A overview of purpose-built accelerators for monetary providers
Knowledge incorporates info, and data can be utilized to foretell future behaviors, from the shopping for habits of consumers to securities returns. Companies are searching for a aggressive benefit by having the ability to use the info they maintain, apply it to their distinctive understanding of their enterprise area, after which generate actionable insights from it. The monetary providers trade (FSI) isn’t any exception to this, and is a well-established producer and client of information and analytics. All industries have their very own nuances and methods of doing enterprise, and FSI isn’t any exception—right here, concerns resembling regulation and zero-sum recreation aggressive pressures loom giant. This principally non-technical put up is written for FSI enterprise chief personas such because the chief knowledge officer, chief analytics officer, chief funding officer, head quant, head of analysis, and head of threat. These personas are confronted with making strategic choices on points resembling infrastructure funding, product roadmap, and aggressive method. The purpose of this put up is to level-set and inform in a quickly advancing discipline, serving to to know aggressive differentiators, and formulate an related enterprise technique.
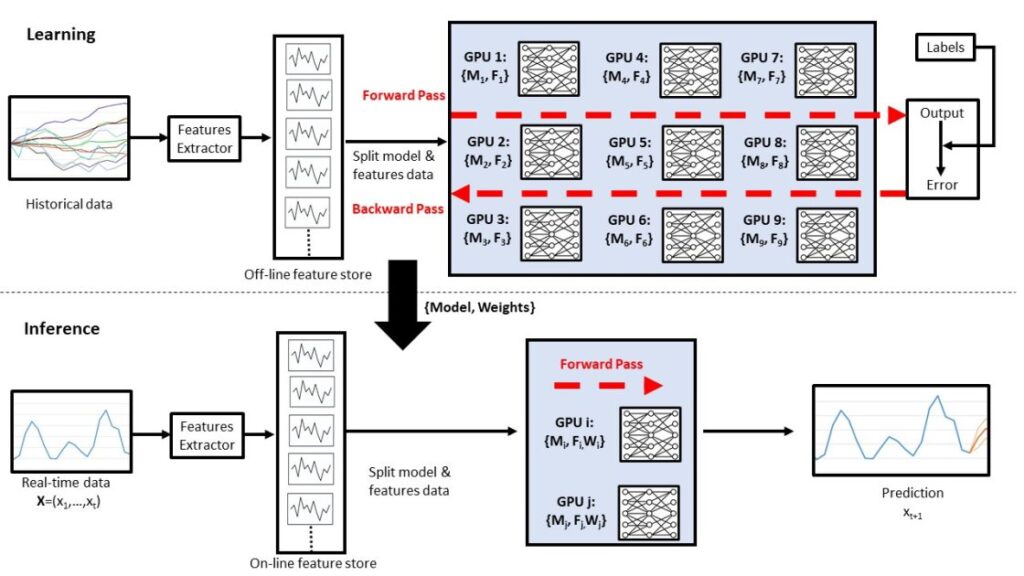
Accelerated computing is a generic time period that’s typically used to seek advice from specialist {hardware} referred to as purpose-built accelerators (PBAs). In monetary providers, almost each sort of exercise, from quant analysis, to fraud prevention, to real-time buying and selling, can profit from lowering runtime. By performing a calculation extra rapidly, the consumer could possibly resolve an equation extra precisely, present a greater buyer expertise, or achieve an informational edge over a competitor. These actions cowl disparate fields resembling primary knowledge processing, analytics, and machine studying (ML). And at last, some actions, resembling these concerned with the newest advances in synthetic intelligence (AI), are merely not virtually potential, with out {hardware} acceleration. ML is commonly related to PBAs, so we begin this put up with an illustrative determine. The ML paradigm is studying adopted by inference. Usually, studying is offline (not streaming real-time knowledge, however historic knowledge) on giant volumes of information, whereas inference is on-line on small volumes of streaming knowledge. Studying means figuring out and capturing historic patterns from the info, and inference means mapping a present worth to the historic sample. PBAs, resembling graphics processing models (GPUs), have an vital function to play in each these phases. The next determine illustrates the concept of a giant cluster of GPUs getting used for studying, adopted by a smaller quantity for inference. The distinct computational nature of the training and inference phases means some {hardware} suppliers have developed unbiased options for every section, whereas others have single options for each phases.

As proven within the previous determine, the ML paradigm is studying (coaching) adopted by inference. PBAs, resembling GPUs, can be utilized for each these steps. On this instance determine, options are extracted from uncooked historic knowledge, that are then are fed right into a neural community (NN). As a result of mannequin and knowledge dimension, studying is distributed over a number of PBAs in an method referred to as parallelism. Labeled knowledge is used to be taught the mannequin construction and weights. Unseen new streaming knowledge is then utilized to the mannequin, and an inference (prediction) on that knowledge is made.
This put up begins by wanting on the background of {hardware} accelerated computing, adopted by reviewing the core applied sciences on this area. We then take into account why and the way accelerated computing is vital for knowledge processing. Then we overview 4 vital FSI use instances for accelerated computing. Key downside statements are recognized and potential options given. The put up finishes by summarizing the three key takeaways, and makes options for actionable subsequent steps.
Background on accelerated computing
CPUs are designed for processing small volumes of sequential knowledge, whereas PBAs are fitted to processing giant volumes of parallel knowledge. PBAs can carry out some capabilities, resembling some floating-point (FP) calculations, extra effectively than is feasible by software program operating on CPUs. This can lead to benefits resembling diminished latency, elevated throughput, and decreased vitality consumption. The three sorts of PBAs are the simply reprogrammable chips resembling GPUs, and two sorts of fixed-function acceleration; field-programmable gate arrays (FPGAs), and application-specific built-in circuits (ASICs). Mounted or semi-fixed operate acceleration is sensible when no updates are wanted to the info processing logic. FPGAs are reprogrammable, albeit not very simply, whereas ASICs are customized totally fastened for a selected software, and never reprogrammable. As a normal rule, the much less user-friendly the speedup, the quicker it’s. When it comes to ensuing speedups, the approximate order is programming {hardware}, then programming in opposition to PBA APIs, then programming in an unmanaged language resembling C++, then a managed language resembling Python. Evaluation of publications containing accelerated compute workloads by Zeta-Alpha exhibits a breakdown of 91.5% GPU PBAs, 4% different PBAs, 4% FPGA, and 0.5% ASICs. This put up is targeted on the simply reprogrammable PBAs.
The latest historical past of PBAs begins in 1999, when NVIDIA launched its first product expressly marketed as a GPU, designed to speed up laptop graphics and picture processing. By 2007, GPUs turned extra generalized computing gadgets, with purposes throughout scientific computing and trade. In 2018, different types of PBAs turned obtainable, and by 2020, PBAs had been being broadly used for parallel issues, resembling coaching of NN. Examples of different PBAs now obtainable embody AWS Inferentia and AWS Trainium, Google TPU, and Graphcore IPU. Round this time, trade observers reported NVIDIA’s technique pivoting from its conventional gaming and graphics focus to shifting into scientific computing and knowledge analytics.
The union of advances in {hardware} and ML has led us to the present day. Work by Hinton et al. in 2012 is now broadly known as ML’s “Cambrian Explosion.” Though NN had been round because the Nineteen Sixties and by no means actually labored, Hinton famous three key modifications. Firstly, they added extra layers to their NN, enhancing their efficiency. Secondly, there was an enormous enhance within the quantity of labeled knowledge obtainable for coaching. Thirdly, the presence of GPUs enabled the labeled knowledge to be processed. Collectively, these components result in the beginning of a interval of dramatic progress in ML, with NN being redubbed deep studying. In 2017, the landmark paper “Attention is all you need” was printed, which laid out a brand new deep studying structure based mostly on the transformer. To be able to practice transformer fashions on internet-scale knowledge, enormous portions of PBAs had been wanted. In November 2022, ChatGPT was launched, a big language mannequin (LLM) that used the transformer structure, and is broadly credited with beginning the present generative AI increase.
Assessment of the know-how
On this part, we overview totally different parts of the know-how.
Parallel computing
Parallel computing refers to finishing up a number of processes concurrently, and could be categorized based on the granularity at which parallelism is supported by the {hardware}. For instance, a grid of related situations, a number of processors inside a single occasion, a number of cores inside a single processor, PBAs, or a mixture of various approaches. Parallel computing makes use of these a number of processing components concurrently to unravel an issue. That is completed by breaking the issue into unbiased elements so that every processing component can full its a part of the workload algorithm concurrently. Parallelism is fitted to workloads which might be repetitive, fastened duties, involving little conditional branching and sometimes giant quantities of information. It additionally means not all workloads are equally appropriate for acceleration.
In parallel computing, the granularity of a process is a measure of the quantity of communication overhead between the processing purposeful models. Granularity is often cut up into the classes of fine-grained and coarse-grained. High quality-grained parallelism refers to a workload being cut up into a lot of small duties, whereas coarse-grained refers to splitting right into a small variety of giant duties. The important thing distinction between the 2 classes is the diploma of communication and synchronization required between the processing models. A thread of execution is the smallest sequence of programmed directions that may be managed independently by a scheduler, and is often a part of a course of. The a number of threads of a given course of could also be run concurrently by multithreading, whereas sharing assets resembling reminiscence. An software can obtain parallelism by utilizing multithreading to separate knowledge and duties into parallel subtasks and let the underlying structure handle how the threads run, both concurrently on one core or in parallel on a number of cores. Right here, every thread performs the identical operation on totally different segments of reminiscence in order that they will function in parallel. This, in flip, permits higher system utilization and offers quicker program execution.
Function constructed accelerators
Flynn’s taxonomy is a classification of laptop architectures useful in understanding PBAs. Two classifications of relevance are single instruction stream, a number of knowledge streams (SIMD), and the SIMD sub-classification of single instruction, a number of thread (SIMT). SIMD describes computer systems with a number of processing components that carry out the identical operation on a number of knowledge factors concurrently. SIMT describes processors which might be capable of function on knowledge vectors and arrays (versus simply scalars), and subsequently deal with large knowledge workloads effectively. Every SIMT core has a number of threads that run in parallel, thereby giving true simultaneous parallel hardware-level execution. CPUs have a comparatively small variety of complicated cores and are designed to run a sequence of operations (threads) as quick as potential, and might run just a few tens of those threads in parallel. GPUs, in distinction, function smaller cores and are designed to run 1000’s of threads in parallel within the SIMT paradigm. It’s this design that primarily distinguishes GPUs from CPUs and permits GPUs to excel at common, dense, numerical, data-flow-dominated workloads.
Suppliers of information middle GPUs embody NVIDIA, AMD, Intel, and others. The AWS P5 EC2 occasion sort vary relies on the NVIDIA H100 chip, which makes use of the Hopper architecture. The Hopper H100 GPU (SXM5 variant) structure consists of 8 GPU processing clusters (GPCs), 66 texture processing clusters (TPCs), 2 Streaming Multiprocessors (SMs)/TPC, 528 Tensor cores/GPU, and 128 CUDA cores/SM. Moreover, it options 80 GB HBM3 GPU reminiscence, 900 GBps NVLink GPU-to-GPU interconnect, and a 50 MB L2 cache minimizing HBM3 journeys. An NVIDIA GPU is assembled in a hierarchal method: the GPU incorporates a number of GPCs, and the function of every GPC is to behave as a container to carry all of the parts collectively. Every GPC has a raster engine for graphics and a number of other TPCs. Inside every TPC is a texture unit, some logic management, and a number of SMs. Inside every SM are a number of CUDA and Tensor cores, and it’s right here that the compute work occurs. The ratio of models GPU:GPC:TPC:SM:CUDA core/Tensor core varies based on launch and model. This hierarchal structure is illustrated within the following determine.

SMs are the elemental constructing blocks of an NVIDIA GPU, and encompass CUDA cores, Tensor cores, distributed shared reminiscence, and directions to help dynamic programming. When a CUDA program is invoked, work is distributed to the multithreaded SMs with obtainable execution capability. The CUDA core, launched in 2007, is a GPU core roughly equal to a CPU core. Though it’s not as highly effective as a CPU core, the CUDA core benefit is its means for use for large-scale parallel computing. Like a CPU core, every CUDA core nonetheless solely runs one operation per clock cycle; nevertheless, the GPU SIMD structure permits giant numbers of CUDA cores to concurrently handle one knowledge level every. CUDA cores are cut up into help for various precision, that means that in the identical clock cycle, a number of precision work could be completed. The CUDA core is effectively fitted to high-performance computing (HPC) use instances, however isn’t so effectively fitted to the matrix math present in ML. The Tensor core, launched in 2017, is one other NVIDIA proprietary GPU core that permits mixed-precision computing, and is designed to help the matrix math of ML. Tensor cores help blended FP accuracy matrix math in a computationally environment friendly method by treating matrices as primitives and having the ability to carry out a number of operations in a single clock cycle. This makes GPUs effectively fitted to data-heavy, matrix math-based, ML coaching workloads, and real-time inference workloads needing synchronicity at scale. Each use instances require the power to maneuver knowledge across the chip rapidly and controllably.
From 2010 onwards, different PBAs have began turning into obtainable to shoppers, resembling AWS Trainium, Google’s TPU, and Graphcore’s IPU. Whereas an in-depth overview on different PBAs is past the scope of this put up, the core precept is considered one of designing a chip from the bottom up, based mostly round ML-style workloads. Particularly, ML workloads are typified by irregular and sparse knowledge entry patterns. This implies there’s a requirement to help fine-grained parallelism based mostly on irregular computation with aperiodic reminiscence entry patterns. Different PBAs sort out this downside assertion in a wide range of other ways from NVIDIA GPUs, together with having cores and supporting structure complicated sufficient for operating utterly distinct applications, and decoupling thread knowledge entry from the instruction move by having distributed reminiscence subsequent to the cores.
AWS accelerator {hardware}
AWS presently gives a variety of 68 Amazon Elastic Compute Cloud (Amazon EC2) instance types for accelerated compute. Examples embody F1 Xilinx FPGAs, P5 NVIDIA Hopper H100 GPUs, G4ad AMD Radeon Professional V520 GPUs, DL2q Qualcomm AI 100, DL1 Habana Gaudi, Inf2 powered by Inferentia2, and Trn1 powered by Trainium. In March 2024, AWS announced it would provide the brand new NVIDIA Blackwell platform, that includes the brand new GB200 Grace Blackwell chip. Every EC2 occasion sort has quite a few variables related to it, resembling worth, chip maker, Regional availability, quantity of reminiscence, quantity of storage, and community bandwidth.
AWS chips are produced by our personal Annapurna Labs workforce, a chip and software program designer, which is a completely owned subsidiary of Amazon. The Inferentia chip turned usually obtainable (GA) in December 2019, adopted by Trainium GA in October 2022, and Inferentia2 GA in April 2023. In November 2023, AWS announced the following technology Trainium2 chip. By proudly owning the provision and manufacturing chain, AWS is ready to provide high-levels of availability of its personal chips. Availability AWS Areas are proven within the following desk, with extra Areas coming quickly. Each Inferentia2 and Trainium use the identical primary parts, however with differing layouts, accounting for the totally different workloads they’re designed to help. Each chips use two NeuronCore-v2 cores every, related by a variable variety of NeuronLink-v2 interconnects. The NeuronCores comprise four engines: the primary three embody a ScalarEngine for scalar calculations, a VectorEngine for vector calculations, and a TensorEngine for matrix calculations. By analogy to an NVIDIA GPU, the primary two are corresponding to CUDA cores, and the latter is equal to TensorCores. And at last, there’s a C++ programmable GPSIMD-engine permitting for customized operations. The silicon structure of the 2 chips may be very comparable, that means that the identical software program can be utilized for each, minimizing modifications on the consumer facet, and this similarity could be mapped again to their two roles. Normally, the training section of ML is often bounded by bandwidth related to shifting giant volumes of information to the chip and in regards to the chip. The inference section of ML is often bounded by reminiscence, not compute. To maximise absolute-performance and price-performance, Trainium chips have twice as many NeuronLink-v2 interconnects as Inferentia2, and Trainium situations additionally comprise extra chips per occasion than Inferentia2 situations. All these variations are applied on the server stage. AWS clients resembling Databricks and Anthropic use these chips to coach and run their ML fashions.
The next figures illustrate the chip-level schematic for the architectures of Inferentia2 and Trainium.

The next desk exhibits the metadata of three of the most important accelerated compute situations.
| Occasion Identify | GPU Nvidia H100 Chips | Trainium Chips | Inferentia Chips | vCPU Cores | Chip Reminiscence (GiB) | Host Reminiscence (GiB) | Occasion Storage (TB) | Occasion Bandwidth (Gbps) | EBS Bandwidth (Gbps) | PBA Chip Peer-to-Peer Bandwidth (GBps) |
| p5.48xlarge | 8 | 0 | 0 | 192 | 640 | 2048 | 8 x 3.84 SSD | 3,200 | 80 | 900 NVSwitch |
| inf2.48xlarge | 0 | 0 | 12 | 192 | 384 | 768 | EBS solely | 100 | 60 | 192 NeuronLink-v2 |
| trn1n.32xlarge | 0 | 16 | 0 | 128 | 512 | 512 | 4 x 1.9 SSD | 1,600 | 80 | 768 NeuronLink-v2 |
The next desk summarizes efficiency and value.
| Occasion Identify | On-Demand Charge ($/hr) | 3Yr RI Charge ($/hr) | FP8 TFLOPS | FP16 TFLOPS | FP32 TFLOPS | $/TFLOPS (FP16, theoretical) | Supply Reference |
| p5.48xlarge | 98.32 | 43.18 | 16,000 | 8,000 | 8,000 | $5.40 | URL |
| inf2.48xlarge | 12.98 | 5.19 | 2,280 | 2,280 | 570 | $2.28 | URL |
| trn1n.32xlarge | 24.78 | 9.29 | 3,040 | 3,040 | 760 | $3.06 | URL |
The next desk summarizes Area availability.
| Occasion Identify | Variety of AWS Areas Supported In | AWS Areas Supported In | Default Quota Limit |
| p5.48xlarge | 4 | us-east-2; us-east-1; us-west-2; eu-north-1 | 0 |
| inf2.48xlarge | 13 | us-east-2; us-east-1; us-west-2; ap-south-1; ap-southeast-1; ap-southeast-2; ap-northeast-1; eu-central-1; eu-west-1; eu-west-2; eu-west-3; eu-north-1; sa-east-1; | 0 |
| trn1n.32xlarge | 3 | us-east-2; us-east-1; us-west-2; eu-north-1; ap-northeast-1; ap-south-1; ap-southeast-4 | 0 |
After a consumer has chosen the EC2 occasion sort, it will probably then be mixed with AWS providers designed to help large-scale accelerated computing use instances, together with high-bandwidth networking (Elastic Fabric Adapter), virtualization (AWS Nitro Enclaves), hyper-scale clustering (Amazon EC2 UltraClusters), low-latency storage (Amazon FSx for Lustre), and encryption (AWS Key Management Service), whereas noting not all providers can be found for all situations in all Areas.
The next determine exhibits an instance of a large-scale deployment of P5 EC2 situations, consists of UltraCluster help for 20,000 H100 GPUs, with non-blocking petabit-scale networking, and high-throughput low latency storage. Utilizing the identical structure, UltraCluster helps Trainium scaling to over 60,000 chips.

In abstract, we see two normal tendencies within the {hardware} acceleration area. Firstly, enhancing price-performance to deal with growing knowledge processing volumes and mannequin sizes, coupled with a must serve extra customers, extra rapidly, and at diminished price. Secondly, enhancing safety of the related workloads by stopping unauthorized customers from having the ability to entry coaching knowledge, code, or mannequin weights.
Accelerator software program
CPUs and GPUs are designed for various kinds of workloads. Nevertheless, CPU workloads can run on GPUs, a course of referred to as general-purpose computing on graphics processing models (GPGPU). To be able to run a CPU workload on a GPU, the work must be reformulated when it comes to graphics primitives supported by the GPU. This reformulation could be carried out manually, although it’s troublesome programming, requiring writing code in a low-level language to map knowledge to graphics, course of it, after which map it again. As an alternative, it’s generally carried out by a GPGPU software program framework, permitting the programmer to disregard the underlying graphical ideas, and enabling simple coding in opposition to the GPU utilizing normal programming languages resembling Python. Such frameworks are designed for sequential parallelism in opposition to GPUs (or different PBAs) with out requiring concurrency or threads. Examples of GPGPU frameworks are the vendor-neutral open supply OpenCL and the proprietary NVIDIA CUDA.
For the Amazon PBA chips Inferentia2 and Trainium, the SDK is AWS Neuron. This SDK permits growth, profiling, and deployment of workloads onto these PBAs. Neuron has numerous native integrations to third-party ML frameworks like PyTorch, TensorFlow, and JAX. Moreover, Neuron features a compiler, runtime driver, in addition to debug and profiling utilities. This toolset consists of Neuron-top for real-time visualization of the NeuronCore and vCPU utilization, host and gadget reminiscence utilization, and a breakdown of reminiscence allocation. This info can also be obtainable in JSON format if neuron-monitor is used, together with Neuron-ls for gadget discovery and topology info. With Neuron, customers can use inf2 and trn1n situations with a variety of AWS compute providers, resembling Amazon SageMaker, Amazon Elastic Container Service, Amazon Elastic Kubernetes Service, AWS Batch, and AWS ParallelCluster. This usability, tooling, and integrations of the Neuron SDK has made Amazon PBAs extraordinarily common with customers. For instance, over 90% of the highest 100 Hugging Face fashions (now over 100,000 AI fashions) now run on AWS utilizing Optimum Neuron, enabling the Hugging Face transformer natively supported for Neuron. In abstract, the Neuron SDK permits builders to simply parallelize ML algorithms, resembling these generally present in FSI. The next determine illustrates the Neuron software program stack.

The CUDA API and SDK had been first launched by NVIDIA in 2007. CUDA gives high-level parallel programming ideas that may be compiled to the GPU, giving direct entry to the GPU’s digital instruction set and subsequently the power to specify thread-level parallelism. To realize this, CUDA added one extension to the C language to let customers declare capabilities that might run and compile on the GPU, and a light-weight technique to name these capabilities. The core thought behind CUDA was to take away programmers’ barrier to entry for coding in opposition to GPUs by permitting use of current abilities and instruments as a lot as potential, whereas being extra consumer pleasant than OpenCL. The CUDA platform consists of drivers, runtime kernels, compilers, libraries, and developer instruments. This features a large and spectacular vary of ML libraries like cuDNN and NCCL. The CUDA platform is used by way of complier directives and extensions to straightforward languages, such because the Python cuNumeric library. CUDA has constantly optimized over time, utilizing its proprietary nature to enhance efficiency on NVIDIA {hardware} relative to vendor-neutral options like OpenCL. Over time, the CUDA programming paradigm and stack has change into deeply embedded in all facets of the ML ecosystem, from academia to open supply ML repositories.
To this point, different GPU platforms to CUDA haven’t seen widespread adoption. There are three key causes for this. Firstly, CUDA has had a decades-long head begin, and advantages from the networking impact of its mature ecosystem, from organizational inertia of change, and from threat aversion to alter. Secondly, migrating CUDA code to a distinct GPU platform could be technically troublesome, given the complexity of the ML fashions usually being accelerated. Thirdly, CUDA has integrations with main third-party ML libraries, resembling TensorFlow and PyTorch.
Regardless of the central function CUDA performs within the AI/ML neighborhood, there’s motion by customers to diversify their accelerated workflows by motion in direction of a Pythonic programming layer to make coaching extra open. Numerous such efforts are underway, together with tasks like Triton and OneAPI, and cloud service options resembling Amazon SageMaker Neo. Triton is an open supply undertaking lead by OpenAI that permits builders to make use of totally different acceleration {hardware} utilizing completely open supply code. Triton makes use of an intermediate compiler to transform fashions written in supported frameworks into an intermediate illustration that may then be lowered into extremely optimized code for PBAs. Triton is subsequently a hardware-agnostic convergence layer that hides chip variations.
Quickly to be launched is the AWS neuron kernel interface (NKI) programming interface. NKI is a Python-based programming setting designed for the compiler, which adopts generally used Triton-like syntax and tile-level semantics. NKI offers customization capabilities to totally optimize efficiency by enabling customers to write down customized kernels, by passing nearly the entire AWS compiler layers.
OneAPI is an open supply undertaking lead by Intel for a unified API throughout totally different accelerators together with GPUs, different PBAs, and FPGAs. Intel believes that future competitors on this area will occur for inference, in contrast to within the studying section, the place there isn’t a software program dependency. To this finish, OneAPI toolkits help CUDA code migration, evaluation, and debug instruments. Different efforts are constructing on prime of OneAPI; for, instance the Unified Acceleration Foundation’s (UXL) objective is a brand new open normal accelerator software program ecosystem. UXL consortium members embody Intel, Google, and ARM.
Amazon SageMaker is an AWS service offering an ML growth setting, the place the consumer can choose chip sort from the service’s fleet of Intel, AMD, NVIDIA, and AWS {hardware}, providing diversified cost-performance-accuracy trade-offs. Amazon contributes to Apache TVM, an open supply ML compiler framework for GPUs and PBAs, enabling computations on any {hardware} backend. SageMaker Neo makes use of Apache TVM to carry out static optimizations on educated fashions for inference for any given {hardware} goal. Trying to the longer term, the accelerator software program discipline is prone to evolve; nevertheless, this can be sluggish to occur.
Accelerator supply-demand imbalances
It has been broadly reported for the previous few years that GPUs are briefly provide. Such shortages have led to trade leaders talking out. For instance, Sam Altman mentioned “We’re so quick on GPUs the much less individuals use our merchandise the higher… we don’t have sufficient GPUs,” and Elon Musk mentioned “It looks like everybody and their canine is shopping for GPUs at this level.”
The components resulting in this have been excessive demand coupled with low provide. Excessive demand has risen from a variety of sectors, together with crypto mining, gaming, generic knowledge processing, and AI. Omdia Research estimates 49% of GPUs go to the hyper-clouds (resembling AWS or Azure), 27% go to large tech (resembling Meta and Tesla), 20% go to GPU clouds (resembling Coreweave and Lambda) and 6% go to different firms (resembling OpenAI and FSI companies). The State of AI Report provides the scale and homeowners of the most important A100 clusters, the highest few being Meta with 21,400, Tesla with 16,000, XTX with 10,000, and Stability AI with 5,408. GPU provide has been restricted by components together with lack of producing competitors and skill in any respect ranges within the provide chain, and restricted provide of base parts resembling uncommon metals and circuit boards. Moreover, fee of producing is sluggish, with an H100 taking 6 months to make. Socio-political occasions have additionally brought about delays and points, resembling a COVID backlog, and with inert gases for manufacturing coming from Russia. A ultimate challenge impacting provide is that chip makers strategically allocate their provide to satisfy their long-term enterprise aims, which can not all the time align with end-users’ wants.
Supported workloads
To be able to profit from {hardware} acceleration, a workload must be parallelizable. A whole department of science is devoted to parallelizable issues. In The Landscape of Parallel Computing Research, 13 fields (termed dwarfs) are discovered to be basically parallelizable, together with dense and sparse linear algebra, Monte Carlo strategies, and graphical fashions. The authors additionally name out a sequence of fields they time period “embarrassingly sequential” for which the other holds. In FSI, one of many important knowledge buildings handled is time sequence, a sequence of sequential observations. Many time sequence algorithms have the property the place every subsequent commentary relies on earlier observations. This implies solely a while sequence workloads could be effectively computed in parallel. For instance, a shifting common is an efficient instance of a computation that appears inherently sequential, however for which there’s an efficient parallel algorithm. Sequential fashions, resembling Recurrent Neural Networks (RNN) and Neural Unusual Differential Equations, even have parallel implementations. In FSI, non-time sequence workloads are additionally underpinned by algorithms that may be parallelized. For instance, Markovitz portfolio optimization requires the computationally intensive inversion of enormous covariance matrices, for which GPU implementations exist.
In laptop science, a quantity could be represented with totally different ranges of precision, resembling double precision (FP64), single precision (FP32), and half-precision (FP16). Totally different chips help totally different representations, and totally different representations are appropriate for various use instances. The decrease the precision, the much less storage is required, and the quicker the quantity is to course of for a given quantity of computational energy. FP64 is utilized in HPC fields, such because the pure sciences and monetary modeling, leading to minimal rounding errors. FP32 offers a steadiness between accuracy and velocity, is utilized in purposes resembling graphics, and is the usual for GPUs. FP16 is utilized in deep studying the place computational velocity is valued, and the decrease precision received’t drastically have an effect on the mannequin’s efficiency. Extra not too long ago, different quantity representations have been developed which purpose to enhance the steadiness between acceleration and precision, resembling OCP Customary FP8, Google BFloat16, and Posits. An instance of a blended illustration use case is the updating of mannequin parameters by gradient respectable, a part of the backpropagation algorithm, as utilized in deep studying. Usually that is completed utilizing FP32 to scale back rounding errors, nevertheless, with the intention to scale back reminiscence load, the parameters and gradients could be saved in FP16, that means there’s a conversion requirement. On this case, BFloat16 is an efficient selection as a result of it prevents float overflow errors whereas conserving sufficient precision for the algorithm to work.
As lower-precision workloads change into extra vital, {hardware} and infrastructure tendencies are altering accordingly. For instance, evaluating the newest NVIDIA GB200 chip in opposition to the earlier technology NVIDIA H100 chip, decrease illustration FP8 efficiency has elevated 505%, however FP64 efficiency has solely elevated 265%. Likewise, within the forthcoming Trainium2 chip, the main target has been on lower-bit efficiency will increase, giving a 400% efficiency enhance over the earlier technology. Trying to the longer term, we’d anticipate to see a convergence between HPC and AI workloads, as AI begins to change into more and more vital in fixing what had been historically HPC FP64 precision issues.
Accelerator benchmarking
When contemplating compute providers, customers benchmark measures resembling price-performance, absolute efficiency, availability, latency, and throughput. Value-performance means how a lot compute could be completed for $1, or what’s the equal greenback price for a given variety of FP operations. For an ideal system, the price-performance ratio will increase linearly as the scale of a job scales up. A complicating issue when benchmarking compute grids on AWS is that EC2 situations are available a variety of system parameters and a grid would possibly comprise a couple of occasion sort, subsequently methods are benchmarked on the grid stage fairly than on a extra granular foundation. Customers typically need to full a job as rapidly as potential and on the lowest price; the constituent particulars of the system that achieves this aren’t as vital.
A second benchmarking measure is absolute-performance, that means how rapidly can a given job be accomplished unbiased of worth. Given linear scaling, job completion time could be diminished by merely including extra compute. Nevertheless, it could be that the job isn’t infinitely divisible, and that solely a single computational unit is required. On this case, absolutely the efficiency of that computational unit is vital. In an earlier part, we offered a desk with one efficiency measure, the $/TFLOP ratio based mostly on the chip specs. Nevertheless, as a rule of thumb, when such theoretical values are in contrast in opposition to experimental values, solely round 45% is realized.
There are just a few other ways to calculate price-performance. The primary is to make use of a normal benchmark, resembling LINPACK, HPL-MxP, or MFU (Mannequin FLOPS Utilization). These can run a variety of calculations which might be consultant of various use instances, resembling normal use, HPC, and blended HPC and AI workloads. From this, the TFLOP/s at a given FP precision for the system could be measured, together with the dollar-cost of operating the system. Nevertheless, it could be that the consumer has particular use instances in thoughts. On this case, the perfect knowledge will come from price-performance knowledge on a extra consultant benchmark.
There are numerous sorts of consultant benchmark generally seen. Firstly, the consumer can use actual manufacturing knowledge and purposes with the {hardware} being benchmarked. This feature provides essentially the most dependable outcomes, however could be troublesome to attain attributable to operational and compliance hurdles. Secondly, the consumer can replicate their current use case with an artificial knowledge generator, avoiding the challenges of getting manufacturing knowledge into new take a look at methods. Thirdly, the use can make use of a third-party benchmark for the use case, if one exists. For instance, STAC is an organization that coordinates an FSI neighborhood referred to as the STAC Benchmark Council, which keep a choice of accelerator benchmarks, together with A2, A3, ML and AI (LLM). A2 is designed for compute-intensive analytic workloads concerned in pricing and threat administration. Particularly, the A2 workload makes use of choice worth discovery by Monte Carlo estimation of Heston-based Greeks for a path-dependent, multi-asset choice with early train. STAC members can entry A2 benchmarking stories, for instance EC2 c5.metal, with the oneAPI. STAC-ML benchmarks the latency of NN inference—the time from receiving new enter knowledge till the mannequin output is computed. STAC-A3 benchmarks the backtesting of buying and selling algorithms to find out how methods would have carried out on historic knowledge. This benchmark helps accelerator parallelism to run many backtesting experiments concurrently, for a similar safety. For every benchmark, there exists a sequence of software program packages (termed STAC Packs), that are accelerator-API particular. For a number of the previous benchmarks, STAC Packs are maintained by suppliers resembling NVIDIA (CUDA) and Intel (oneAPI).
Some FSI market individuals are performing in-house benchmarking on the microarchitecture stage, with the intention to optimize efficiency so far as potential. Citadel has published microbenchmarks for NVIDIA GPU chips, dissecting the microarchitecture to attain “bare-metal efficiency tuning,” noting that peak efficiency is inaccessible to software program written in plain CUDA. Jane Street has checked out efficiency optimization by way of purposeful programming methods, whereas PDT Companions has supported work on the Nixpkgs repository of ML packages utilizing CUDA.
Some AWS clients have benchmarked the AWS PBAs in opposition to different EC2 occasion varieties. ByteDance, the know-how firm that runs the video-sharing app TikTok, benchmarked Inf1 in opposition to a comparable EC2 GPU occasion sort. With Inf1, they had been capable of scale back their inference latency by 25%, and prices by 65%. In a second instance, Inf2 is benchmarked in opposition to a comparable inference-optimized EC2 occasion. The benchmark used is the RoBERTa-Base, a well-liked mannequin utilized in pure language processing (NLP) purposes, that makes use of the transformer structure. Within the following determine, on the x-axis we plotted throughput (the variety of inferences which might be accomplished in a set time period), and on the y-axis we plotted latency (the time it takes the deep studying mannequin to supply an output). The determine exhibits that Inf2 provides increased throughput and decrease latency than the comparable EC2 occasion sort.

In a 3rd benchmark instance, Hugging Face benchmarked the trn1.32xlarge occasion (16 Trainium chips) and two comparable EC2 occasion varieties. For the primary occasion sort, they ran fine-tuning for the BERT Massive mannequin on the total Yelp overview dataset, utilizing the BF16 knowledge format with the utmost sequence size supported by the mannequin (512). The benchmark outcomes present the Trainium job is 5 instances quicker whereas being solely 30% dearer, leading to a “enormous enchancment in cost-performance.” For the latter occasion sort, they ran three checks: language pretraining with GPT2, token classification with BERT Massive, and picture classification with the Imaginative and prescient Transformer. These outcomes confirmed trn1 to be 2–5 instances quicker and three–8 instances cheaper than the comparable EC2 occasion varieties.
FSI use instances
As with different trade sectors, there are two the reason why FSI makes use of acceleration. The primary is to get a set end result within the lowest time potential, for instance parsing a dataset. The second is to get the perfect end in a set time, for instance in a single day parameter re-estimation. Use instances for acceleration exist throughout the FSI, together with banking, capital markets, insurance coverage, and funds. Nevertheless, essentially the most urgent demand comes from capital markets, as a result of acceleration accelerates workloads and time is likely one of the best edges individuals can get within the monetary markets. Put otherwise, a time benefit in monetary providers typically equates to an informational benefit.
We start by offering some definitions:
- Parsing is the method of changing between knowledge codecs
- Analytics is knowledge processing utilizing both deterministic or easy statistical strategies
- ML is the science of studying fashions from knowledge, utilizing a wide range of totally different strategies, after which making choices and predictions
- AI is an software capable of resolve issues utilizing ML
On this part, we overview a number of the FSI use instances of PBAs. As many FSI actions could be parallelized, most of what’s completed in FSI could be sped up with PBAs. This consists of most modeling, simulations, and optimization issues— presently in FSI, deep studying is just a small a part of the panorama. We determine 4 courses of FSI use instances and have a look at purposes in every class: parsing monetary knowledge, analytics on monetary knowledge, ML on monetary knowledge, and low-latency purposes. To attempt to present how these courses relate to one another, the next determine exhibits a simplified illustration of a typical capital market’s workflow. On this determine, acceleration classes have been assigned to the workflow steps. Nevertheless, in actuality, each step within the course of could possibly profit from a number of of the outlined acceleration classes.

Parsing
A typical capital markets workflow consists of receiving knowledge after which parsing it right into a useable type. This knowledge is often market knowledge, as output from a buying and selling venue’s matching engine, or onward from a market knowledge vendor. Market individuals who’re receiving both stay or historic knowledge feeds must ingest this knowledge and carry out a number of steps, resembling parse the message out of a binary protocol, rebuild the restrict order ebook (LOB), or mix a number of feeds right into a single normalized format. Any of those parsing steps that run in parallel could possibly be sped up relative to sequential processing. To offer an thought of scale, the most important monetary knowledge feed is the consolidated US fairness choices feed, termed OPRA. This feed comes from 18 totally different buying and selling venues, with 1.5 million contracts broadcast throughout 96 channels, with a supported peak message fee of 400 billion messages per day, equating to roughly 12 TB per day, or 3 PB per 12 months. In addition to sustaining real-time feeds, individuals want to keep up a historic depositary, generally of a number of years in dimension. Processing of historic repositories is finished offline, however is commonly a supply of main price. Total, a big client of market knowledge, resembling an funding financial institution, would possibly devour 200 feeds from throughout private and non-private buying and selling venues, distributors, and redistributors.
Any level on this knowledge processing pipeline that may be parallelized, can probably be sped up by acceleration. For instance:
- Buying and selling venues broadcast on channels, which could be groupings of alphabetical tickers or merchandise.
- On a given channel, totally different tickers replace messages are broadcast sequentially. These can then be parsed out into distinctive streams per ticker.
- For a given LOB, some occasions could be relevant to particular person worth ranges independently.
- Historic knowledge is generally (however not all the time) unbiased inter-day, that means that days could be parsed independently.
In GPU Accelerated Data Preparation for Limit Order Book Modeling, the authors describe a GPU pipeline dealing with knowledge assortment, LOB pre-processing, knowledge normalization, and batching into coaching samples. The authors notice their LOB pre-processing depends on the earlier LOB state, and have to be completed sequentially. For LOB constructing, FPGAs appear to be used extra generally than GPUs due to the fastened nature of the workload; see examples from Xilinx and Algo-Logic. For instance code for a construct lab, utilizing the AWS FPGA F1 occasion sort, seek advice from the next GitHub repo.
An vital a part of the info pipeline is the manufacturing of options, each on-line and offline. Options (additionally referred to as alphas, alerts, or predictors) are statistical representations of the info, which might then be utilized in downstream mannequin constructing. A present development within the FSI prediction area is the large-scale automation of dataset ingestion, curation, processing, function extraction, function mixture, and mannequin constructing. An example of this method is given by WorldQuant, an algorithmic buying and selling agency. The WSJ reports “an information group scours the globe for attention-grabbing and new knowledge units, together with every part from detailed market pricing knowledge to transport statistics to footfall in shops captured by apps on smartphones”. WorldQuant states “in 2007 we had two knowledge units—at this time [2022] we’ve got greater than 1,400.” The overall thought being if they may purchase, devour, create, and internet scrape extra knowledge than anybody else, they may create extra alphas, and discover extra alternatives. Such an method relies on performance being proportional to √N, the place N is the variety of alphas. Subsequently, so long as an alpha isn’t completely correlated with one other, there’s worth in including it to the set. In 2010, WorldQuant was producing several thousand alphas per 12 months, by 2016 had a million alphas, by 2022, had a number of hundreds of thousands, with a acknowledged ambition to get to 100 million alphas. Though conventional quant finance mandates the significance of an financial rationale behind an alpha, the data-driven method is led purely by the patterns within the knowledge. After alphas have been produced, they are often intelligently merged collectively in a time-variant method. Examples of sign mixture methodologies which might profit from PBA speed-up embody Mean Variance Optimization and Bayesian Model Averaging. The identical WSJ article states “Nobody alpha is vital. Our edge is placing issues collectively, it’s the implementation…. The concept is that with so many ‘alphas,’ even weak alerts could be helpful. If counting automobiles in parking tons subsequent to large field retailers has solely a tiny predictive energy for these retailers’ inventory costs, it will probably nonetheless be used to boost a much bigger prediction if mixed with different weak alerts. For instance, an uptick in automobiles at Walmart parking tons—itself a comparatively weak sign—might mix with comparable tendencies captured by cell phone apps and credit-card receipts harvested by firms that scan emails to create a extra dependable prediction.” The automated course of of information ingestion, processing, packaging, mixture, and prediction is referred to by WorldQuant as their “alpha manufacturing unit.”
From examples resembling these we’ve mentioned, it appears clear that parallelization, speed-up and scale-up, of such enormous knowledge pipelines is probably an vital differentiator. All through this pipeline, actions could possibly be accelerated utilizing PBAs. For instance, to be used on the sign mixture section, the Shapley value is a metric that can be utilized to compute the contribution of a given function to a prediction. Shapley worth computation has PBA-acceleration help within the Python XGBoost library.
Analytics
On this part, we take into account the applicability of accelerator parallelism to analytics workloads. One of many parallelizable dwarfs is Monte Carlo, and for FSI and time sequence work basically, this is a vital technique. Monte Carlo is a technique to compute anticipated values by producing random eventualities after which averaging them. Through the use of GPUs, a simulated path could be assigned to every thread, permitting simulation of 1000’s of paths in parallel.
Put up the 2008 credit score crunch, new rules require banks to run credit score valuation adjustment (CVA) calculations each 24 hours. CVA is an adjustment to a derivatives worth as charged by a financial institution to a counterparty. CVA is considered one of a household of associated valuation changes collectively often known as xVA, which embody debt valuation adjustment (DVA), preliminary margin valuation adjustment (MVA), capital valuation adjustment (KVA), and funding valuation adjustment (FVA). As a result of this adjustment calculation can occur over giant portfolios of complicated, non-linear devices, closed-form analytical options aren’t potential, and as such an empirical approximation by a method resembling Monte Carlo is required. The draw back of Monte Carlo right here is how computationally demanding it’s, because of the dimension of the search area. The appearance of this new regulation coincided with the approaching of age of GPUs, and as such banks generally use GPU grids to run their xVA calculations. In XVA principles, nested Monte Carlo strategies, and GPU optimizations, the authors discover a nested simulation time of about an hour for a billion eventualities on the financial institution portfolio, and a GPU speedup of 100 instances quicker relative to CPUs. Moderately than develop xVA purposes internally, banks typically use third-party unbiased software program vendor (ISV) options to run their xVA calculations, resembling Murex M3 or S&P Global XVA. Banking clients can select to run such ISV software program as a service (SaaS) options inside their very own AWS accounts, and sometimes on AWS accelerated situations.
A second use of PBAs in FSI Monte Carlo is in choice pricing, particularly for unique choices whose payoff is typically too complicated to unravel in closed-form. The core thought is utilizing a random quantity generator (RNG) to simulate the stochastic parts in a formulation after which common the outcomes, resulting in the anticipated worth. The extra paths which might be simulated, the extra correct the result’s. In Quasi-Monte Carlo methods for calculating derivatives sensitivities on the GPU, the authors discover 200-times larger speedup over CPUs, and moreover develop quite a few refinements to scale back variance, resulting in fewer paths needing to be simulated. In High Performance Financial Simulation Using Randomized Quasi-Monte Carlo Methods, the authors survey quasi Monte Carlo sequences in GPU libraries and overview business software program instruments to assist migrate Monte Carlo pricing fashions to GPU. In GPU Computing in Bayesian Inference of Realized Stochastic Volatility Model, the creator computes a volatility measure utilizing Hybrid Monte Carlo (HMC) utilized to realized stochastic volatility (RSV), parallelized on a GPU, leading to a 17-times quicker speedup. Lastly, in Derivatives Sensitivities Computation under Heston Model on GPU, the authors obtain a 200-times quicker speedup; nevertheless, the accuracy of the GPU technique is inferior for some Greeks relative to CPU.
A 3rd use of PBAs in FSI Monte Carlo is in LOB simulations. We will categorize various kinds of LOB simulations: replay of the general public historic knowledge, replay of the mapped public-private historic knowledge, replay of artificial LOB knowledge, and replay of a mixture of historic and artificial knowledge to simulate the consequences of a suggestions loop. For every of most of these simulation, there are a number of methods wherein {hardware} acceleration might happen. For instance, for the easy replay case, every accelerator thread might have a distinct LOB. For the artificial knowledge case, every thread might have a distinct model of the identical LOB, thereby permitting a number of realizations of a single LOB. In Limit Order Book Simulations: A Review, the authors present their very own simulator classification scheme based mostly on the mathematical modeling method used—level processes, agent based mostly, deep studying, stochastic differential equations. In JAX-LOB: A GPU-Accelerated limit order book simulator to unlock large scale reinforcement learning for trading, the authors use GPU accelerated coaching, processing 1000’s of LOBs in parallel, giving a “notably diminished per message processing time.”
Machine studying
Generative AI is essentially the most topical ML software at this time limit. Generative AI has 4 important purposes: classification, prediction, understanding, and knowledge technology, which in flip map to make use of instances resembling buyer expertise, data employee productiveness, surfacing info and sentiment, and innovation and automation. FSI examples exist for all of those; nevertheless, a radical overview of those is past the scope of this put up. For this put up, we stay centered on PBA applicability and have a look at two of those matters: chatbots and time sequence prediction.
The 2017, the publication of the paper Attention is all you need resulted in a brand new wave of curiosity in ML. The transformer structure offered on this paper allowed for a extremely parallelizable community construction, that means extra knowledge could possibly be processed than earlier than, permitting patterns to be higher captured. This has pushed spectacular real-world efficiency, as seen by common public basis fashions (FMs) resembling OpenAI ChatGPT, and Anthropic Claude. These components in flip have pushed new demand for PBAs for coaching and inference on these fashions.
FMs, additionally termed LLMs, or chatbots when textual content centered, are fashions which might be usually educated on a broad spectrum of generalized and unlabeled knowledge and are able to performing all kinds of normal duties in FSI, such because the Bridgewater Associates LLM-powered Funding Analyst Assistant, which generates charts, computes monetary indicators, and summarizes outcomes. FSI LLMs are reviewed in Large Language Models in Finance: A Survey and A Survey of Large Language Models for Financial Applications: Progress, Prospects and Challenges. FMs are sometimes used as base fashions for growing extra specialised downstream purposes.
PBAs are utilized in three various kinds of FM coaching. Firstly, to coach a FM from scratch. In BloombergGPT: A Large Language Model for Finance, the coaching dataset was 51% monetary knowledge from their methods and 49% public knowledge, resembling Wikipedia and Pile. SageMaker was used to coach and consider their FM. Particularly, 64 p4d.24xlarge situations, giving a complete of 512 A100 GPUs. Additionally used was SageMaker mannequin parallelism, enabling the automated distribution of the big mannequin throughout a number of GPU gadgets and situations. The authors began with a compute funds of 1.3 million GPU hours, and famous coaching took roughly 53 days.
The second coaching method is to fine-tune an current FM. This requires utilizing an FM whose mannequin parameters are uncovered, and updating them in gentle of recent knowledge. This method could be efficient when the info corpus differs considerably from the FM coaching knowledge. High quality-tuning is cheaper and faster than coaching FM from scratch, as a result of the amount of information is prone to be a lot smaller. As with the larger-scale coaching from scratch, fine-tuning advantages considerably from {hardware} acceleration. In an FSI instance, Efficient Continual Pre-training for Building Domain Specific Large Language Models, the authors fine-tune an FM and discover that their method outperforms normal continuous pre-training efficiency with simply 10% of the corpus dimension and value, with none degradation on open-domain normal duties.
The third coaching method is to carry out Retrieval Augmented Era (RAG). To equip FMs with up-to-date and proprietary info, organizations use RAG, a method that fetches knowledge from firm knowledge sources and enriches the immediate to supply extra related and correct responses. The 2-step workflow consists of ingesting knowledge and vectorizing knowledge, adopted by runtime orchestration. Though {hardware} acceleration is much less frequent in RAG purposes, latency of search is a key part and as such the inference step of RAG could be {hardware} optimized. For instance, the efficiency of OpenSearch, a vectorized database obtainable on AWS, could be improved by utilizing PBAs, with each NVIDIA GPUs and Inferentia being supported.
For these three coaching approaches, the function of PBAs varies. For processing the massive knowledge volumes of FM constructing, PBAs are important. Then, because the coaching volumes scale back, so does the value-add function of the PBA. Impartial of how the mannequin has been educated, PBAs have a key function in LLM inference, once more as a result of they’re optimized for reminiscence bandwidth and parallelism. The specifics of how you can optimally use an accelerator depend upon the use case—for instance, a paid-for-service chatbot could be latency delicate, whereas for a free model, a delay of some milliseconds could be acceptable. If a delay is appropriate, then batching the queries collectively might assist be certain that a given chip’s processes are saturated, giving higher greenback utilization of the useful resource. Greenback prices are significantly significance in inference, as a result of in contrast to coaching, which is a one-time price, inference is a reoccurring price.
Utilizing ML for monetary time sequence prediction is nothing new; a big physique of public analysis exists on these strategies and purposes relationship to the Nineteen Seventies and past—for about the final decade, PBAs have been utilized to this discipline. As mentioned earlier, most ML approaches could be accelerated with {hardware}; nevertheless, the attention-based structure utilizing the transformer mannequin is presently essentially the most topical. We take into account three areas of FSI software: time sequence FMs, NN for securities prediction, and reinforcement studying (RL).
The preliminary work on LLMs was carried out on text-based fashions. This was adopted by multi-modal fashions, capable of deal with photos and different knowledge buildings. Subsequent to this, publications have began to look on time sequence FMs, together with Amazon Chronos, Nixtla TimeGEN-1, and Google TimesFM. The conduct of the time sequence fashions seems to be just like that of the language fashions. For instance, in Scaling-laws for Large Time-series Models, the authors observe the fashions comply with the identical scaling legal guidelines. A overview of those fashions is offered in Foundation Models for Time Series Analysis: A Tutorial and Survey. As with main LLMs, time sequence FMs are prone to be efficiently educated on giant clusters of PBAs. When it comes to dimension, GPT-3 was trained on a cluster of 10,000 V100s. The scale of the GPT-4 coaching cluster isn’t public, however is imagined to have been educated on a cluster of 10,000–25,000 A100s. That is analogous in dimension to 1 algorithmic buying and selling agency’s statement, “our devoted analysis cluster incorporates … 25,000 A/V100 GPUs (and rising quick).”
Trying to the longer term, one potential consequence could be that point sequence FMs, educated at enormous expense by just a few giant corporates, change into the bottom fashions for all monetary prediction. Monetary providers companies then modify these FMs by way of further coaching with personal knowledge or their very own insights. Examples of personal labeled knowledge could be data of which orders and executions within the public feed belonged to them, or equally which (meta)orders and executions had parent-child relationships.
Though such monetary time sequence FMs educated on PBA clusters might provide enhanced predictive capabilities, additionally they convey dangers. For instance, the EU’s AI act, adopted in March 2024, states that if a mannequin has been educated with a complete compute energy in extra of 1025 FLOPs, then that mannequin is taken into account to pose “systemic threat” and is topic to enhanced regulation, together with fines of three% of worldwide turnover, so on this foundation Meta announced in June 2024 they won’t be enabling some fashions inside Europe. This laws assumes that coaching compute is a direct proxy for mannequin capabilities. EpochAI offers an evaluation of the coaching compute required for a variety of FMs; for instance, GPT-4 took 2.125 FLOPS to coach (exceeding the brink by an element of two.1), whereas BloombergGPT took 2.423 FLOPS (below the brink by an element of 0.02). It appears potential that sooner or later, comparable laws might apply to monetary FMs, and even to the PBA clusters themselves, with some market individuals selecting to not function in legislative regimes which might be topic to such dangers.
Function engineering performs a key function in constructing NN fashions, as a result of options are fed into the NN mannequin. As seen earlier on this put up, some individuals have generated giant numbers of options. Examples of options derived from market time sequence knowledge embody bid-ask spreads, weighted mid-points, imbalance measures, decompositions, liquidity predictions, trends, change-points, and mean-reversions. Collectively, the options are referred to as the function area. A transformer assigns extra significance to a part of the enter function area, despite the fact that it would solely be a small a part of the info. Studying which a part of the info is extra vital than one other relies on the context of the options. The true energy of FMs in time sequence prediction is the power to seize these conditional possibilities (the context) throughout the function area. To offer a easy instance, based mostly on historic knowledge, tendencies would possibly scale back in energy as they go on, resulting in a change-point, after which reversion to the imply. A transformer probably gives the power to acknowledge this sample and seize the connection between the options extra precisely than different approaches. An informative visualization of this for the textual case is given by the FT article Generative AI exists because of the transformer. To be able to construct and practice such FMs on PBAs, entry to high-quality historic knowledge tightly coupled with scalable compute to generate the options is an important prerequisite.
Previous to the appearance of the transformer, NN have traditionally been utilized to securities prediction with various levels of success. Deep Learning for Limit Order Books makes use of a cluster of fifty GPUs to foretell the signal of the longer term return by mapping the worth ranges of the LOB to the seen enter layer of a NN, leading to a trinomial output layer. Conditional on the return the signal, the magnitude of the return is estimated utilizing regression. Deep Learning Financial Market Data makes use of uncooked LOB knowledge pre-processed into discrete, fixed-length options for coaching a recurrent autoencoder, whose recurrent construction permits studying patterns on totally different time scales. Inference happens by producing the decoded LOB, and nearest-matching that to the real-time knowledge.
In Multi-Horizon Forecasting for Limit Order Books: Novel Deep Learning Approaches and Hardware Acceleration using Intelligent Processing Units, the authors benchmark the efficiency of Graphcore IPUs in opposition to an NVIDIA GPU on an encoder-decoder NN mannequin. On condition that encoder-decoder fashions depend on recurrent neural layers, they typically endure from sluggish coaching processes. The authors handle this by discovering that the IPU gives a major coaching speedup over the GPU, 694% on common, analogous to the speedup a transformer structure would offer. In some examples of post-transformer work on this area, Generative AI for End-to-End Limit Order Book Modelling and A Generative Model Of A Limit Order Book Using Recurrent Neural Networks have educated LLM analogues on historic LOB knowledge, deciphering every LOB occasion (resembling insertions, cancellations, and executions) as a phrase and predicting the sequence of occasions following a given phrase historical past. Nevertheless, the authors discover the prediction horizon for LOB dynamics seems to be restricted to a couple tens of occasions, presumably due to the high-dimensionality of the issue and the presence of long-range correlations so as signal. These outcomes have been improved within the work “Microstructure Modes” — Disentangling the Joint Dynamics of Prices & Order Flow, by down-sampling the info and lowering its dimensionality, permitting identification of secure parts.
RL is an ML method the place an algorithm interacts with a dynamic setting that gives suggestions to the algorithm, permitting the algorithm to iteratively optimize a reward metric. As a result of RL intently mimics how human merchants work together with the world, there are numerous areas of applicability in FSI. In JAX-LOB: A GPU-Accelerated limit order book simulator to unlock large scale reinforcement learning for trading, the authors use GPUs for end-to-end RL coaching. RL agent coaching with a GPU has a 7-times speedup relative to a CPU based mostly simulation implementation. The authors then apply this to the issue of optimum commerce execution. A second FSI software of RL to optimum commerce execution has been reported by JPMorgan in an algorithm referred to as LOXM.
Latency-sensitive, real-time workloads
Having the ability to transmit, course of, and act on knowledge extra rapidly than others provides an informational benefit. Within the monetary markets, that is immediately equal to having the ability to revenue from buying and selling. These real-time, latency-sensitive workloads exist on a spectrum, from essentially the most delicate to the least delicate. The particular numbers within the following desk are open to debate, however current the overall thought.
| Band | Latency | Utility Examples |
| 1 | Lower than 1 microsecond | Low-latency buying and selling technique. Tick 2 commerce. |
| 2 | 1–4 microseconds | Feed handler. Uncooked or normalized format. |
| 3 | 40 microseconds | Normalized format and symbology. |
| 4 | 4–200 milliseconds | Consolidated feed. Full tick. |
| 5 | 1 second to day by day | Intraday and EOD. Reference, Corp, FI, derivatives. |
Probably the most latency-sensitive use instances are usually dealt with by FPGA or customized ASICs. These react to incoming community visitors, like market knowledge, and put triggering logic immediately into the community interface controller. Simply reprogrammable PBAs play little to no function in any latency delicate work, because of the SIMD structure being designed for the use case of parallel processing giant quantities of information with a bandwidth bottleneck of getting knowledge onto the chip.
Nevertheless, three components possibly driving change within the function {hardware} acceleration performs within the low-latency area. Firstly, as PBAs mature, a few of their earlier limitations are being diminished. For instance, NVIDIA’s new NVLink design now permits considerably increased bandwidth relative to earlier chip interconnects, that means that knowledge can get onto the chip much more rapidly than earlier than. Evaluating the newest NVIDIA GB200 chip in opposition to the earlier technology NVIDIA H100 chip, NVLink efficiency has elevated 400%, from 900 GBps to three.6 TBps.
Secondly, some observers imagine the race for velocity is shifting to a “race for intelligence.” With roughly solely ten main companies competing within the top-tier low latency area, the barrier to entry appears nearly unsurmountable for different events. Sooner or later, low-latency {hardware} and methods would possibly slowly diffuse by way of know-how provider choices, finally leveling the taking part in discipline, maybe having been pushed by new rules.
Thirdly, though FPGA/ASIC undoubtedly offers the quickest efficiency, they arrive at a value of being a drain on assets. Their builders are laborious to rent for, the work has lengthy deployment cycles, and it ends in a major upkeep burden with bugs which might be troublesome to diagnose and triage. Corporations are eager to determine options.
Though essentially the most latency-sensitive work will stay on FPGA/ASIC, there could also be a shift of much less latency-sensitive work from FPGA/ASIC to GPUs and different PBAs as customers weigh the trade-off between velocity and different components. As compared, simply reprogrammable PBA processors are actually easy to rent for, are simple to code in opposition to and keep, and permit for comparatively speedy innovation. Trying to the longer term, we might even see innovation on the language stage, for instance, by way of purposeful programming with array-languages such because the Co-dfns undertaking, in addition to additional innovation on the {hardware} stage, with future chips tightly integrating the perfect parts of at this time’s FPGAs, GPUs and CPUs.
Key Takeaways
On this part, we current three key takeaways. Firstly, the worldwide supply-demand ratio for GPUs is low, that means worth could be excessive, however availability could be low. This generally is a constraining issue for end-user companies desirous to innovate on this area. AWS helps handle this on behalf of its clients in 3 ways:
- By economies of scale, AWS is ready to provide vital availability of the PBAs, together with GPUs.
- By in-house analysis and growth, AWS is ready to provide its personal PBAs, developed and manufactured in-house, which aren’t topic to the constraints of the broader market, whereas additionally having optimized price-performance.
- AWS innovates on the software program stage to enhance allocation to the end-user. Subsequently, though complete capability could be fastened, by utilizing clever allocation algorithms, AWS is best capable of meet clients’ wants. For instance, Amazon EC2 Capacity Blocks for ML permits assured entry to the required PBAs on the time limit they’re wanted.
The second takeaway is that proprietary software program can lock customers in to a single provider and find yourself performing as a barrier to innovation. Within the case of PBAs, the chips that use proprietary software program imply that customers can’t simply transfer between chip producers, versus open supply software program supporting a number of chip producers. Any future provide constraints, resembling regional armed battle, might additional exasperate current supply-demand imbalances. Though migrating current legacy workloads from an acceleration chip with proprietary software program could be difficult, new greenfield workloads could be constructed on open supply libraries with out issue. Within the FSI area, examples of legacy workloads would possibly embody threat calculations, and examples of greenfield workloads would possibly embody time sequence prediction utilizing FMs. In the long run, enterprise leaders want to contemplate and formulate their technique for shifting away from software program lock-in, and allow entry to wider acceleration {hardware} choices, with the price advantages that may convey.
The ultimate takeaway is that monetary providers, and the subsection of capital markets specifically, is topic to fixed and evolving aggressive pressures. Over time, the trade has seen the race for differentiation transfer from knowledge entry rights, to latency, and now to an elevated give attention to predictive energy. Trying to the longer term, if the world of economic prediction relies partially on a small variety of costly and sophisticated FMs constructed and educated by just a few giant world corporates, the place will the differentiation come from? Speculative areas might vary from at-scale function engineering to having the ability to higher deal with elevated regulatory burdens. Whichever discipline it comes from, it’s sure to incorporate knowledge processing and analytics at its core, and subsequently profit from {hardware} acceleration.
Conclusion
This put up aimed to supply enterprise leaders with a non-technical overview of PBAs and their function inside the FSI. With this know-how presently being often mentioned within the mainstream media, it’s important enterprise leaders perceive the premise of this know-how and its potential future function. Almost each group is now seeking to a data-centric future, enabled by cloud-based infrastructure and real-time analytics, to help revenue-generating AI and ML use instances. One of many methods organizations can be differentiated on this race can be by making the proper strategic choices about applied sciences, companions, and approaches. This consists of matters resembling open supply versus closed supply, construct versus purchase, instrument complexity and related ease of use, hiring and retention challenges, and price-performance. Such matters should not simply know-how choices inside a enterprise, but in addition cultural and strategic ones.
Enterprise leaders are inspired to succeed in out to their AWS level of contact and ask how AWS may also help their enterprise win in the long run utilizing PBAs. This would possibly end in a variety of outcomes, from a brief proof of idea in opposition to an current well-defined enterprise downside, to a written technique doc that may be consumed and debated by friends, to onsite technical workshops and enterprise briefing days. Regardless of the consequence, the way forward for this area is bound to be thrilling!
Acknowledgements
I want to thank the next events for his or her form enter and steering in scripting this put up: Andrea Rodolico, Alex Kimber, and Shruti Koparkar. Any errors are mine alone.
Concerning the Creator
 Dr. Hugh Christensen works at Amazon Net Providers with a specialization in knowledge analytics. He holds undergraduate and grasp’s levels from Oxford College, the latter in computational biophysics, and a PhD in Bayesian inference from Cambridge College. Hugh’s areas of curiosity embody time sequence knowledge, knowledge technique, knowledge management, and utilizing analytics to drive income technology. You’ll be able to join with Hugh on LinkedIn.
Dr. Hugh Christensen works at Amazon Net Providers with a specialization in knowledge analytics. He holds undergraduate and grasp’s levels from Oxford College, the latter in computational biophysics, and a PhD in Bayesian inference from Cambridge College. Hugh’s areas of curiosity embody time sequence knowledge, knowledge technique, knowledge management, and utilizing analytics to drive income technology. You’ll be able to join with Hugh on LinkedIn.





