Catalog, question, and search audio packages with Amazon Transcribe and Information Bases for Amazon Bedrock
Info retrieval methods have powered the knowledge age by their capability to crawl and sift by large quantities of information and rapidly return correct and related outcomes. These methods, corresponding to search engines like google and databases, usually work by indexing on key phrases and fields contained in information information.
Nonetheless, a lot of our information within the digital age additionally is available in non-text format, corresponding to audio and video information. Discovering related content material often requires looking out by text-based metadata corresponding to timestamps, which should be manually added to those information. This may be exhausting to scale as the quantity of unstructured audio and video information continues to develop.
Happily, the rise of synthetic intelligence (AI) options that may transcribe audio and supply semantic search capabilities now provide extra environment friendly options for querying content material from audio information at scale. Amazon Transcribe is an AWS AI service that makes it simple to transform speech to textual content. Amazon Bedrock is a totally managed service that provides a alternative of high-performing basis fashions (FMs) from main AI corporations by a single API, together with a broad set of capabilities to construct generative AI purposes with safety, privateness, and accountable AI.
On this submit, we present how Amazon Transcribe and Amazon Bedrock can streamline the method to catalog, question, and search by audio packages, utilizing an instance from the AWS re:Think podcast collection.
Resolution overview
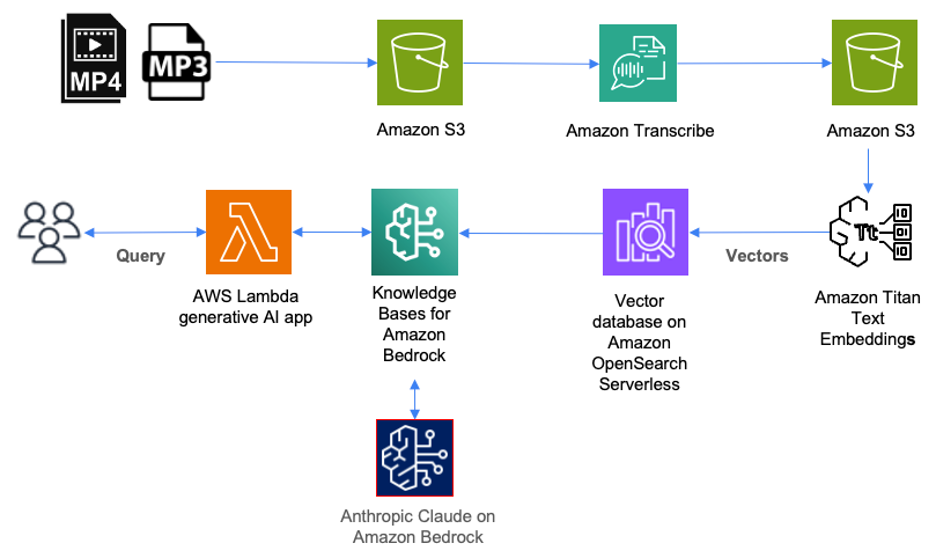
The next diagram illustrates how you should utilize AWS providers to deploy an answer for cataloging, querying, and looking out by content material saved in audio information.

On this answer, audio information saved in mp3 format are first uploaded to Amazon Simple Storage Service (Amazon S3) storage. Video information (corresponding to mp4) that comprise audio in supported languages can be uploaded to Amazon S3 as a part of this answer. Amazon Transcribe will then transcribe these information and retailer the whole transcript in JSON format as an object in Amazon S3.
To catalog these information, every JSON file in Amazon S3 ought to be tagged with the corresponding episode title. This enables us to later retrieve the episode title for every question consequence.
Subsequent, we use Amazon Bedrock to create numerical representations of the content material inside every file. These numerical representations are additionally referred to as embeddings, they usually’re saved as vectors inside a vector database that we will later question.
Amazon Bedrock is a totally managed service that makes FMs from main AI startups and Amazon accessible by an API. Included with Amazon Bedrock is Knowledge Bases for Amazon Bedrock. As a totally managed service, Information Bases for Amazon Bedrock makes it simple to arrange a Retrieval Augmented Technology (RAG) workflow.
With Information Bases for Amazon Bedrock, we first arrange a vector database on AWS. Information Bases for Amazon Bedrock can then robotically break up the information information saved in Amazon S3 into chunks after which create embeddings of every chunk utilizing Amazon Titan on Amazon Bedrock. Amazon Titan is a household of high-performing FMs from Amazon. Included with Amazon Titan is Amazon Titan Text Embeddings, which we use to create the numerical illustration of the textual content inside every chunk and retailer them in a vector database.
When a person queries the contents of the audio information by a generative AI software or AWS Lambda operate, it makes an API name to Information Bases for Amazon Bedrock. Information Bases for Amazon Bedrock will then orchestrate a name to the vector database to carry out a semantic search, which returns probably the most related outcomes. Subsequent, Information Bases for Amazon Bedrock augments the person’s authentic question with these outcomes to a immediate, which is shipped to the massive language mannequin (LLM). The LLM will return outcomes which might be extra correct and related to the person question.
Let’s stroll by an instance of how one can catalog, question, and search by a library of audio information utilizing these AWS AI providers. For this submit, we use episodes of the re:Suppose podcast collection, which has over 20 episodes. Every episode is an audio program recorded in mp3 format. As we proceed so as to add new episodes, we’ll need to use AI providers to make the duty of querying and looking for particular content material extra scalable with out the necessity to manually add metadata for every episode.
Conditions
Along with gaining access to AWS providers by the AWS Management Console, you want a couple of different assets to deploy this answer.
First, you want a library of audio information to catalog, question, and search. For this submit, we use episodes of the AWS re:Think podcast collection.
To make API calls to Amazon Bedrock from our generative AI software, we use Python model 3.11.4 and the AWS SDK for Python (Boto3).
Transcribe audio information
The primary activity is to transcribe every mp3 file utilizing Amazon Transcribe. For directions on transcribing with the AWS Administration Console or AWS CLI, discuss with the Amazon Transcribe Developer guide. Amazon Transcribe can create a transcript for every episode and retailer it as an S3 object in JSON format.
Catalog audio information utilizing tagging
To catalog every episode, we tag the S3 object for every episode with the corresponding episode title. For directions on tagging objects in S3, discuss with the Amazon Simple Storage Service User Guide. For instance, for the S3 object AI-Accelerators.json, we tag it with key = “title” and worth = “Episode 20: AI Accelerators within the Cloud.”

The title is the one metadata we have to manually add for every audio file. There isn’t any must manually add timestamps for every chapter or part as a way to later seek for particular content material.
Arrange a vector database utilizing Information Bases for Amazon Bedrock
Subsequent, we arrange our absolutely managed RAG workflow utilizing Information Bases for Amazon Bedrock. For directions on making a data base, discuss with the Amazon Bedrock User Guide. We start by specifying an information supply. In our case, we select the S3 bucket location the place our transcripts in JSON format are saved.

Subsequent, we choose an embedding mannequin. The embedding mannequin will convert every chunk of our transcript into embeddings. Embeddings are numbers, and the that means of every embedding is determined by the mannequin. In our instance, we choose Titan Textual content Embeddings v2 with a dimension dimension of 1024.

The embeddings are saved as vectors in a vector database. You’ll be able to both specify an present vector database you have got already created or have Information Bases for Amazon Bedrock create one for you. For our instance, we’ve Information Bases for Amazon Bedrock create a vector database utilizing Amazon OpenSearch Serverless.

Earlier than you possibly can question the vector database, you need to first sync it with the information supply. Throughout every sync operation, Information Bases for Amazon Bedrock will break up the information supply into chunks after which use the chosen embedding mannequin to embed every chunk as a vector. Information Bases for Amazon Bedrock will then retailer these vectors within the vector database.
The sync operation in addition to different Amazon Bedrock operations described up to now will be carried out both utilizing the console or API calls.
Question the audio information
Now we’re prepared to question and seek for particular content material from our library of podcast episodes. In episode 20, titled “AI Accelerators within the Cloud,” our visitor Matthew McClean, a senior supervisor from AWS’s Annapurna crew, shared why AWS determined to purchase Annapurna Labs in 2015. For our first question, we ask, “Why did AWS purchase Annapurna Labs?”
We entered this question into Information Bases for Amazon Bedrock utilizing Anthropic Claude and obtained the next response:
“AWS acquired Annapurna Labs in 2015 as a result of Annapurna was offering AWS with nitro playing cards that offloaded virtualization, safety, networking and storage from EC2 cases to unlock CPU assets.”
That is an actual quote from Matthew McClean within the podcast episode. You wouldn’t get this quote should you had entered the identical immediate into different publicly accessible generative AI chatbots as a result of they don’t have the vector database with embeddings of the podcast transcript to supply extra related context.
Retrieve an episode title
Now let’s suppose that along with getting extra related responses, we additionally need to retrieve the proper podcast episode title that was related to this question from our catalog of podcast episodes.
To retrieve the episode title, we first use probably the most related information chunk from the question. Every time Information Bases for Amazon Bedrock responds to a question, it additionally gives a number of chunks of information that it retrieved from the vector database that have been most related to the question so as of relevance. We will take the primary chunk that was returned. These chunks are returned as JSON paperwork. Nested contained in the JSON is the S3 location of the transcript object. In our instance, the S3 location is s3://rethinkpodcast/textual content/transcripts/AI-Accelerators.json.
The primary phrases within the chunk textual content are: “Yeah, positive. So perhaps I can begin with the historical past of Annapurna…”
As a result of we’ve already tagged this transcript object in Amazon S3 with the episode title, we will retrieve the title by retrieving the worth of the tag the place key = “title”. On this case, the title is “Episode 20: AI Accelerators within the Cloud.”
Search the beginning time
What if we additionally need to search and discover the beginning time contained in the episode the place the related content material begins? We need to accomplish that with out having to manually learn by the transcript or hearken to the episode from the start, and with out manually including timestamps for each chapter.
We will discover the beginning time a lot quicker by having our generative AI software make a couple of extra API calls. We begin by treating the chunk textual content as a substring of the whole transcript. We then seek for the beginning time of the primary phrase within the chunk textual content.
In our instance, the primary phrases returned have been “Yeah, positive. So perhaps I can begin with the historical past of Annapurna…” We now want to look the whole transcript for the beginning time of the phrase “Yeah.”
Amazon Transcribe outputs the beginning time of each phrase within the transcript. Nonetheless, any phrase can seem greater than as soon as. The phrase “Yeah” happens 28 instances within the transcript, and every prevalence has its personal begin time. So how can we decide the proper begin time for “Yeah” in our instance?
There are a number of approaches an software developer can use to search out the proper begin time. For our instance, we use the Python string discover() technique to search out the place of the chunk textual content inside the complete transcript.
For the chunk textual content that begins with “Yeah, positive. So perhaps I can begin with the historical past of Annapurna…” the discover() technique returned the place as 2047. If we deal with the transcript as one lengthy textual content string, the chunk “Yeah, positive. So perhaps…” begins at character place 2047.
Discovering the beginning time now turns into a matter of counting the character place of every phrase within the transcript and utilizing it to lookup the proper begin time from the transcript file generated by Amazon Transcribe. This can be tedious for an individual to do manually, however trivial for a pc.
In our instance Python code, we loop by an array that comprises the beginning time for every token whereas counting the variety of the character place that every token begins at. As a result of we’re looping by the tokens, we will construct a brand new array that shops the beginning time for every character place.
On this instance question, the beginning time for the phrase “Yeah” at place 2047 is 160 seconds, or 2 minutes and 40 seconds into the podcast. You’ll be able to examine the recording beginning at 2 minutes 40 seconds.
Clear up
This answer incurs expenses based mostly on the providers you utilize:
- Amazon Transcribe operates beneath a pay-as-you-go pricing mannequin. For extra particulars, see Amazon Transcribe Pricing.
- Amazon Bedrock makes use of an on-demand quota, so that you solely pay for what you utilize. For extra data, discuss with Amazon Bedrock pricing.
- With OpenSearch Serverless, you solely pay for the assets consumed by your workload.
- If you happen to’re utilizing Information Bases for Amazon Bedrock with different vector databases apart from OpenSearch Serverless, you might proceed to incur expenses even when not working any queries. It is suggested you delete your data base and its related vector retailer together with audio information saved in Amazon S3 to keep away from pointless prices whenever you’re finished testing this answer.
Conclusion
Cataloging, querying, and looking out by giant volumes of audio information will be tough to scale. On this submit, we confirmed how Amazon Transcribe and Information Bases for Amazon Bedrock can assist automate and make the method of retrieving related data from audio information extra scalable.
You’ll be able to start transcribing your personal library of audio information with Amazon Transcribe. To be taught extra on how Information Bases for Amazon Bedrock can then orchestrate a RAG workflow to your transcripts with vector shops, discuss with Knowledge Bases now delivers fully managed RAG experience in Amazon Bedrock.
With the assistance of those AI providers, we will now develop the frontiers of our data bases.
Concerning the Writer

Nolan Chen is a Companion Options Architect at AWS, the place he helps startup corporations construct revolutionary options utilizing the cloud. Previous to AWS, Nolan specialised in information safety and serving to prospects deploy high-performing huge space networks. Nolan holds a bachelor’s diploma in Mechanical Engineering from Princeton College.





