon Q Enterprise console, select Functions within the navigation pane.
- Choose the applying you created, and on the Actions menu, select Delete.
- On the Amazon Bedrock console, select Data bases within the navigation pane.
- Choose the data base you created, then select Delete.
Conclusion
This publish confirmed how rapidly you possibly can launch generative AI-enabled knowledgeable chatbots, skilled in your proprietary doc units, to empower your workforce throughout particular aerospace roles with Amazon Q and Amazon Bedrock. After you could have taken these primary steps, extra work will likely be wanted to solidify these options for manufacturing. Future editions on this “GenAI for Aerospace” sequence will discover follow-up subjects, similar to creating further safety controls and tuning efficiency for various content material.
Generative AI is altering the best way corporations handle a few of their largest challenges. For our aerospace clients, generative AI will help with lots of the scaling challenges that come from ramping manufacturing charges and the abilities of their workforce to match. This publish confirmed how one can apply this expertise to knowledgeable data challenges in varied features of aerospace growth at present. The RAG structure proven will help meet key necessities for aerospace clients: sustaining privateness of information and customized fashions, minimizing hallucinations, customizing fashions with non-public and authoritative reference paperwork, and direct attribution of solutions again to these reference paperwork. There are numerous different aerospace functions the place generative AI could be utilized: non-conformance monitoring, enterprise forecasting, bid and proposal administration, engineering design and simulation, and extra. We look at a few of these use instances in future posts.
AWS supplies a broad vary of AI/ML companies that can assist you develop generative AI options for these use instances and extra. This consists of newly introduced companies like Amazon Q, which supplies quick, related solutions to urgent enterprise questions drawn from enterprise information sources, with no coding required, and Amazon Bedrock, which supplies fast API-level entry to a variety of LLMs, with data base administration in your proprietary doc libraries and direct integration to exterior workflows via brokers. AWS additionally provides aggressive price-performance for AI workloads, operating on purpose-built silicon—the AWS Trainium and AWS Inferentia processors—to run your generative AI companies in probably the most cost-effective, scalable, simple-to-manage approach. Get began on addressing your hardest enterprise challenges with generative AI on AWS at present!
For extra info on working with generative AI and RAG on AWS, seek advice from Generative AI. For extra particulars on constructing an aerospace technician’s assistant with AWS generative AI companies, seek advice from Guidance for Aerospace Technician’s Assistant on AWS.
In regards to the authors
 Peter Bellows is a Principal Options Architect and Head of Expertise for Business Aviation within the Worldwide Specialist Group (WWSO) at Amazon Net Providers (AWS). He leads technical growth for options throughout aerospace domains, together with manufacturing, engineering, operations, and safety. Previous to AWS, he labored in aerospace engineering for 20+ years.
Peter Bellows is a Principal Options Architect and Head of Expertise for Business Aviation within the Worldwide Specialist Group (WWSO) at Amazon Net Providers (AWS). He leads technical growth for options throughout aerospace domains, together with manufacturing, engineering, operations, and safety. Previous to AWS, he labored in aerospace engineering for 20+ years.
 Shreyas Subramanian is a Principal Knowledge Scientist and helps clients by utilizing Machine Studying to unravel their enterprise challenges utilizing the AWS platform. Shreyas has a background in giant scale optimization and Machine Studying, and in use of Machine Studying and Reinforcement Studying for accelerating optimization duties.
Shreyas Subramanian is a Principal Knowledge Scientist and helps clients by utilizing Machine Studying to unravel their enterprise challenges utilizing the AWS platform. Shreyas has a background in giant scale optimization and Machine Studying, and in use of Machine Studying and Reinforcement Studying for accelerating optimization duties.
 Priyanka Mahankali is a Senior Specialist Options Architect for Aerospace at AWS, bringing over 7 years of expertise throughout the cloud and aerospace sectors. She is devoted to streamlining the journey from revolutionary business concepts to cloud-based implementations.
Priyanka Mahankali is a Senior Specialist Options Architect for Aerospace at AWS, bringing over 7 years of expertise throughout the cloud and aerospace sectors. She is devoted to streamlining the journey from revolutionary business concepts to cloud-based implementations.




