LLM Alignment: Reward-Primarily based vs Reward-Free Strategies | by Anish Dubey | Jul, 2024
Optimization strategies for LLM alignment
Language fashions have demonstrated outstanding talents in producing a variety of compelling textual content based mostly on prompts supplied by customers. Nonetheless, defining what constitutes “good” textual content is difficult, because it typically relies on private preferences and the precise context. For example, in storytelling, creativity is vital; in crafting informative content material, accuracy and reliability are essential; and when producing code, making certain it runs appropriately is crucial. Therefore the “LLM alignment downside,” which refers back to the problem of making certain that giant language fashions (LLMs) act in methods which can be in step with human values, intentions, and preferences.
Designing a loss perform that captures the varied qualities we worth in textual content — like creativity, accuracy, or executability — is very advanced and infrequently impractical. Ideas like these will not be differentiable and therefore not back-propagated and can’t be skilled upon with easy subsequent token era.
Think about if we might harness human suggestions to judge the standard of generated textual content or, even higher, use that suggestions as a guiding loss perform to enhance the mannequin’s efficiency. This idea is on the coronary heart of Reinforcement Studying from Human Suggestions (RLHF). By making use of reinforcement studying methods, RLHF permits us to fine-tune language fashions based mostly on direct human suggestions, aligning the fashions extra intently with nuanced human values and expectations. This strategy has opened up new potentialities for coaching language fashions that aren’t solely extra responsive but in addition extra aligned with the complexity of human preferences.
Beneath, we are going to intention to be taught extra about RLHF by way of reward-based after which about RLHF by way of reward-free strategies.
Let’s undergo Reinforcement studying by means of human suggestions (RLHF). It consist of three foremost phases:
- Supervised positive tuning
- Reward modeling section
- RL fine-tuning section
Supervised positive tuning
RLHF is a pre-trained mannequin which is ok tuned already on a top quality information set. Its goal is straightforward i.e. when given an enter (immediate), it produces an output. The last word goal right here is to additional positive tune this mannequin to supply output in response to human desire. Therefore, let’s name this a base mannequin for reference. At the moment, this mannequin is a vanilla base mannequin which isn’t conscious of any human desire.
Reward Modelling Part
Reward mannequin innovation: That is the place the brand new innovation begins on how reward fashions are integrated into RLHF. The thought behind the reward mannequin is {that a} new LLM mannequin, which might be identical because the above talked about base mannequin, may have the flexibility to generate human desire rating. The rationale it’s much like a big language mannequin is as a result of this mannequin additionally wants to grasp the language semantics earlier than it could possibly fee if an output is human most well-liked or not. Because the reward is scalar, we add a linear layer on prime of LLM to generate a scalar rating by way of human desire.
Knowledge assortment section: That is completed from the supervised positive tuning stage the place the bottom mannequin is requested to generate 2 outputs for a given textual content. Instance: For an enter token x, two output tokens are generated, y1 and y2 by the bottom mannequin. These outputs are proven to human raters to fee and human desire is recorded for every particular person output.
Coaching section: As soon as the information pattern is collected from the information assortment section, the reward mannequin is skilled with the next immediate. “Given the next enter: <x>, LLM generated <y> output. Are you able to fee the efficiency of the output?”. The mannequin will output r(reward) and we already know the precise worth of reward r1 from the information assortment section. Now, this may be back-propagated with the loss perform and the mannequin might be skilled. Beneath is the target loss perform which the mannequin optimises for by means of back-propagation:
Notation:
- rΦ(x, y): a reward mannequin parameterized by Φ which estimates the reward. Parameterized means we don’t know the precise worth and this must be optimized from the above equation. That is the reward LLM mannequin itself. Largely, the LLM parameters are frozen right here and solely few parameters are left to vary. Most essential layer is the linear layer added on the prime. This does a lot of the studying to fee the rating of output.
- Ɗ: A dataset of triplets (x, yw, yl) the place x: enter, yw: the winner output and yl: the loser output
- σ: the sigmoid perform which maps the distinction in reward to a likelihood (0–1)
- ∑(x, y,w yl) ~Ɗ means x, yw, yl are all sampled from Ɗ
Instance situation: Think about you’re coaching a reward mannequin to judge responses. You’ve pairs of responses to a given immediate, and human suggestions tells you which ones response is best. For context, x(“What’s the capital of France?”), you’ve yw(“The capital of France is Paris.”) as winner and yl(“The capital of France is Berlin.” ) as loser. The reward mannequin ought to finally be taught to provide greater reward for “The capital of France is Paris.” output when in comparison with “The capital of France is Berlin.” output if “What’s the capital of France?” enter is given.
RL fine-tuning section
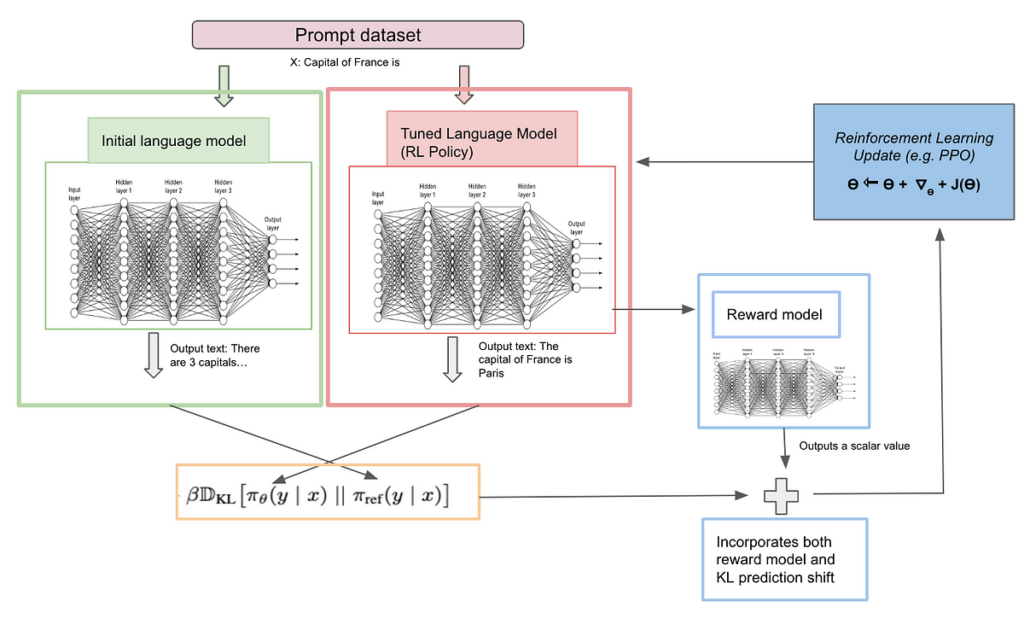
Reinforcement studying concept: Now the base mannequin and reward mannequin are skilled, the thought is leverage reward mannequin rating and replace base mannequin parameters to replicate human desire. Because the reward mannequin outputs a scalar rating and isn’t differentiable, we can’t use easy back-propogation to replace the bottom mannequin param. Therefore, we’d like different methods to replace the bottom mannequin. That is the place reinforcement studying comes which helps the bottom mannequin to vary the params by means of reward mannequin rating. That is completed by means of PPO (proximal coverage optimization). Understanding the core structure of PPO shouldn’t be required to understand this idea and therefore we won’t cowl it right here however on a excessive degree, the thought is that PPO can use scalar rating to replace base mannequin parameters. Now let’s perceive how base and reward fashions are integrated to make base fashions be taught human desire.
RL fine-tuning concept: In reinforcement studying, we’ve motion, area and rewards. The thought is to give you a coverage which any motion agent can take within the area which maximizes the reward. This turns into fairly sophisticated however in a simplified sense, π is the coverage which is our base LLM mannequin solely. Πref means the bottom mannequin and ΠӨ means a special LLM optimum mannequin which we are attempting to generate. We have to discover ΠӨ (the bottom mannequin’s neural community weights shall be fine-tuned) which supplies human-preferred output. It’s simply that we don’t know ΠӨ and the thought is to search out this optimum mannequin.
RL coaching and suggestions loop section: An enter x is given to 2 coverage fashions, Πref (baseline mannequin) and ΠӨ (optimum mannequin which we are attempting to generate). Initially each fashions are stored the identical. Enter x to 2 fashions individually will give two outputs correspondingly. The output from ΠӨ mannequin can be fed to reward mannequin (enter: x, output: y; as mentioned above) and requested to output the reward rating which is rΦ(x, y). Now we’ve 3 issues, output from the baseline mannequin, output from the optimum mannequin, and a reward rating from the optimum mannequin. There are 2 issues we’re optimizing right here, one is to maximize the reward as a result of finally we would like the mannequin to be as shut as human desire and one other is to reduce the divergence from baseline mannequin. Maximizing the reward is simple since it’s already a scalar amount however how can we reduce the divergence of baseline and optimum mannequin. Right here we use “Kullback–Leibler divergence” which estimates the distinction between 2 steady likelihood distributions. Let’s take a deeper look into the target loss perform
Notation:
- rΦ(x, y): a scalar worth for an enter x and output y (from optimum mannequin). To be express, output from the optimum mannequin is fed into the reward mannequin.
- Dkl (ΠӨ (y | x) || Πref (y | x)): This computes the Kullback–Leibler divergence between 2 likelihood distributions. Every token from every mannequin is a likelihood distribution. KL estimates how far the distribution is from one another.
- β : Hyperparameter which is used to find out how essential it’s to have optimum mannequin near baseline mannequin.
Instance situation: Think about you’re asking (“What’s the capital of France?”), Πref (baseline mannequin) says: “The capital of France is Berlin.” and ΠӨ (optimum mannequin) “There are 3 capitals, Paris, Versailles, and Lyon, however Paris is taken into account because the official capital”. Now rΦ(“x: What’s the capital…”, “y: There are 3 capital..”) ought to give low rating as it’s much less human-preferred and Kullback–Leibler divergence of (ΠӨ (y | x) || Πref (y | x)) ought to be excessive as nicely for the reason that likelihood distribution area differs for each particular person output. Therefore the loss shall be excessive from each phrases. We are not looking for the mannequin to solely optimize for reward but in addition keep nearer to the baseline mannequin and therefore each the phrases are used to optimize the reward. Within the subsequent iteration with studying let’s say, ΠӨ (optimum mannequin) says “The capital of France is Delhi”, on this case mannequin discovered to remain nearer to Πref (baseline mannequin) and output the format nearer to baseline mannequin however the reward part will nonetheless be decrease. Hopefully, within the third iteration ΠӨ (optimum mannequin) ought to be capable of be taught and output “The capital of France is Paris” with greater reward and mannequin output aligning intently with baseline mannequin.
The beneath diagram helps illustrate the logic. I can even extremely suggest to undergo RLHF link from hugging face.

With RLHF utilizing a reward-based technique in thoughts, let’s transfer to the reward-free technique. Based on the paper: “our key perception is to leverage an analytical mapping from reward features to optimum insurance policies, which allows us to remodel a loss perform over reward features right into a loss perform over insurance policies. This variation-of-variables strategy avoids becoming an express, standalone reward mannequin, whereas nonetheless optimizing beneath current fashions of human preferences”. Very sophisticated to grasp, however let’s attempt to break this down in easy phases within the subsequent part.
Reward-free technique’s key concept: In RLHF, a separate new reward mannequin is skilled which is pricey and expensive to keep up. Is there any mechanism to keep away from coaching a brand new reward mannequin and use the present base mannequin to attain a brand new optimum mannequin? That is precisely what reward-free technique does i.e. it avoids coaching a brand new reward mannequin and in flip adjustments the equation in such a method that there isn’t any reward mannequin time period within the loss perform of DPO (Direct desire optimization). A method to consider that is that we have to attain optimum mannequin coverage(ΠӨ) from base mannequin (Πref). It may be reached both by means of optimizing the reward perform area which helps construct a proxy to succeed in optimum mannequin coverage or straight studying a mapping perform from reward to coverage and in flip optimize for coverage itself. That is precisely what the authors have tried by eradicating the reward perform part in loss perform and substitute it straight by mannequin coverage parameter. That is what the creator meant after they say “leverage an analytical mapping from reward perform to optimum insurance policies …. right into a loss perform over insurance policies”. That is the core innovation of the paper.
DPO coaching and suggestions loop section: Utilizing Πref (baseline mannequin), enter x is given and requested to supply 2 outputs (y1 and y2). All x, y1 and y2 are utilized by human raters to determine successful yw and shedding yl. Offline information set is collected with triplet data <x, yw and yl>. With this data, we all know what the successful (human most well-liked) and shedding (human not most well-liked) solutions are. Now, the identical enter x is given to 2 coverage (fashions) Πref (baseline mannequin) and ΠӨ (optimum mannequin). Initially each fashions are stored the identical for coaching functions. Enter x to 2 fashions individually will give two outputs correspondingly. We compute how far the output is from successful and shedding solutions from each reference and optimum mannequin by means of “Kullback–Leibler divergence”. Let’s take a deeper look into the target loss perform
Equation
- ΠӨ (yw | x) -> Given x(enter), how far is the corresponding output of the mannequin say youtput from the successful output yw. Output youtput and yw are likelihood distributions and variations amongst each shall be computed by means of “Kullback–Leibler divergence”. This shall be a scalar worth. Additionally that is computed for each fashions with completely different combos of Πref (yw | x), Πref (yl | x), ΠӨ (yw | x) and ΠӨ (yl | x).
- β : Hyperparameter which is used to find out how essential it’s to have optimum mannequin near baseline mannequin.

- Naturally, the query comes right down to which one is best, RLHF by means of reward-based technique utilizing PPO or reward-free technique utilizing DPO. There isn’t any proper reply to this query. A latest paper compares “Is DPO superior to PPO for LLM alignment” (paper link) and concludes that PPO is usually higher than DPO and that DPO suffers extra closely from out-of-distribution information. “Out-of-distribution” information means the human desire information is completely different from the baseline skilled information. This will occur if base mannequin coaching is completed on some dataset whereas desire output is completed for another dataset.
- General, the analysis continues to be out on which one is best whereas we’ve seen corporations like OpenAI, Anthropic, Meta leverage each RLHF by way of PPO and DPO as a software for LLM alignment.