Why the Latest LLMs use a MoE (Combination of Consultants) Structure


Specialization Made Obligatory
A hospital is overcrowded with specialists and docs every with their very own specializations, fixing distinctive issues. Surgeons, cardiologists, pediatricians—specialists of every kind be part of palms to supply care, typically collaborating to get the sufferers the care they want. We are able to do the identical with AI.
Combination of Consultants (MoE) structure in synthetic intelligence is outlined as a mixture or mix of various “knowledgeable” fashions working collectively to cope with or reply to complicated knowledge inputs. On the subject of AI, each knowledgeable in an MoE mannequin focuses on a a lot bigger drawback—similar to each physician specializes of their medical subject. This improves effectivity and will increase system efficacy and accuracy.
Mistral AI delivers open-source foundational LLMs that rival that of OpenAI. They’ve formally mentioned using an MoE structure of their Mixtral 8x7B mannequin, a revolutionary breakthrough within the type of a cutting-edge Massive Language Mannequin (LLM). We’ll deep dive into why Mixtral by Mistral AI stands out amongst different foundational LLMs and why present LLMs now make use of the MoE structure highlighting its pace, measurement, and accuracy.
Frequent Methods to Improve Massive Language Fashions (LLMs)
To raised perceive how the MoE structure enhances our LLMs, let’s talk about widespread strategies for bettering LLM effectivity. AI practitioners and builders improve fashions by rising parameters, adjusting the structure, or fine-tuning.
- Rising Parameters: By feeding extra data and decoding it, the mannequin’s capability to be taught and signify complicated patterns will increase. Nevertheless, this may result in overfitting and hallucinations, necessitating in depth Reinforcement Studying from Human Suggestions (RLHF).
- Tweaking Structure: Introducing new layers or modules accommodates the rising parameter counts and improves efficiency on particular duties. Nevertheless, modifications to the underlying structure are difficult to implement.
- Effective-tuning: Pre-trained fashions might be fine-tuned on particular knowledge or by switch studying, permitting current LLMs to deal with new duties or domains with out ranging from scratch. That is the best technique and doesn’t require vital modifications to the mannequin.
What’s the MoE Structure?
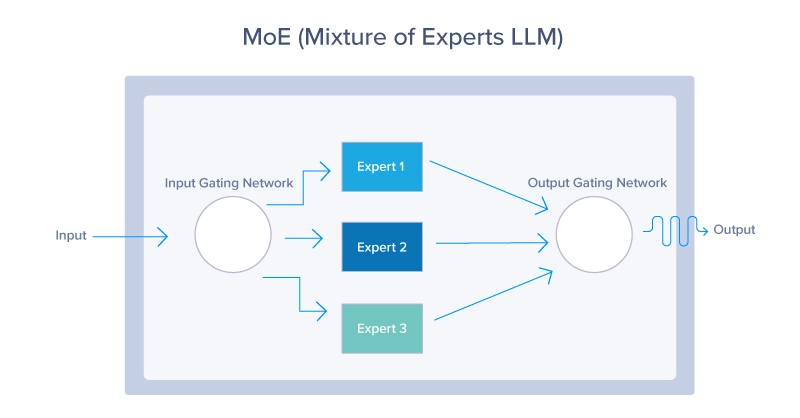
The Combination of Consultants (MoE) structure is a neural community design that improves effectivity and efficiency by dynamically activating a subset of specialised networks, referred to as specialists, for every enter. A gating community determines which specialists to activate, resulting in sparse activation and lowered computational price. MoE structure consists of two essential elements: the gating community and the specialists. Let’s break that down:
At its coronary heart, the MoE structure capabilities like an environment friendly site visitors system, directing every automobile – or on this case, knowledge – to the perfect route based mostly on real-time circumstances and the specified vacation spot. Every process is routed to probably the most appropriate knowledgeable, or sub-model, specialised in dealing with that exact process. This dynamic routing ensures that probably the most succesful sources are employed for every process, enhancing the general effectivity and effectiveness of the mannequin. The MoE structure takes benefit of all 3 methods easy methods to enhance a mannequin’s constancy.
- By implementing a number of specialists, MoE inherently will increase the mannequin’s
- parameter measurement by including extra parameters per knowledgeable.
- MoE modifications the traditional neural community structure which includes a gated community to find out which specialists to make use of for a chosen process.
- Each AI mannequin has a point of fine-tuning, thus each knowledgeable in an MoE is fine-tuned to carry out as supposed for an added layer of tuning conventional fashions couldn’t make the most of.
MoE Gating Community
The gating community acts because the decision-maker or controller throughout the MoE mannequin. It evaluates incoming duties and determines which knowledgeable is suited to deal with them. This resolution is often based mostly on discovered weights, that are adjusted over time by coaching, additional bettering its capacity to match duties with specialists. The gating community can make use of varied methods, from probabilistic strategies the place tender assignments are tasked to a number of specialists, to deterministic strategies that route every process to a single knowledgeable.
MoE Consultants
Every knowledgeable within the MoE mannequin represents a smaller neural community, machine studying mannequin, or LLM optimized for a selected subset of the issue area. For instance, in Mistral, completely different specialists may concentrate on understanding sure languages, dialects, and even kinds of queries. The specialization ensures every knowledgeable is proficient in its area of interest, which, when mixed with the contributions of different specialists, will result in superior efficiency throughout a wide selection of duties.
MoE Loss Operate
Though not thought of a primary part of the MoE structure, the loss operate performs a pivotal position sooner or later efficiency of the mannequin, because it’s designed to optimize each the person specialists and the gating community.
It usually combines the losses computed for every knowledgeable that are weighted by the likelihood or significance assigned to them by the gating community. This helps to fine-tune the specialists for his or her particular duties whereas adjusting the gating community to enhance routing accuracy.
The MoE Course of Begin to End
Now let’s sum up the whole course of, including extra particulars.
Here is a summarized clarification of how the routing course of works from begin to end:
- Enter Processing: Preliminary dealing with of incoming knowledge. Primarily our Immediate within the case of LLMs.
- Function Extraction: Remodeling uncooked enter for evaluation.
- Gating Community Analysis: Assessing knowledgeable suitability by way of chances or weights.
- Weighted Routing: Allocating enter based mostly on computed weights. Right here, the method of selecting probably the most appropriate LLM is accomplished. In some circumstances, a number of LLMs are chosen to reply a single enter.
- Process Execution: Processing allotted enter by every knowledgeable.
- Integration of Skilled Outputs: Combining particular person knowledgeable outcomes for ultimate output.
- Suggestions and Adaptation: Utilizing efficiency suggestions to enhance fashions.
- Iterative Optimization: Steady refinement of routing and mannequin parameters.
Fashionable Fashions that Make the most of an MoE Structure
- OpenAI’s GPT-4 and GPT-4o: GPT-4 and GPT4o energy the premium model of ChatGPT. These multi-modal fashions make the most of MoE to have the ability to ingest completely different supply mediums like photographs, textual content, and voice. It’s rumored and barely confirmed that GPT-4 has 8 specialists every with 220 billion paramters totalling the whole mannequin to over 1.7 trillion parameters.
- Mistral AI’s Mixtral 8x7b: Mistral AI delivers very robust AI fashions open supply and have stated their Mixtral mannequin is a sMoE mannequin or sparse Combination of Consultants mannequin delivered in a small bundle. Mixtral 8x7b has a complete of 46.7 billion parameters however solely makes use of 12.9B parameters per token, thus processing inputs and outputs at that price. Their MoE mannequin persistently outperforms Llama2 (70B) and GPT-3.5 (175B) whereas costing much less to run.
The Advantages of MoE and Why It is the Most well-liked Structure
Finally, the primary aim of MoE structure is to current a paradigm shift in how complicated machine studying duties are approached. It affords distinctive advantages and demonstrates its superiority over conventional fashions in a number of methods.
- Enhanced Mannequin Scalability
- Every knowledgeable is chargeable for part of a process, due to this fact scaling by including specialists will not incur a proportional enhance in computational calls for.
- This modular strategy can deal with bigger and extra numerous datasets and facilitates parallel processing, rushing up operations. For example, including a picture recognition mannequin to a text-based mannequin can combine an extra LLM knowledgeable for decoding footage whereas nonetheless with the ability to output textual content. Or
- Versatility permits the mannequin to increase its capabilities throughout several types of knowledge inputs.
- Improved Effectivity and Flexibility
- MoE fashions are extraordinarily environment friendly, selectively participating solely mandatory specialists for particular inputs, in contrast to standard architectures that use all their parameters regardless.
- The structure reduces the computational load per inference, permitting the mannequin to adapt to various knowledge varieties and specialised duties.
- Specialization and Accuracy:
- Every knowledgeable in an MoE system might be finely tuned to particular features of the general drawback, resulting in higher experience and accuracy in these areas
- Specialization like that is useful in fields like medical imaging or monetary forecasting, the place precision is vital
- MoE can generate higher outcomes from slim domains as a result of its nuanced understanding, detailed information, and the power to outperform generalist fashions on specialised duties.
The Downsides of The MoE Structure
Whereas MoE structure affords vital benefits, it additionally comes with challenges that may affect its adoption and effectiveness.
- Mannequin Complexity: Managing a number of neural community specialists and a gating community for guiding site visitors makes MoE growth and operational prices difficult
- Coaching Stability: Interplay between the gating community and the specialists introduces unpredictable dynamics that hinder attaining uniform studying charges and require in depth hyperparameter tuning.
- Imbalance: Leaving specialists idle is poor optimization for the MoE mannequin, spending sources on specialists that aren’t in use or counting on sure specialists an excessive amount of. Balancing the workload distribution and tuning an efficient gate is essential for a high-performing MoE AI.
It must be famous that the above drawbacks often diminish over time as MoE structure is improved.
The Future Formed by Specialization
Reflecting on the MoE strategy and its human parallel, we see that simply as specialised groups obtain greater than a generalized workforce, specialised fashions outperform their monolithic counterparts in AI fashions. Prioritizing range and experience turns the complexity of large-scale issues into manageable segments that specialists can sort out successfully.
As we glance to the long run, think about the broader implications of specialised methods in advancing different applied sciences. The rules of MoE might affect developments in sectors like healthcare, finance, and autonomous methods, selling extra environment friendly and correct options.
The journey of MoE is simply starting, and its continued evolution guarantees to drive additional innovation in AI and past. As high-performance {hardware} continues to advance, this combination of knowledgeable AIs can reside in our smartphones, able to delivering even smarter experiences. However first, somebody’s going to want to coach one.
Kevin Vu manages Exxact Corp blog and works with a lot of its gifted authors who write about completely different features of Deep Studying.





