AppWorld: An AI Framework for Constant Execution Setting and Benchmark for Interactive Coding for API-Primarily based Duties
The prospects and scope for automation in digital lives are increasing with the advances in instruction following, coding, and tool-use skills of enormous language fashions (LLMs). Most day-to-day digital duties contain complicated actions throughout varied functions, with reasoning and decision-making primarily based on intermediate outcomes. Nevertheless, the responsive growth of such autonomous brokers wants rigorous, reproducible, and powerful analysis utilizing real looking duties that account for the complexities and dynamics of actual digital environments. The present benchmarks for tool-based options can’t resolve this problem as they use a linear sequence of API calls with out wealthy or interactive coding, and their evaluations by reference options should not appropriate for complicated duties with different options.
The present benchmarks mentioned on this paper are Device-Utilization Benchmarks (TUB) and Interactive Code Era Benchmarks (ICGB). TUB both doesn’t present brokers with executable instruments or makes use of current public APIs, with some providing implementations of straightforward ones. Present analysis strategies rely upon LLMs or human judgment, that are unsuitable for duties with a number of legitimate options. ICGB evaluates the flexibility of brokers to generate executable code, comparable to HumanEval concentrating on brief code snippets and SWEBench specializing in patch file technology. Intercode proposes fixing coding duties interactively by observing code execution outputs, whereas MINT permits brokers to make use of a Python interpreter for reasoning and decision-making.
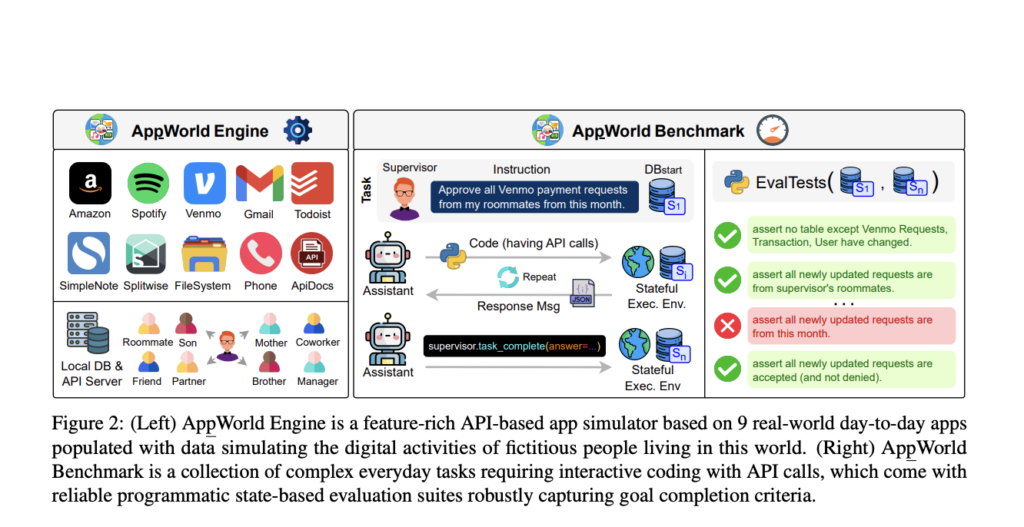
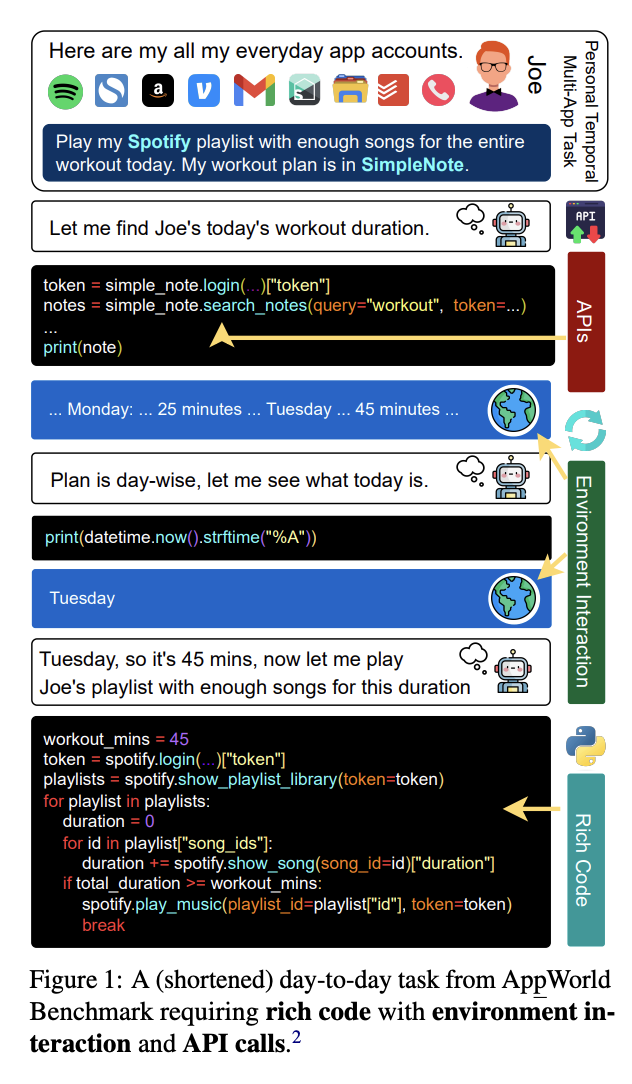
Researchers from Stony Brook College, Allen Institute for AI, and Saarland College have proposed the AppWorld Engine, a high-quality execution atmosphere comprising 60K traces of code. This atmosphere contains 9 day-to-day apps operable by 457 APIs and simulates real looking digital actions for roughly 100 fictitious customers. An AppWorld Benchmark, a group of 750 various and sophisticated duties for autonomous brokers, is developed that requires wealthy and interactive code technology. It permits sturdy programmatic analysis with state-based unit checks, permitting for various process completion strategies and checking for sudden adjustments.
The AppWorld Engine implements 9 functions throughout varied domains, together with emails (Gmail), cash switch (Venmo), purchasing (Amazon), and native file methods. It options 457 APIs that carefully resemble actual app functionalities, averaging 50 APIs per app, and accommodates 1470 arguments. These APIs carry out actions by learn/write operations on a database, e.g. a ship electronic mail API creates new entries within the electronic mail and electronic mail thread tables for each sender and recipient(s). Furthermore, two supporting apps, ApiDocs and Supervisor, are applied. ApiDocs supplies APIs for interactive documentation, whereas Supervisor APIs present details about the duty assigner, comparable to addresses, cost playing cards, and account passwords.
The outcomes present that every one strategies produce low process (TGC) and state of affairs (SGC) completion scores in each Take a look at-N and Take a look at-C. The strongest mannequin, ReAct + GPT4O, achieves a TGC of 48.8 on Take a look at-N, which decreases to 30.2 on Take a look at-C. The 30-50% discount from process to state of affairs scores exhibits that fashions don’t constantly full all process variants inside the identical state of affairs. The second-best mannequin, GPT4Trb, falls considerably behind GPT4O, with open fashions performing even worse. GPT4Trb achieves a TGC of 32.7 and 17.5, whereas one of the best open LLM, FullCodeRefl + LLaMA3, will get a TGC of 24.4 on Take a look at-N and seven.0 on Take a look at-C. CodeAct and ToolLLaMA failed on all duties as a consequence of their specialised narrow-domain coaching.

In abstract, researchers have launched the AppWorld Engine, a sturdy execution atmosphere consisting of 60K traces of code. The AppWorld framework supplies a constant execution atmosphere and a benchmark for interactive API-based duties. Its programmatic analysis suite and real looking challenges guarantee thorough evaluation. Benchmarking state-of-the-art fashions highlights the issue of AppWorld and the challenges that LLMs encounter in automating duties. The system’s modularity and extensibility create alternatives for consumer interface management, coordination amongst a number of brokers, and the examination of privateness and questions of safety in digital assistants.
Try the Paper, GitHub, and Project. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our newsletter..
Don’t Neglect to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars here

Sajjad Ansari is a remaining yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a deal with understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.