Microsoft Analysis Evaluates the Inconsistencies and Sensitivities of GPT-4 in Performing Deterministic Duties: Analyzing the Impression of Minor Modifications on AI Efficiency
Giant language fashions (LLMs) like GPT-4 have grow to be a major focus in synthetic intelligence as a consequence of their means to deal with numerous duties, from producing textual content to fixing advanced mathematical issues. These fashions have demonstrated capabilities far past their authentic design, primarily to foretell the subsequent phrase in a sequence. Whereas their utility spans quite a few industries, corresponding to automating information evaluation and performing artistic duties, a key problem lies in reliably evaluating their true efficiency. Understanding how effectively LLMs deal with deterministic duties, corresponding to counting and performing primary arithmetic, is especially essential as a result of these duties supply clear, measurable outcomes. The complexity arises when even these easy duties reveal inconsistencies in LLM efficiency.
One of many essential issues this analysis addresses is the issue in assessing the accuracy of LLMs like GPT-4. Deterministic duties with a precise resolution are a super testbed for evaluating these fashions. Nevertheless, GPT-4’s efficiency can differ extensively, not simply due to the inherent problem of the duty however as a consequence of minor variations in how questions are framed or the traits of the enter information. These refined elements can result in outcomes that problem the flexibility to generalize the mannequin’s capabilities. For example, even duties as primary as counting objects in an inventory present appreciable variability within the mannequin’s responses, making it clear that straightforward benchmarks will not be sufficient to precisely decide LLMs’ true skills.
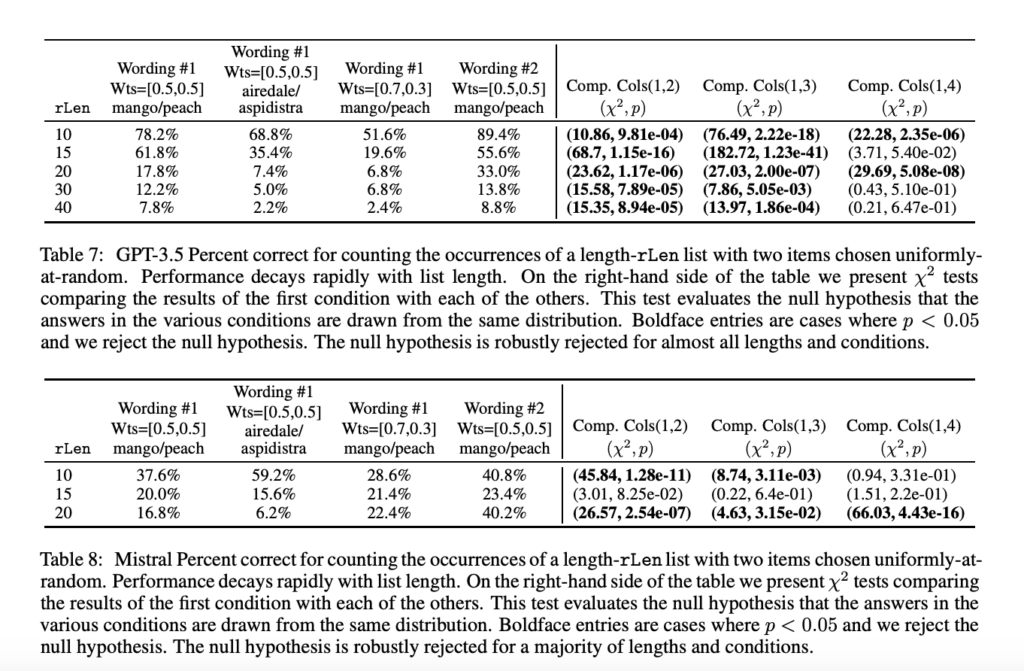
Present strategies to evaluate LLM efficiency usually contain working deterministic duties that permit for clear, unambiguous solutions. On this examine, researchers examined GPT-4’s means to depend parts in an inventory, carry out lengthy multiplication, and type numbers. For example, in a counting job the place the mannequin needed to decide what number of occasions the phrase “mango” appeared in an inventory, GPT-4’s efficiency was not constant. In 500 trials of an inventory with a size of 20, GPT-4 acquired the right reply 48.2% of the time, however slight adjustments in phrasing or object frequency led to considerably totally different outcomes. This inconsistency means that LLMs may not be as succesful as assumed when performing primary arithmetic or logic-based duties.
The analysis group from Microsoft Analysis launched a brand new methodology to judge LLMs’ sensitivity to adjustments in job parameters. They targeted on deterministic duties, corresponding to counting and lengthy multiplication, underneath numerous circumstances. For instance, one set of trials requested GPT-4 to depend occurrences of phrases in lists of various lengths, whereas one other targeted on multiplying two 4-digit numbers. Throughout all duties, the researchers carried out 500 trials for every situation, making certain statistically important outcomes. Their findings confirmed that small modifications, corresponding to rewording the immediate or altering checklist compositions, resulted in massive efficiency variations. For example, the success fee within the counting job dropped from 89.0% for ten objects to simply 12.6% for 40 objects. Equally, GPT-4’s accuracy in lengthy multiplication duties was 100% for multiplying two 2-digit numbers however fell to 1.0% for multiplying two 4-digit numbers.
The researchers additionally measured GPT-4’s efficiency throughout duties, corresponding to discovering the utmost and median and sorting the order of numbers in an inventory. Within the median-finding job, GPT-4 managed solely a 68.4% success fee for lists containing floating-point numbers, and this fee decreased because the variety of objects within the checklist elevated. Moreover, when requested to kind an inventory of numbers with related names, GPT-4’s accuracy dropped considerably, with a hit fee under 55.0%. These experiments reveal how fragile the mannequin’s efficiency is when tasked with operations requiring precisely dealing with structured information.
The analysis highlights a crucial problem in assessing the capabilities of huge language fashions. Whereas GPT-4 demonstrates a variety of subtle behaviors, its means to deal with even primary duties closely will depend on the particular phrasing of questions and the enter information construction. These findings problem the notion that LLMs may be trusted to carry out duties reliably throughout totally different contexts. For example, GPT-4’s success fee for counting duties diversified by greater than 70% relying on the size of the checklist and the frequency of the merchandise being counted. This variability means that noticed accuracy in particular checks may not generalize effectively to different comparable however barely modified duties.

In conclusion, this analysis sheds mild on the restrictions of GPT-4 and different LLMs when performing deterministic duties. Whereas these fashions present promise, their efficiency is very delicate to minor adjustments in job circumstances. The researchers demonstrated that GPT-4’s accuracy might drop from practically excellent to nearly random just by altering the enter information or rephrasing the query. For instance, the mannequin’s means to multiply two 2-digit numbers was excellent, however its accuracy for 4-digit multiplications dropped to simply 1.0%. The outcomes recommend that warning is critical when decoding claims in regards to the capabilities of LLMs. Though they’ll carry out impressively in managed situations, their efficiency may not generalize to barely altered duties. Creating extra rigorous analysis strategies to evaluate their true capabilities is essential.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.