CMU-MATH Staff’s Modern Strategy Secures 2nd Place on the AIMO Prize – Machine Studying Weblog | ML@CMU

Just lately, our CMU-MATH crew proudly clinched 2nd place within the Artificial Intelligence Mathematical Olympiad (AIMO) out of 1,161 taking part groups, incomes a prize of $65,536! This prestigious competitors goals to revolutionize AI in mathematical problem-solving, with the final word objective of constructing a publicly-shared AI mannequin able to profitable a gold medal within the International Mathematical Olympiad (IMO). Dive into our weblog to find the profitable components that set us aside on this important contest.
Background: The AIMO competitors
The Synthetic Intelligence Mathematical Olympiad (AIMO) Prize, initiated by XTX Markets, is a pioneering competitors designed to revolutionize AI’s function in mathematical problem-solving. It pushes the boundaries of AI by fixing advanced mathematical issues akin to these within the Worldwide Mathematical Olympiad (IMO). The advisory committee of AIMO contains Timothy Gowers and Terence Tao, each winners of the Fields Medal. Attracting consideration from world-class mathematicians in addition to machine studying researchers, the AIMO units a brand new benchmark for excellence within the subject.
AIMO has launched a collection of progress prizes. The primary of those was a Kaggle competitors, with the 50 take a look at issues hidden from opponents. The issues are comparable in problem to the AMC12 and AIME exams for the USA IMO crew pre-selection. The personal leaderboard decided the ultimate rankings, which then decided the distribution of $253,952 within the one-million greenback prize pool among the many high 5 groups. Every submitted resolution was allotted both a P100 GPU or 2xT4 GPUs, with as much as 9 hours to resolve the 50 issues.
Simply to present an concept about how the issues appear like, AIMO supplied a 10-problem coaching set open to the general public. Listed below are two instance issues within the set:
- Let (ok, l > 0) be parameters. The parabola (y = kx^2 – 2kx + l) intersects the road (y = 4) at two factors (A) and (B). These factors are distance 6 aside. What’s the sum of the squares of the distances from (A) and (B) to the origin?
- Every of the three-digits numbers (111) to (999) is colored blue or yellow in such a approach that the sum of any two (not essentially totally different) yellow numbers is the same as a blue quantity. What’s the most doable variety of yellow numbers there may be?
The primary downside is about analytic geometry. It requires the mannequin to grasp geometric objects based mostly on textual descriptions and carry out symbolic computations utilizing the gap components and Vieta’s formulation. The second downside falls beneath extremal combinatorics, a subject past the scope of highschool math. It’s notoriously difficult as a result of there’s no common components to use; fixing it requires inventive pondering to take advantage of the issue’s construction. It’s non-trivial to grasp all these required capabilities even for people, not to mention language fashions.
Generally, the issues in AIMO had been considerably more difficult than these in GSM8K, a typical mathematical reasoning benchmark for LLMs, and about as tough as the toughest issues within the difficult MATH dataset. The restricted computational assets—P100 and T4 GPUs, each over 5 years previous and far slower than extra superior {hardware}—posed an extra problem. Thus, it was essential to make use of acceptable fashions and inference methods to maximise accuracy throughout the constraints of restricted reminiscence and FLOPs.
Our profitable components
Not like most groups that relied on a single mannequin for the competitors, we utilized a dual-model method. Our remaining options had been derived by way of a weighted majority voting system, which consists of producing a number of options with a coverage mannequin, assigning a weight to every resolution utilizing a reward mannequin, after which selecting the reply with the very best complete weight. Particularly, we paired a coverage mannequin—designed to generate downside options within the type of laptop code—with a reward mannequin—which scored the outputs of the coverage mannequin. Our remaining options had been derived by way of a weighted majority voting system, the place the solutions had been generated by the coverage mannequin and the weights had been decided by the scores from the reward mannequin. This technique stemmed from our examine on compute-optimal inference, demonstrating that weighted majority voting with a reward mannequin constantly outperforms naive majority voting given the identical inference price range.
Each fashions in our submission had been fine-tuned from the DeepSeek-Math-7B-RL checkpoint. Beneath, we element the fine-tuning course of and inference methods for every mannequin.
Coverage mannequin: Program-aided downside solver based mostly on self-refinement
The coverage mannequin served as the first downside solver in our method. We famous that LLMs can carry out mathematical reasoning utilizing each textual content and applications. Pure language excels in summary reasoning however falls brief in exact computation, symbolic manipulation, and algorithmic processing. Applications, then again, are adept at rigorous operations and may leverage specialised instruments like equation solvers for advanced calculations. To harness the advantages of each strategies, we carried out the Program-Aided Language Models (PAL) or extra exactly Tool-Augmented Reasoning (ToRA) method, initially proposed by CMU & Microsoft. This method combines pure language reasoning with program-based problem-solving. The mannequin first generates rationales in textual content kind, adopted by a pc program which executes to derive a numerical reply
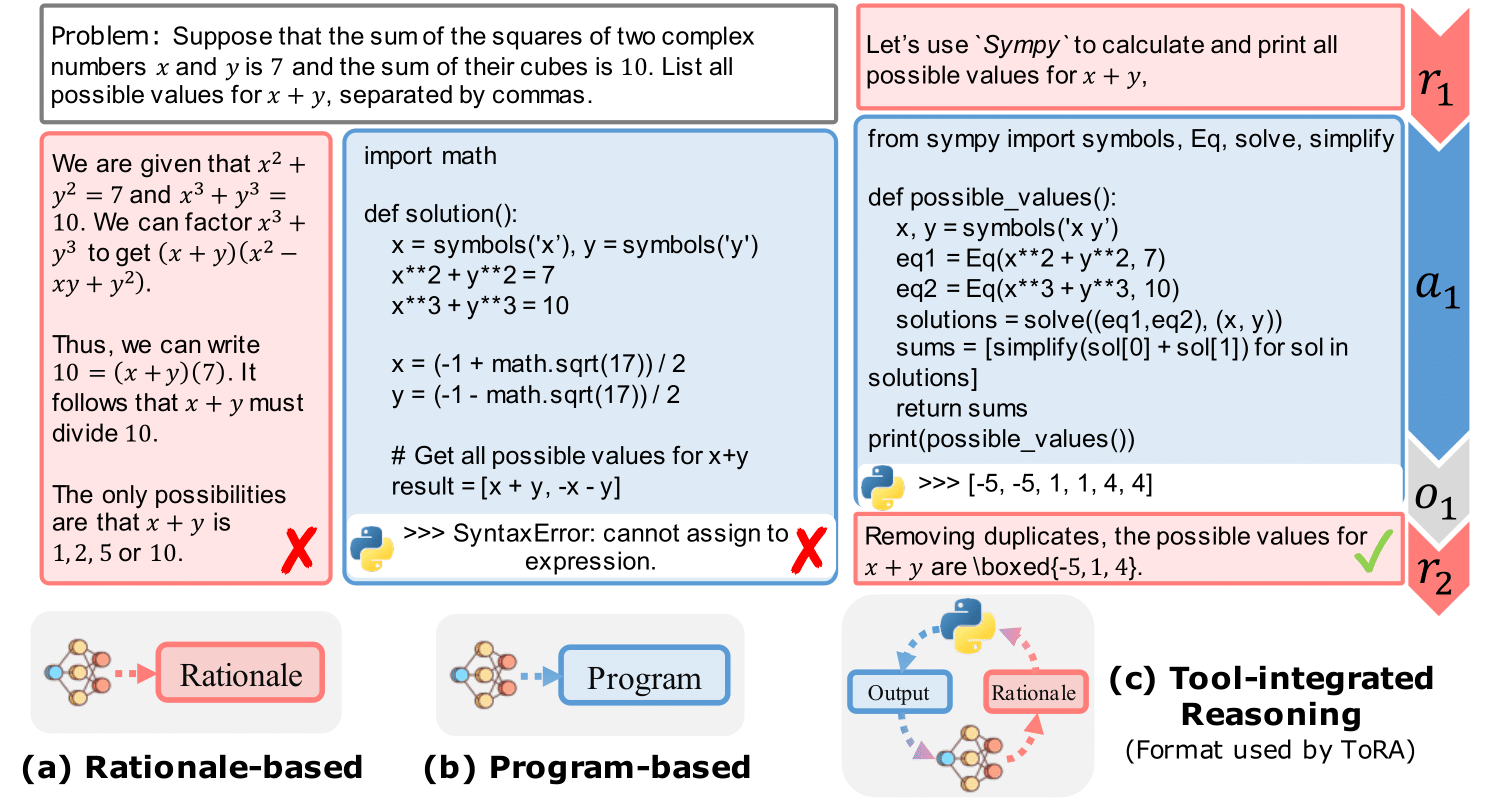
To coach the mannequin, we would have liked an appropriate downside set (the given “coaching set” of this competitors is just too small for fine-tuning) with “floor fact” options in ToRA format for supervised fine-tuning. Given the issue problem (similar to AMC12 and AIME exams) and the particular format (integer solutions solely), we used a mixture of AMC, AIME, and Odyssey-Math as our downside set, eradicating multiple-choice choices and filtering out issues with non-integer solutions. This resulted in a dataset of two,600 issues. We prompted GPT-4o (and DeepSeek-Coder-V2) with few-shot examples to generate 64 options for every downside, retaining those who led to right solutions. Our remaining dataset contained 41,160 problem-solution pairs. We carried out supervised fine-tuning on the open-sourced DeepSeek-Math-7B-RL mannequin for 3 epochs with a studying price of 2e-5.
Throughout inference, we employed the self-refinement method (which is one other extensively adopted method proposed by CMU!), offering suggestions to the coverage mannequin on the execution outcomes of the generated program (e.g., invalid output, execution failure) and permitting the mannequin to refine the answer accordingly.
Beneath we current our ablation examine on the strategies we employed for the coverage mannequin. We used the accuracy on a specific subset of the MATH take a look at set because the analysis metric. It’s straightforward to see the mixture of strategies that result in giant efficiency positive factors in contrast with naive baselines.
| Mannequin | Output format | Inference technique | Accuracy |
|---|---|---|---|
| DeepSeek RL 7b | Textual content-only | Grasping decoding | 54.02% |
| DeepSeek RL 7b | ToRA | Grasping decoding | 58.05% |
| DeepSeek RL 7b | ToRA | Grasping + Self-refine | 60.73% |
| DeepSeek RL 7b | ToRA | Maj@16 + Self-refine | 70.46% |
| DeepSeek RL 7b | ToRA | Maj@64 + Self-refine | 72.48% |
| Our finetuned mannequin | ToRA | Maj@16 + Self-refine | 74.50% |
| Our finetuned mannequin | ToRA | Maj@64 + Self-refine | 76.51% |
Notably, the first-place crew additionally used ToRA with self-refinement. Nonetheless, they curated a a lot bigger downside set of 60,000 issues and used GPT-4 to generate options within the ToRA format. Their dataset was greater than 20x bigger than ours. The fee to generate options was far past our price range as an instructional crew (over $100,000 based mostly on our estimation). Our downside set was based mostly purely on publicly accessible knowledge, and we spent solely ~$1,000 for resolution technology.
Reward mannequin: Answer scorer utilizing label-balance coaching
Whereas the coverage mannequin was a inventive downside solver, it may generally hallucinate and produce incorrect options. On the publicly accessible 10-problem coaching set, our coverage mannequin solely appropriately solved two issues utilizing normal majority voting with 32 sampled options. Curiously, for an additional 2 issues, the mannequin generated right options that did not be chosen resulting from improper solutions dominating in majority voting.
This remark highlighted the potential of the reward mannequin. The reward mannequin was an answer scorer that took the coverage mannequin’s output and generated a rating between 0 and 1. Ideally, it assigned excessive scores to right options and low scores to incorrect ones, aiding within the choice of right solutions throughout weighted majority voting.
The reward mannequin was fine-tuned from a DeepSeek-Math-7B-RL mannequin on a labeled dataset containing each right and incorrect problem-solution pairs. We utilized the identical downside set as for the coverage mannequin coaching and expanded it by incorporating issues from the MATH dataset with integer solutions. Easy as it might sound, producing high-quality knowledge and coaching a powerful reward mannequin was non-trivial. We thought of the next two important elements for the reward mannequin coaching set:
- Label stability: The dataset ought to include each right (constructive examples) and incorrect options (unfavourable examples) for every downside, with a balanced variety of right and incorrect options.
- Range: The dataset ought to embody numerous options for every downside, encompassing totally different right approaches and varied failure modes.
Sampling options from a single mannequin can not meet these elements. For instance, whereas our fine-tuned coverage mannequin achieved very excessive accuracy on the issue set, it was unable to generate any incorrect options and lacked variety amongst right options. Conversely, sampling from a weaker mannequin, similar to DeepSeek-Math-7B-Base, not often yielded right options. To create a various set of fashions with various capabilities, we employed two novel methods:
- Interpolate between robust and weak fashions. For MATH issues, we interpolated the mannequin parameters of a powerful mannequin (DeepSeek-Math-7B-RL) and a weak mannequin (DeepSeek-Math-7B-Base) to get fashions with totally different stage of capabilities. Denote by (mathbf{theta}_{mathrm{robust}}) and (mathbf{theta}_{mathrm{weak}}) the mannequin parameters of the robust and weak mannequin. We thought of interpolated fashions with parameters (mathbf{theta}_{alpha}=alphamathbf{theta}_{mathrm{robust}}+(1-alpha)mathbf{theta}_{mathrm{weak}}) and set (alphain{0.3, 0.4, cdots, 1.0}), acquiring 8 fashions. These fashions exhibited totally different downside fixing accuracies on MATH. We sampled two options from every mannequin for every downside, yielding numerous outputs with balanced right and incorrect options. This method was motivated by the analysis on mannequin parameter merging (e.g., model soups) and represented an fascinating utility of this concept, i.e., producing fashions with totally different ranges of capabilities.
- Leverage intermediate checkpoints. For the AMC, AIME, and Odyssey, recall that our coverage mannequin had been fine-tuned on these issues for 3 epochs. The ultimate mannequin and its intermediate checkpoints naturally supplied us with a number of fashions exhibiting totally different ranges of accuracy on these issues. We leveraged these intermediate checkpoints, sampling 12 options from every mannequin skilled for 0, 1, 2, and three epochs.
These methods allowed us to acquire a various set of fashions virtually at no cost, sampling various right and incorrect options. We additional filtered the generated knowledge by eradicating improper options with non-integer solutions because it was trivial to find out that these solutions are incorrect throughout inference. As well as, for every downside, we maintained equal numbers of right and incorrect options to make sure label stability and keep away from a biased reward mannequin. The ultimate dataset comprises 7000 distinctive issues and 37880 labeled problem-solution pairs. We finetuned DeepSeek-Math-7B-RL mannequin for two epochs with studying price 2e-5 on the curated dataset.

We validated the effectiveness of our reward mannequin on the general public coaching set. Notably, by pairing the coverage mannequin with the reward mannequin and making use of weighted majority voting, our methodology appropriately solved 4 out of the ten issues – whereas a single coverage mannequin may solely resolve 2 utilizing normal majority voting.
Concluding remarks: In the direction of machine-based mathematical reasoning
With the fashions and strategies described above, our CMU-MATH crew solved 22 out of fifty issues within the personal take a look at set, snagging the second place and establishing one of the best efficiency of an instructional crew. This final result marks a major step in direction of the objective of machine-based mathematical reasoning.
Nonetheless, we additionally observe that the accuracy achieved by our fashions nonetheless trails behind that of proficient human opponents who can simply resolve over 95% of AIMO issues, indicating substantial room for enchancment. There are a variety of instructions to be explored:
- Superior inference-time algorithms for mathematical reasoning. Our dual-model method is a strong method to boost mannequin reasoning at inference time. Latest analysis from our crew means that extra superior inference-time algorithms, e.g., tree search strategies, may even surpass weighted majority voting. Though computational constraints restricted our means to deploy this method within the AIMO competitors, future explorations on optimizing these inference-time algorithms can probably result in higher mathematical reasoning approaches.
- Integration of Automated Theorem Proving. Integrating automated theorem proving (ATP) instruments, similar to Lean, represents one other promising frontier. ATP instruments can present rigorous logical frameworks and help for deeper mathematical analyses, probably elevating the precision and reliability of problem-solving methods employed by LLMs. The synergy between LLMs and ATP may result in breakthroughs in advanced problem-solving situations, the place deep logical reasoning is important.
- Leveraging Bigger, Extra Various Datasets. The competitors strengthened an important lesson in regards to the pivotal function of knowledge in machine studying. Wealthy, numerous datasets, particularly these comprising difficult mathematical issues, are important for coaching extra succesful fashions. We advocate for the creation and launch of bigger datasets targeted on mathematical reasoning, which might not solely profit our analysis but additionally the broader AI and arithmetic communities.
Lastly, we wish to thank Kaggle and XTX Markets for organizing this excellent competitors. We have now open-sourced our code and datasets utilized in our resolution to make sure reproducibility and facilitate future analysis. We invite the group to discover, make the most of, and construct upon our work, which is obtainable in our GitHub repository. For additional particulars about our outcomes, please be happy to succeed in out to us!





