Consider conversational AI brokers with Amazon Bedrock
As conversational synthetic intelligence (AI) brokers acquire traction throughout industries, offering reliability and consistency is essential for delivering seamless and reliable consumer experiences. Nevertheless, the dynamic and conversational nature of those interactions makes conventional testing and analysis strategies difficult. Conversational AI brokers additionally embody a number of layers, from Retrieval Augmented Technology (RAG) to function-calling mechanisms that work together with exterior data sources and instruments. Though present massive language mannequin (LLM) benchmarks like MT-bench consider mannequin capabilities, they lack the power to validate the appliance layers. The next are some frequent ache factors in growing conversational AI brokers:
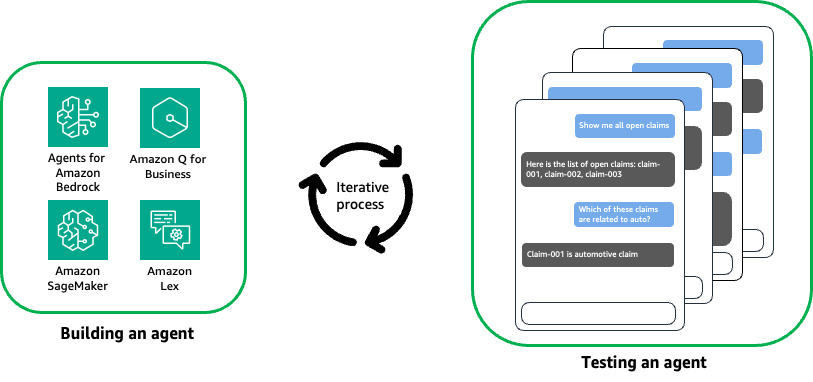
- Testing an agent is commonly tedious and repetitive, requiring a human within the loop to validate the semantics which means of the responses from the agent, as proven within the following determine.
- Organising correct take a look at circumstances and automating the analysis course of will be tough as a result of conversational and dynamic nature of agent interactions.
- Debugging and tracing how conversational AI brokers path to the suitable motion or retrieve the specified outcomes will be complicated, particularly when integrating with exterior data sources and instruments.

Agent Evaluation, an open supply resolution utilizing LLMs on Amazon Bedrock, addresses this hole by enabling complete analysis and validation of conversational AI brokers at scale.
Amazon Bedrock is a completely managed service that provides a alternative of high-performing basis fashions (FMs) from main AI corporations like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon by way of a single API, together with a broad set of capabilities to construct generative AI purposes with safety, privateness, and accountable AI.
Agent Analysis gives the next:
- Constructed-in help for fashionable providers, together with Agents for Amazon Bedrock, Knowledge Bases for Amazon Bedrock, Amazon Q Business, and Amazon SageMaker endpoints
- Orchestration of concurrent, multi-turn conversations together with your agent whereas evaluating its responses
- Configurable hooks to validate actions triggered by your agent
- Integration into steady integration and supply (CI/CD) pipelines to automate agent testing
- A generated take a look at abstract for efficiency insights together with dialog historical past, take a look at cross price, and reasoning for cross/fail outcomes
- Detailed traces to allow step-by-step debugging of the agent interactions
On this submit, we show tips on how to streamline digital agent testing at scale utilizing Amazon Bedrock and Agent Analysis.
Answer overview
To make use of Agent Analysis, you have to create a take a look at plan, which consists of three configurable parts:
- Goal – A goal represents the agent you wish to take a look at
- Evaluator – An evaluator represents the workflow and logic to judge the goal on a take a look at
- Take a look at – A take a look at defines the goal’s performance and the way you need your end-user to work together with the goal, which incorporates:
- A sequence of steps representing the interactions between the agent and the end-user
- Your anticipated outcomes of the dialog
The next determine illustrates how Agent Analysis works on a excessive degree. The framework implements an LLM agent (evaluator) that may orchestrate conversations with your personal agent (goal) and consider the responses through the dialog.

The next determine illustrates the analysis workflow. It exhibits how the evaluator causes and assesses responses based mostly on the take a look at plan. You’ll be able to both present an preliminary immediate or instruct the evaluator to generate one to provoke the dialog. At every flip, the evaluator engages the goal agent and evaluates its response. This course of continues till the anticipated outcomes are noticed or the utmost variety of dialog turns is reached.

By understanding this workflow logic, you may create a take a look at plan to completely assess your agent’s capabilities.
Use case overview
For instance how Agent Analysis can speed up the event and deployment of conversational AI brokers at scale, let’s discover an instance situation: growing an insurance claim processing agent using Agents for Amazon Bedrock. This insurance coverage declare processing agent is anticipated to deal with varied duties, similar to creating new claims, sending reminders for pending paperwork associated to open claims, gathering proof for claims, and looking for related data throughout present claims and buyer data repositories.
For this use case, the aim is to check the agent’s functionality to precisely search and retrieve related data from present claims. You wish to be sure the agent gives right and dependable details about present claims to end-users. Totally evaluating this performance is essential earlier than deployment.
Start by creating and testing the agent in your growth account. Throughout this part, you work together manually with the conversational AI agent utilizing pattern prompts to do the next:
- Interact the agent in multi-turn conversations on the Amazon Bedrock console
- Validate the responses from the agent
- Validate all of the actions invoked by the agent
- Debug and verify traces for any routing failures
With Agent Analysis, the developer can streamline this course of by way of the next steps:
- Configure a take a look at plan:
- Select an evaluator from the fashions offered by Amazon Bedrock.
- Configure the goal, which must be a kind that Agent Evaluation supports. For this submit, we use an Amazon Bedrock agent.
- Outline the take a look at steps and anticipated outcomes. Within the following instance take a look at plan, you may have a declare with the ID
claim-006in your take a look at system. You wish to affirm that your agent can precisely reply questions on this particular declare.
- Run the take a look at plan from the command line:
The Agent Analysis take a look at runner will robotically orchestrate the take a look at based mostly on the take a look at plan, and use the evaluator to find out if the responses from the goal match the anticipated outcomes.
- View the outcome abstract.
A outcome abstract shall be offered in markdown format. Within the following instance, the abstract signifies that the take a look at failed as a result of the agent was unable to offer correct details about the present declareclaim-006.
- Debug with the hint information of the failed assessments.
Agent Analysis gives detailed hint information for the assessments. Every hint file meticulously information each immediate and interplay between the goal and the evaluator.For example, within the_invoke_targetstep, you may acquire worthwhile insights into the rationale behind the Amazon Bedrock agent’s responses, permitting you to delve deeper into the decision-making course of:The hint exhibits that after reviewing the dialog historical past, the evaluator concludes, “the agent shall be unable to reply or help with this query utilizing solely the capabilities it has entry to.” Consequently, it ends the dialog with the goal agent and proceeds to generate the take a look at standing.
Within the
_generate_test_statusstep, the evaluator generates the take a look at standing with reasoning based mostly on the responses from the goal.The take a look at plan defines the anticipated outcome because the goal agent precisely offering particulars in regards to the present declare
claim-006. Nevertheless, after testing, the goal agent’s response doesn’t meet the anticipated outcome, and the take a look at fails. - After figuring out and addressing the problem, you may rerun the take a look at to validate the repair. On this instance, it’s evident that the goal agent lacks entry to the declare
claim-006. From there, you may proceed investigating and confirm ifclaim-006exists in your take a look at system.
Combine Agent Analysis with CI/CD pipelines
After validating the performance within the growth account, you may commit the code to the repository and provoke the deployment course of for the conversational AI agent to the subsequent stage. Seamless integration with CI/CD pipelines is a vital side of Agent Analysis, enabling complete integration testing to ensure no regressions are launched throughout new function growth or updates. This rigorous testing method is important for sustaining the reliability and consistency of conversational AI brokers as they progress by way of the software program supply lifecycle.
By incorporating Agent Analysis into CI/CD workflows, organizations can automate the testing course of, ensuring each code change or replace undergoes thorough analysis earlier than deployment. This proactive measure minimizes the danger of introducing bugs or inconsistencies that would compromise the conversational AI agent’s efficiency and the general consumer expertise.
A normal agent CI/CD pipeline consists of the next steps:
- The supply repository shops the agent configuration, together with agent directions, system prompts, mannequin configuration, and so forth. You need to at all times commit your adjustments to offer high quality and reproducibility.
- Once you commit your adjustments, a construct step is invoked. That is the place unit assessments ought to run and validate the adjustments, together with typo and syntax checks.
- When the adjustments are deployed to the staging atmosphere, Agent Analysis runs with a sequence of take a look at circumstances for runtime validation.
- The runtime validation on the staging atmosphere may also help construct confidence to deploy the totally examined agent to manufacturing.
The next determine illustrates this pipeline.

Within the following sections, we offer step-by-step directions to arrange Agent Analysis with GitHub Actions.
Conditions
Full the next prerequisite steps:
- Comply with the GitHub user guide to get began with GitHub.
- Comply with the GitHub Actions user guide to know GitHub workflows and Actions.
- Comply with the insurance claim processing agent using Agents for Amazon Bedrock instance to arrange an agent.
Arrange GitHub Actions
Full the next steps to deploy the answer:
- Write a sequence of take a look at circumstances following the agent-evaluation test plan syntax and retailer take a look at plans within the GitHub repository. For instance, a take a look at plan to check an Amazon Bedrock agent goal is written as follows, with
BEDROCK_AGENT_ALIAS_IDandBEDROCK_AGENT_IDas placeholders: - Create an AWS Identity and Access Management (IAM) user with the right permissions:
- The principal will need to have InvokeModel permission to the mannequin specified within the configuration.
- The principal will need to have the permissions to name the goal agent. Relying on the goal kind, completely different permissions are required. Seek advice from the agent-evaluation target documentation for particulars.
- Retailer the IAM credentials (
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEY) in GitHub Actions secrets. - Configure a GitHub workflow as follows:
Once you push new adjustments to the repository, it can invoke the GitHub Motion, and an instance workflow output is displayed, as proven within the following screenshot.

A take a look at abstract like the next screenshot shall be posted to the GitHub workflow web page with particulars on which assessments have failed.

The abstract additionally gives the explanations for the take a look at failures.

Clear up
Full the next steps to wash up your sources:
- Delete the IAM user you created for the GitHub Motion.
- Comply with the insurance claim processing agent using Agents for Amazon Bedrock instance to delete the agent.
Evaluator issues
By default, evaluators use the InvokeModel API with On-Demand mode, which can incur AWS expenses based mostly on enter tokens processed and output tokens generated. For the most recent pricing particulars for Amazon Bedrock, confer with Amazon Bedrock pricing.
The price of operating an evaluator for a single take a look at is influenced by the next:
- The quantity and size of the steps
- The quantity and size of anticipated outcomes
- The size of the goal agent’s responses
You’ll be able to view the overall variety of enter tokens processed and output tokens generated by the evaluator utilizing the --verbose flag once you carry out a run (agenteval run --verbose).
Conclusion
This submit launched Agent Analysis, an open supply resolution that permits builders to seamlessly combine agent analysis into their present CI/CD workflows. By profiting from the capabilities of LLMs on Amazon Bedrock, Agent Analysis allows you to comprehensively consider and debug your brokers, attaining dependable and constant efficiency. With its user-friendly take a look at plan configuration, Agent Analysis simplifies the method of defining and orchestrating assessments, permitting you to deal with refining your brokers’ capabilities. The answer’s built-in help for fashionable providers makes it a flexible instrument for testing a variety of conversational AI brokers. Furthermore, Agent Analysis’s seamless integration with CI/CD pipelines empowers groups to automate the testing course of, ensuring each code change or replace undergoes rigorous analysis earlier than deployment. This proactive method minimizes the danger of introducing bugs or inconsistencies, in the end enhancing the general consumer expertise.
The next are some suggestions to contemplate:
- Don’t use the identical mannequin to judge the outcomes that you just use to energy the agent. Doing so might introduce biases and result in inaccurate evaluations.
- Block your pipelines on accuracy failures. Implement strict high quality gates to assist forestall deploying brokers that fail to satisfy the anticipated accuracy or efficiency thresholds.
- Repeatedly increase and refine your take a look at plans. As your brokers evolve, commonly replace your take a look at plans to cowl new eventualities and edge circumstances, and supply complete protection.
- Use Agent Analysis’s logging and tracing capabilities to realize insights into your brokers’ decision-making processes, facilitating debugging and efficiency optimization.
Agent Analysis unlocks a brand new degree of confidence in your conversational AI brokers’ efficiency by streamlining your growth workflows, accelerating time-to-market, and delivering distinctive consumer experiences. To additional discover the most effective practices of constructing and testing conversational AI agent analysis at scale, get began by attempting Agent Evaluation and supply your suggestions.
Concerning the Authors
 Sharon Li is an AI/ML Specialist Options Architect at Amazon Internet Companies (AWS) based mostly in Boston, Massachusetts. With a ardour for leveraging cutting-edge expertise, Sharon is on the forefront of growing and deploying progressive generative AI options on the AWS cloud platform.
Sharon Li is an AI/ML Specialist Options Architect at Amazon Internet Companies (AWS) based mostly in Boston, Massachusetts. With a ardour for leveraging cutting-edge expertise, Sharon is on the forefront of growing and deploying progressive generative AI options on the AWS cloud platform.
 Bobby Lindsey is a Machine Studying Specialist at Amazon Internet Companies. He’s been in expertise for over a decade, spanning varied applied sciences and a number of roles. He’s presently targeted on combining his background in software program engineering, DevOps, and machine studying to assist prospects ship machine studying workflows at scale. In his spare time, he enjoys studying, analysis, mountaineering, biking, and path operating.
Bobby Lindsey is a Machine Studying Specialist at Amazon Internet Companies. He’s been in expertise for over a decade, spanning varied applied sciences and a number of roles. He’s presently targeted on combining his background in software program engineering, DevOps, and machine studying to assist prospects ship machine studying workflows at scale. In his spare time, he enjoys studying, analysis, mountaineering, biking, and path operating.
 Tony Chen is a Machine Studying Options Architect at Amazon Internet Companies, serving to prospects design scalable and sturdy machine studying capabilities within the cloud. As a former knowledge scientist and knowledge engineer, he leverages his expertise to assist sort out a few of the most difficult issues organizations face with operationalizing machine studying.
Tony Chen is a Machine Studying Options Architect at Amazon Internet Companies, serving to prospects design scalable and sturdy machine studying capabilities within the cloud. As a former knowledge scientist and knowledge engineer, he leverages his expertise to assist sort out a few of the most difficult issues organizations face with operationalizing machine studying.
 Suyin Wang is an AI/ML Specialist Options Architect at AWS. She has an interdisciplinary schooling background in Machine Studying, Monetary Data Service and Economics, together with years of expertise in constructing Knowledge Science and Machine Studying purposes that solved real-world enterprise issues. She enjoys serving to prospects establish the appropriate enterprise questions and constructing the appropriate AI/ML options. In her spare time, she loves singing and cooking.
Suyin Wang is an AI/ML Specialist Options Architect at AWS. She has an interdisciplinary schooling background in Machine Studying, Monetary Data Service and Economics, together with years of expertise in constructing Knowledge Science and Machine Studying purposes that solved real-world enterprise issues. She enjoys serving to prospects establish the appropriate enterprise questions and constructing the appropriate AI/ML options. In her spare time, she loves singing and cooking.
 Curt Lockhart is an AI/ML Specialist Options Architect at AWS. He comes from a non-traditional background of working within the arts earlier than his transfer to tech, and enjoys making machine studying approachable for every buyer. Primarily based in Seattle, yow will discover him venturing to native artwork museums, catching a live performance, and wandering all through the cities and open air of the Pacific Northwest.
Curt Lockhart is an AI/ML Specialist Options Architect at AWS. He comes from a non-traditional background of working within the arts earlier than his transfer to tech, and enjoys making machine studying approachable for every buyer. Primarily based in Seattle, yow will discover him venturing to native artwork museums, catching a live performance, and wandering all through the cities and open air of the Pacific Northwest.





