Monks boosts processing velocity by 4 occasions for real-time diffusion AI picture technology utilizing Amazon SageMaker and AWS Inferentia2
This publish is co-written with Benjamin Moody from Monks.
Monks is the worldwide, purely digital, unitary working model of S4Capital plc. With a legacy of innovation and specialised experience, Monks combines a unprecedented vary of worldwide advertising and marketing and know-how companies to speed up enterprise potentialities and redefine how manufacturers and companies work together with the world. Its integration of methods and workflows delivers unfettered content material manufacturing, scaled experiences, enterprise-grade know-how and knowledge science fueled by AI—managed by the trade’s finest and most various digital expertise—to assist the world’s trailblazing firms outmaneuver and outpace their competitors.
Monks leads the way in which in crafting cutting-edge model experiences. We form fashionable manufacturers by way of revolutionary and forward-thinking options. As model expertise specialists, we harness the synergy of technique, creativity, and in-house manufacturing to ship distinctive outcomes. Tasked with utilizing the newest developments in AWS companies and machine studying (ML) acceleration, our group launched into an bold challenge to revolutionize real-time picture technology. Particularly, we centered on utilizing AWS Inferentia2 chips with Amazon SageMaker to boost the efficiency and cost-efficiency of our picture technology processes..
Initially, our setup confronted important challenges relating to scalability and price administration. The first points have been sustaining constant inference efficiency beneath various masses, whereas offering generative expertise for the end-user. Conventional compute sources weren’t solely pricey but in addition failed to satisfy the low latency necessities. This situation prompted us to discover extra superior options from AWS that might provide high-performance computing and cost-effective scalability.
The adoption of AWS Inferentia2 chips and SageMaker asynchronous inference endpoints emerged as a promising resolution. These applied sciences promised to deal with our core challenges by considerably enhancing processing velocity (AWS Inferentia2 chips have been 4 occasions quicker in our preliminary benchmarks) and lowering prices by way of absolutely managed auto scaling inference endpoints.
On this publish, we share how we used AWS Inferentia2 chips with SageMaker asynchronous inference to optimize the efficiency by 4 occasions and obtain a 60% discount in value per picture for our real-time diffusion AI picture technology.
Resolution overview
The mixture of SageMaker asynchronous inference with AWS Inferentia2 allowed us to effectively deal with requests that had massive payloads and lengthy processing occasions whereas sustaining low latency necessities. A prerequisite was to fine-tune the Steady Diffusion XL mannequin with domain-specific photographs which have been saved in Amazon Simple Storage Service (Amazon S3). For this, we used Amazon SageMaker JumpStart. For extra particulars, confer with Fine-Tune a Model.
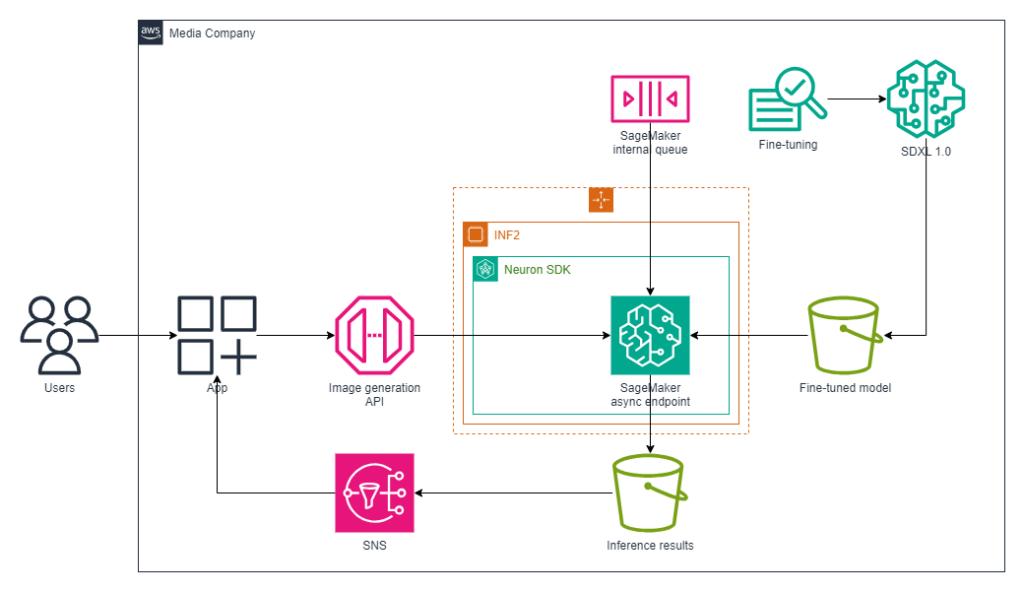
The answer workflow consists of the next elements:
- Endpoint creation – We created an asynchronous inference endpoint utilizing our present SageMaker fashions, utilizing AWS Inferentia2 chips for larger worth/efficiency.
- Request dealing with – Requests have been queued by SageMaker upon invocation. Customers submitted their picture technology requests, the place the enter payload was positioned in Amazon S3. SageMaker then queued the request for processing.
- Processing and output – After processing, the outcomes have been saved again in Amazon S3 in a specified output bucket. In periods of inactivity, SageMaker mechanically scaled the occasion rely to zero, considerably lowering prices as a result of expenses solely occurred when the endpoint was actively processing requests.
- Notifications – Completion notifications have been arrange by way of Amazon Simple Notification Service (Amazon SNS), notifying customers of success or errors.
The next diagram illustrates our resolution structure and course of workflow.

Within the following sections, we focus on the important thing elements of the answer in additional element.
SageMaker asynchronous endpoints
SageMaker asynchronous endpoints queue incoming requests to course of them asynchronously, which is good for big inference payloads (as much as 1 GB) or inference requests with lengthy processing occasions (as much as 60 minutes) that must be processed as requests arrive. The flexibility to serve long-running requests enabled Monks to successfully serve their use case. Auto scaling the occasion rely to zero permits you to design cost-optimal inference in response to spiky site visitors, so that you solely pay for when the cases are serving site visitors. You may also scale the endpoint occasion rely to zero within the absence of excellent requests and reduce up when new requests arrive.
To learn to create a SageMaker asynchronous endpoint, connect auto scaling insurance policies, and invoke an asynchronous endpoint, confer with Create an Asynchronous Inference Endpoint.
AWS Inferentia2 chips, which powered the SageMaker asynchronous endpoints, are AWS AI chips optimized to ship excessive efficiency for deep studying inference purposes at lowest value. Built-in inside SageMaker asynchronous inference endpoints, AWS Inferentia2 chips help scale-out distributed inference with ultra-high-speed connectivity between chips. This setup was ultimate for deploying our large-scale generative AI mannequin throughout a number of accelerators effectively and cost-effectively.
Within the context of our high-profile nationwide marketing campaign, the usage of asynchronous computing was key in managing peak and surprising spikes in concurrent requests to our inference infrastructure, which was anticipated to be within the a whole bunch of concurrent requests per second. Asynchronous inference endpoints, like these offered by SageMaker, provide dynamic scalability and environment friendly process administration.
The answer provided the next advantages:
- Environment friendly dealing with of longer processing occasions – SageMaker asynchronous inference endpoints are excellent for situations the place every request would possibly contain substantial computational work. These absolutely managed endpoints queue incoming inference requests and course of them asynchronously. This technique was significantly advantageous in our software, as a result of it allowed the system to handle fluctuating demand effectively. The flexibility to course of requests asynchronously makes positive our infrastructure can deal with massive surprising spikes in site visitors with out inflicting delays in response occasions.
- Value-effective useful resource utilization – One of the vital important benefits of utilizing asynchronous inference endpoints is their influence on value administration. These endpoints can mechanically scale the compute sources right down to zero in durations of inactivity, with out the chance of dropping or dropping requests as sources reduce up.
Customized scaling insurance policies utilizing Amazon CloudWatch metrics
SageMaker endpoint auto scaling conduct is outlined by way of the usage of a scaling coverage, which helps us scale to a number of customers utilizing the applying concurrently This coverage defines how and when to scale sources up or down to offer optimum efficiency and cost-efficiency.
SageMaker synchronous inference endpoints are sometimes scaled utilizing the InvocationsPerInstance metric, which helps decide occasion triggers primarily based on real-time calls for. Nonetheless, for SageMaker asynchronous endpoints, this metric isn’t out there resulting from their asynchronous nature.
We encountered challenges with various metrics reminiscent of ApproximateBacklogSizePerInstance as a result of they didn’t meet our real-time necessities. The inherent delay in these metrics resulted in unacceptable latency in our scaling processes.
Consequently, we sought a customized metric that might extra precisely mirror the real-time load on our SageMaker cases.
Amazon CloudWatch customized metrics present a robust device for monitoring and managing your purposes and companies within the AWS Cloud.
We had beforehand established a variety of customized metrics to observe numerous points of our infrastructure, together with a very essential one for monitoring cache misses throughout picture technology. Because of the nature of asynchronous endpoints, which don’t present the InvocationsPerInstance metric, this practice cache miss metric turned important. It enabled us to gauge the variety of requests contributing to the scale of the endpoint queue. With this perception into the variety of requests, one in every of our senior builders started to discover further metrics out there by way of CloudWatch to calculate the asynchronous endpoint capability and utilization fee. We used the next calculations:
InferenceCapacity= (CPU utilization * 60) / (InferenceTimeInSeconds*InstanceGPUCount)- Variety of inference requests = (served from cache + cache misses)
- Utilization fee = (variety of requests) / (
InferenceCapacity)
The calculations included the next variables:
- CPU utilization – Represents the typical CPU utilization proportion of the SageMaker cases (
CPUUtilizationCloudWatch metric). It gives a snapshot of how a lot CPU sources are at the moment being utilized by the cases. - InferenceCapacity – The full variety of inference duties that the system can course of per minute, calculated primarily based on the typical CPU utilization and scaled by the variety of GPUs out there (inf2.48xlarge has 12 GPUs). This metric gives an estimate of the system’s throughput functionality per minute.
- Multiply by 60 / Divide by InferenceTimeInSeconds – This step successfully adjusts the
CPUUtilizationmetric to mirror the way it interprets into jobs per minute, assuming every job takes 10 seconds. Due to this fact, (CPU utilization * 60) / 10 represents the theoretical most variety of jobs that may be processed in a single minute primarily based on present or typical CPU utilization. - Multiply by 12 – As a result of the inf2.48xlarge occasion has 12 GPUs, this multiplication gives a complete capability by way of what number of jobs all GPUs can deal with collectively in 1 minute.
- Multiply by 60 / Divide by InferenceTimeInSeconds – This step successfully adjusts the
- Variety of inference requests (served from cache + cache misses) – We monitor the overall variety of inference requests processed, distinguishing between these served from cache and people requiring real-time processing resulting from cache misses. This helps us gauge the general workload.
- Utilization fee (variety of inference requests) / (InferenceCapacity) – This method determines the speed of useful resource utilization by evaluating the variety of operations that invoke new duties (variety of requests) to the overall inference capability (
InferenceCapacity).
The next InferenceCapacity worth means that we’ve both scaled up our sources or that our cases are under-utilized. Conversely, a decrease capability worth might point out that we’re reaching our capability limits and would possibly have to scale out to take care of efficiency.
Our customized utilization fee metric quantifies the utilization fee of accessible SageMaker occasion capability. It’s a composite measure that components in each the picture technology duties that weren’t served from cache and those who resulted in a cache miss, relative to the overall capability metric. The utilization fee is meant to offer insights into how a lot of the overall provisioned SageMaker occasion capability is actively getting used for picture technology operations. It serves as a key indicator of operational effectivity and helps determine the workload’s operational calls for.
We then used the utilization fee metric as our auto scaling set off metric. The usage of this set off in our auto scaling coverage made positive SageMaker cases have been neither over-provisioned nor under-provisioned. A excessive worth for utilization fee would possibly point out the necessity to scale up sources to take care of efficiency. A low worth, alternatively, might sign under-utilization, indicating a possible for value optimization by cutting down sources.
We utilized our customized metrics as triggers for a scaling coverage:
Deployment on AWS Inferentia2 chips
The combination of AWS Inferentia2 chips into our SageMaker inference endpoints not solely resulted in a four-times enhance in inference efficiency for our finely-tuned Steady Diffusion XL mannequin, but in addition considerably enhanced cost-efficiency. Particularly, SageMaker cases powered by these chips diminished our deployment prices by 60% in comparison with different comparable cases on AWS. This substantial discount in value, coupled with improved efficiency, underscores the worth of utilizing AWS Inferentia2 for intensive computational duties reminiscent of real-time diffusion AI picture technology.
Given the significance of swift response occasions for our particular use case, we established an acceptance criterion of single digit second latency.
SageMaker cases geared up with AWS Inferentia2 chips efficiently optimized our infrastructure to ship picture technology in simply 9.7 seconds. This enhancement not solely met our efficiency necessities at a low value, but in addition offered a seamless and fascinating consumer expertise owing to the excessive availability of Inferentia2 chips.
The trouble to combine with the Neuron SDK additionally proved extremely helpful. The optimized mannequin not solely met our efficiency standards, but in addition enhanced the general effectivity of our inference processes.
Outcomes and advantages
The implementation of SageMaker asynchronous inference endpoints considerably enhanced our structure’s potential to deal with various site visitors masses and optimize useful resource utilization, resulting in marked enhancements in efficiency and cost-efficiency:
- Inference efficiency – The AWS Inferentia2 setup processed a mean of 27,796 photographs per occasion per hour, giving us 2x enchancment in throughput over comparable accelerated compute cases.
- Inference financial savings – Along with efficiency enhancements, the AWS Inferentia2 configurations achieved a 60% discount in value per picture in comparison with the unique estimation. The fee for processing every picture with AWS Inferentia2 was $0.000425. Though the preliminary requirement to compile fashions for the AWS Inferentia2 chips launched an extra time funding, the substantial throughput positive factors and important value reductions justified this effort. For demanding workloads that necessitate excessive throughput with out compromising finances constraints, AWS Inferentia2 cases are definitely worthy of consideration.
- Smoothing out site visitors spikes – We successfully smoothed out spikes in site visitors to offer continuous real-time expertise for end-users. As proven within the following determine, the SageMaker asynchronous endpoint auto scaling and managed queue is stopping important drift from our objective of single digit second latency per picture technology.

- Scheduled scaling to handle demand – We are able to scale up and again down on schedule to cowl extra predictable site visitors calls for, lowering inference prices whereas supplying demand. The next determine illustrates the influence of auto scaling reacting to surprising demand in addition to scaling up and down on a schedule.

Conclusion
On this publish, we mentioned the potential advantages of making use of SageMaker and AWS Inferentia2 chips inside a production-ready generative AI software. SageMaker absolutely managed asynchronous endpoints present an software time to react to each surprising and predictable demand in a structured method, even for high-demand purposes reminiscent of image-based generative AI. Regardless of the training curve concerned in compiling the Steady Diffusion XL mannequin to run on AWS Inferentia2 chips, utilizing AWS Inferentia2 allowed us to realize our demanding low-latency inference necessities, offering a superb consumer expertise, all whereas remaining cost-efficient.
To be taught extra about SageMaker deployment choices in your generative AI use circumstances, confer with the weblog collection Model hosting patterns in Amazon SageMaker. You may get began with internet hosting a Steady Diffusion mannequin with SageMaker and AWS Inferentia2 through the use of the next example.
Uncover how Monks serves as a complete digital companion by integrating a big selection of options. These embody media, knowledge, social platforms, studio manufacturing, model technique, and cutting-edge know-how. By way of this integration, Monks allows environment friendly content material creation, scalable experiences, and AI-driven knowledge insights, all powered by top-tier trade expertise.
Concerning the Authors
 Benjamin Moody is a Senior Options Architect at Monks. He focuses on designing and managing high-performance, sturdy, and safe architectures, using a broad vary of AWS companies. Ben is especially adept at dealing with tasks with advanced necessities, together with these involving generative AI at scale. Outdoors of labor, he enjoys snowboarding and touring.
Benjamin Moody is a Senior Options Architect at Monks. He focuses on designing and managing high-performance, sturdy, and safe architectures, using a broad vary of AWS companies. Ben is especially adept at dealing with tasks with advanced necessities, together with these involving generative AI at scale. Outdoors of labor, he enjoys snowboarding and touring.
 Karan Jain is a Senior Machine Studying Specialist at AWS, the place he leads the worldwide Go-To-Market technique for Amazon SageMaker Inference. He helps prospects speed up their generative AI and ML journey on AWS by offering steering on deployment, cost-optimization, and GTM technique. He has led product, advertising and marketing, and enterprise growth efforts throughout industries for over 10 years, and is obsessed with mapping advanced service options to buyer options.
Karan Jain is a Senior Machine Studying Specialist at AWS, the place he leads the worldwide Go-To-Market technique for Amazon SageMaker Inference. He helps prospects speed up their generative AI and ML journey on AWS by offering steering on deployment, cost-optimization, and GTM technique. He has led product, advertising and marketing, and enterprise growth efforts throughout industries for over 10 years, and is obsessed with mapping advanced service options to buyer options.
 Raghu Ramesha is a Senior Gen AI/ML Specialist Options Architect with AWS. He focuses on serving to enterprise prospects construct and deploy AI/ ML manufacturing workloads to Amazon SageMaker at scale. He focuses on generative AI, machine studying, and pc imaginative and prescient domains, and holds a grasp’s diploma in Laptop Science from UT Dallas. In his free time, he enjoys touring and pictures.
Raghu Ramesha is a Senior Gen AI/ML Specialist Options Architect with AWS. He focuses on serving to enterprise prospects construct and deploy AI/ ML manufacturing workloads to Amazon SageMaker at scale. He focuses on generative AI, machine studying, and pc imaginative and prescient domains, and holds a grasp’s diploma in Laptop Science from UT Dallas. In his free time, he enjoys touring and pictures.
 Rupinder Grewal is a Senior Gen AI/ML Specialist Options Architect with AWS. He at the moment focuses on mannequin serving and MLOps on SageMaker. Previous to this function, he labored as a Machine Studying Engineer constructing and internet hosting fashions. Outdoors of labor, he enjoys taking part in tennis and biking on mountain trails.
Rupinder Grewal is a Senior Gen AI/ML Specialist Options Architect with AWS. He at the moment focuses on mannequin serving and MLOps on SageMaker. Previous to this function, he labored as a Machine Studying Engineer constructing and internet hosting fashions. Outdoors of labor, he enjoys taking part in tennis and biking on mountain trails.
 Parag Srivastava is a Senior Options Architect at AWS, the place he has been serving to prospects in efficiently making use of generative AI to real-life enterprise situations. Throughout his skilled profession, he has been extensively concerned in advanced digital transformation tasks. He’s additionally obsessed with constructing revolutionary options round geospatial points of addresses.
Parag Srivastava is a Senior Options Architect at AWS, the place he has been serving to prospects in efficiently making use of generative AI to real-life enterprise situations. Throughout his skilled profession, he has been extensively concerned in advanced digital transformation tasks. He’s additionally obsessed with constructing revolutionary options round geospatial points of addresses.