Maximize your Amazon Translate structure utilizing strategic caching layers
Amazon Translate is a neural machine translation service that delivers quick, prime quality, reasonably priced, and customizable language translation. Amazon Translate helps 75 languages and 5,550 language pairs. For the most recent record, see the Amazon Translate Developer Guide. A key advantage of Amazon Translate is its pace and scalability. It might probably translate a big physique of content material or textual content passages in batch mode or translate content material in real-time by API calls. This helps enterprises get quick and correct translations throughout huge volumes of content material together with product listings, help articles, advertising collateral, and technical documentation. When content material units have phrases or sentences which might be typically repeated, you possibly can optimize price by implementing a write-through caching layer. For instance, product descriptions for gadgets include many recurring phrases and specs. That is the place implementing a translation cache can considerably cut back prices. The caching layer shops supply content material and its translated textual content. Then, when the identical supply content material must be translated once more, the cached translation is solely reused as a substitute of paying for a brand-new translation.
On this put up, we clarify how organising a cache for steadily accessed translations can profit organizations that want scalable, multi-language translation throughout giant volumes of content material. You’ll discover ways to construct a easy caching mechanism for Amazon Translate to speed up turnaround occasions.
Answer overview
The caching answer makes use of Amazon DynamoDB to retailer translations from Amazon Translate. DynamoDB capabilities because the cache layer. When a translation is required, the applying code first checks the cache—the DynamoDB desk—to see if the interpretation is already cached. If a cache hit happens, the saved translation is learn from DynamoDB without having to name Amazon Translate once more.
If the interpretation isn’t cached in DynamoDB (a cache miss), then the Amazon Translate API will probably be referred to as to carry out the interpretation. The supply textual content is handed to Amazon Translate, and the translated result’s returned and the interpretation is saved in DynamoDB, populating the cache for the following time that translation is requested.
For this weblog put up, we will probably be utilizing Amazon API Gateway as a relaxation API for translation that integrates with AWS Lambda to carry out backend logic. An Amazon Cognito user pool is used to manage who can entry your translate relaxation API. You can too use different mechanisms to manage authentication and authorization to API Gateway primarily based in your use-case.
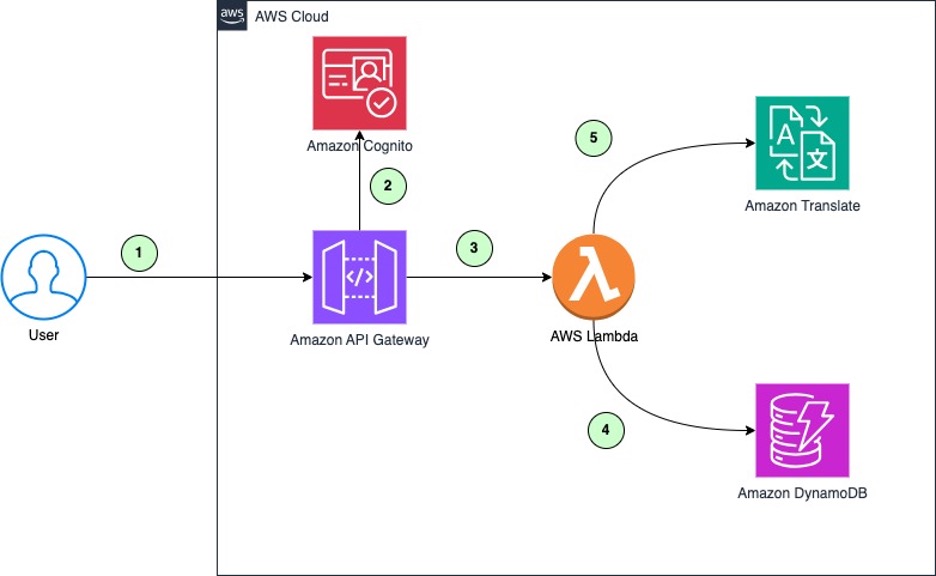
Amazon Translate caching structure

- When a brand new translation is required, the consumer or utility makes a request to the interpretation relaxation API.
- Amazon Cognito verifies the identification token within the request to grant entry to the interpretation relaxation API.
- When new content material is available in for translation, the Amazon API Gateway invokes the Lambda operate that checks the Amazon DynamoDB desk for an present translation.
- If a match is discovered, the interpretation is retrieved from DynamoDB.
- If no match is discovered, the content material is distributed to Amazon Translate to carry out a customized translation utilizing parallel information. The translated content material is then saved in DynamoDB together with a brand new entry for hit fee share.
These high-value translations are periodically post-edited by human translators after which added as parallel information for machine translation. This improves the standard of future translations carried out by Amazon Translate.
We are going to use a easy schema in DynamoDB to retailer the cache entries. Every merchandise will include the next attributes:
src_text:The unique supply textual contenttarget_locale:The goal language to translate totranslated_text:The translated textual contentsrc_locale:The unique supply languagehash:The first key of the desk
The first key will probably be constructed from the src_locale, target_locale, and src_text to uniquely determine cache entries. When retrieving translations, gadgets will probably be appeared up by their major key.
Conditions
To deploy the answer, you want
- An AWS account. In the event you don’t have already got an AWS account, you possibly can create one.
- Your entry to the AWS account will need to have AWS Identity and Access Management (IAM) permissions to launch AWS CloudFormation templates that create IAM roles.
- Set up AWS CLI.
- Set up jq tool.
- AWS Cloud Development Kit (AWS CDK). See Getting started with the AWS CDK.
- Postman put in and configured in your laptop.
Deploy the answer with AWS CDK
We are going to use AWS CDK to deploy the DynamoDB desk for caching translations. CDK permits defining the infrastructure by a well-recognized programming language resembling Python.
- Clone the repo from GitHub.
- Run the
necessities.txt, to put in python dependencies. - Open
app.pyfile and change the AWS account quantity and AWS Area with yours. - To confirm that the AWS CDK is bootstrapped, run
cdk bootstrapfrom the foundation of the repository:
- Outline your CDK stack so as to add DynamoDB and Lambda sources. The DynamoDB and Lambda Features are outlined as follows:
-
- This creates a DynamoDB desk with the first key as hash, as a result of the
TRANSLATION_CACHEdesk is schemaless, you don’t should outline different attributes upfront. This additionally creates a Lambda operate with Python because the runtime.
- This creates a DynamoDB desk with the first key as hash, as a result of the
-
- The Lambda operate is outlined such that it:
- Parses the request physique JSON right into a Python dictionary.
- Extracts the supply locale, goal locale, and enter textual content from the request.
- Will get the DynamoDB desk identify to make use of for a translation cache from setting variables.
- Calls
generate_translations_with_cache()to translate the textual content, passing the locales, textual content, and DynamoDB desk identify. - Returns a 200 response with the translations and processing time within the physique.
- The Lambda operate is outlined such that it:
-
- The
generate_translations_with_cacheoperate divides the enter textual content into separate sentences by splitting on a interval (“.”) image. It shops every sentence as a separate entry within the DynamoDB desk together with its translation. This segmentation into sentences is completed in order that cached translations might be reused for repeating sentences. - In abstract, it’s a Lambda operate that accepts a translation request, interprets the textual content utilizing a cache, and returns the end result with timing data. It makes use of DynamoDB to cache translations for higher efficiency.
- The
- You may deploy the stack by altering the working listing to the foundation of the repository and working the next command.
Issues
Listed here are some further issues when implementing translation caching:
- Eviction coverage: A further column might be outlined indicating the cache expiration of the cache entry. The cache entry can then be evicted by defining a separate course of.
- Cache sizing: Decide anticipated cache measurement and provision DynamoDB throughput accordingly. Begin with on-demand capability if utilization is unpredictable.
- Value optimization: Steadiness caching prices with financial savings from lowering Amazon Translate utilization. Use a brief DynamoDB Time-to-Reside (TTL) and restrict the cache measurement to reduce overhead.
- Delicate Data: DynamoDB encrypts all data at rest by default, if cached translations include delicate information, you possibly can grant entry to approved customers solely. You can too select to not cache information that incorporates delicate data.
Customizing translations with parallel information
The translations generated within the translations desk might be human-reviewed and used as parallel information to customise the translations. Parallel information consists of examples that present the way you need segments of textual content to be translated. It features a assortment of textual examples in a supply language; for every instance, it incorporates the specified translation output in a number of goal languages.
It is a nice method for many use circumstances, however some outliers would possibly require mild post-editing by human groups. The post-editing course of may help you higher perceive the wants of your prospects by capturing the nuances of native language that may be misplaced in translation. For companies and organizations that wish to increase the output of Amazon Translate (and different Amazon synthetic intelligence (AI) providers) with human intelligence, Amazon Augmented AI (Amazon A2I) gives a managed method to take action, see Designing human review workflows with Amazon Translate and Amazon Augmented AI for extra data.
If you add parallel information to a batch translation job, you create an Lively Customized Translation job. If you run these jobs, Amazon Translate makes use of your parallel information at runtime to supply personalized machine translation output. It adapts the interpretation to mirror the fashion, tone, and phrase decisions that it finds in your parallel information. With parallel information, you possibly can tailor your translations for phrases or phrases which might be distinctive to a selected area, resembling life sciences, regulation, or finance. For extra data, see Customizing your translations with parallel data.
Testing the caching setup
Here’s a video walkthrough of testing the answer.
There are a number of methods to check the caching setup. For this instance, you’ll use Postman to check by sending requests. As a result of the Relaxation API is protected by an Amazon Cognito authorizer, you will want to configure Postman to ship an authorization token with the API request.
As a part of the AWS CDK deployment within the earlier step, a Cognito consumer pool is created with an app consumer integration. In your AWS CloudFormation console, you will discover BaseURL, translateCacheEndpoint, UserPoolID, and ClientID on the CDK stack output part. Copy these right into a textual content editor to be used later.

To generate an authorization token from Cognito, the following step is to create a consumer within the Cognito consumer pool.
- Go to the Amazon Cognito console. Choose the consumer pool that was created by the AWS CDK stack.
- Choose the Customers tab and select Create Person.
- Enter the next values and select Create Person.
- On Invitation Message confirm that Don’t ship an invite is chosen.
- For Electronic mail deal with, enter
check@check.com. - On Momentary password, confirm that Set a password is chosen.
- In Password enter
testUser123!.
- Now that the consumer is created, you’ll use AWS Command Line Interface (CLI) to simulate an indication in for the consumer. Go to the AWS CloudShell console.
- Enter the next instructions on the CloudShell terminal by changing
UserPoolIDandClientIDfrom the CloudFormation output of the AWS CDK stack.
Now that you’ve got an authorization token to cross with the API request to your relaxation API. Go to the Postman website. Register to the Postman web site or obtain the Postman desktop client and create a Workspace with the identify dev.
- Choose the workspace dev and select on New request.
- Change the tactic sort to POST from GET.
- Paste the
<TranslateCacheEndpoint>URL from the CloudFormation output of the AWS CDK stack into the request URL textbox. Append the API path/translateto the URL, as proven within the following determine.

Now arrange authorization configuration on Postman in order that requests to the translate API are approved by the Amazon Cognito consumer pool.
- Choose the Authorization tab beneath the request URL in Postman. Choose OAuth2.0 because the Sort.
- Beneath Present Token, copy and paste Your IdToken from earlier into the Token discipline.

- Choose Configure New Token. Beneath Configuration Choices add or choose the values that observe. Copy the BaseURL and ClientID from the CloudFormation output of the AWS CDK stack. Go away the remaining fields on the default values.
-
- Token Title: token
- Grant Sort: Choose Authorization Code
- Callback URL: Enter
https://localhost - Auth URL: Enter
<BaseURL>/oauth2/authorize - Entry Token URL: Enter
<BaseURL>/oauth2/token - ClientID: Enter
<ClientID> - Scope: Enter
openid profile translate-cache/translate - Shopper Authorization: Choose Ship consumer credentials in physique.

- Click on Get New Entry Token. You can be directed to a different web page to check in as a consumer. Use the beneath credentials of the check consumer that was created earlier in your Cognito consumer pool:-
- Username:
check@check.com - Password:
testUser456!
- Username:
- After authenticating, you’ll now get a brand new id_token. Copy the brand new id_token and return to Postman authorization tab to switch that with the token worth underneath Present Token.
- Now, on the Postman request URL and Choose the Physique tab for Request. Choose the uncooked . Change Physique sort to JSON and insert the next JSON content material. When accomplished, select Ship.
First translation request to the API
The primary request to the API takes extra time, as a result of the Lambda operate checks the given enter textual content towards the DynamoDB database on the preliminary request. As a result of that is the primary request, it received’t discover the enter textual content within the desk and can name Amazon Translate to translate the supplied textual content.

Inspecting the processing_seconds worth reveals that this preliminary request took roughly 2.97 seconds to finish.
Subsequent translations requests to the API
After the primary request, the enter textual content and translated output are actually saved within the DynamoDB desk. On subsequent requests with the identical enter textual content, the Lambda operate will first examine DynamoDB for a cache hit. As a result of the desk now incorporates the enter textual content from the primary request, the Lambda operate will discover it there and retrieve the interpretation from DynamoDB as a substitute of calling Amazon Translate once more.
Storing requests in a cache permits subsequent requests for a similar translation to skip the Amazon Translate name, which is normally probably the most time-consuming a part of the method. Retrieving the interpretation from DynamoDB is way sooner than calling Amazon Translate to translate the textual content every time.

The second request has a processing time of roughly 0.79 seconds, about 3 occasions sooner than the primary request which took 2.97 seconds to finish.
Cache purge
Amazon Translate constantly improves its translation fashions over time. To learn from these enhancements, that you must periodically purge translations out of your DynamoDB cache and fetch recent translations from Amazon Translate.
DynamoDB gives a Time-to-Reside (TTL) characteristic that may robotically delete gadgets after a specified expiry timestamp. You should utilize this functionality to implement cache purging. When a translation is saved in DynamoDB, a purge_date attribute set to 30 days sooner or later is added. DynamoDB will robotically delete gadgets shortly after the purge_date timestamp is reached. This ensures cached translations older than 30 days are faraway from the desk. When these expired entries are accessed once more, a cache miss happens and Amazon Translate is named to retrieve an up to date translation.
The TTL-based cache expiration lets you effectively purge older translations on an ongoing foundation. This ensures your purposes can profit from the continual enhancements to the machine studying fashions utilized by Amazon Translate whereas minimizing prices by nonetheless utilizing caching for repeated translations inside a 30-day interval.
Clear up
When deleting a stack, most sources will probably be deleted upon stack deletion, nonetheless that’s not the case for all sources. The DynamoDB desk will probably be retained by default. In the event you don’t wish to retain this desk, you possibly can set this within the AWS CDK code by utilizing RemovalPolicy.
Moreover, the Lambda operate will generate Amazon CloudWatch logs which might be completely retained. These received’t be tracked by CloudFormation as a result of they’re not a part of the stack, so the logs will persist. Use the Cloudwatch console to manually delete any logs that you simply don’t wish to retain.
You may both delete the stack by the CloudFormation console or use AWS CDK destroy from the foundation folder.
Conclusion
The answer outlined on this put up gives an efficient approach to implement a caching layer for Amazon Translate to enhance translation efficiency and cut back prices. Utilizing a cache-aside sample with DynamoDB permits steadily accessed translations to be served from the cache as a substitute of calling Amazon Translate every time.
The caching structure is scalable, safe, and cost-optimized. Further enhancements resembling setting TTLs, including eviction insurance policies, and encrypting cache entries can additional customise the structure to your particular use case.
Translations saved within the cache may also be post-edited and used as parallel information to coach Amazon Translate. This creates a suggestions loop that constantly improves translation high quality over time.
By implementing a caching layer, enterprises can ship quick, high-quality translations tailor-made to their enterprise wants at decreased prices. Caching gives a approach to scale Amazon Translate effectively whereas optimizing efficiency and price.
Further sources
Concerning the authors
 Praneeth Reddy Tekula is a Senior Options Architect specializing in EdTech at AWS. He gives architectural steerage and finest practices to prospects in constructing resilient, safe and scalable techniques on AWS. He’s obsessed with observability and has a robust networking background.
Praneeth Reddy Tekula is a Senior Options Architect specializing in EdTech at AWS. He gives architectural steerage and finest practices to prospects in constructing resilient, safe and scalable techniques on AWS. He’s obsessed with observability and has a robust networking background.
 Reagan Rosario is a Options Architect at AWS, specializing in constructing scalable, extremely accessible, and safe cloud options for schooling know-how firms. With over 10 years of expertise in software program engineering and structure roles, Reagan loves utilizing his technical information to assist AWS prospects architect strong cloud options that leverage the breadth and depth of AWS.
Reagan Rosario is a Options Architect at AWS, specializing in constructing scalable, extremely accessible, and safe cloud options for schooling know-how firms. With over 10 years of expertise in software program engineering and structure roles, Reagan loves utilizing his technical information to assist AWS prospects architect strong cloud options that leverage the breadth and depth of AWS.