Sprinklr improves efficiency by 20% and reduces price by 25% for machine studying inference on AWS Graviton3
It is a visitor put up co-written with Ratnesh Jamidar and Vinayak Trivedi from Sprinklr.
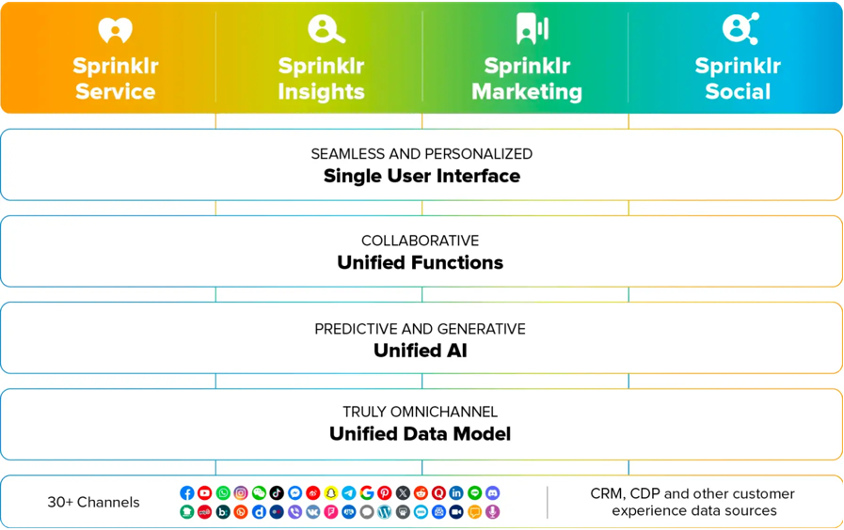
Sprinklr’s mission is to unify silos, know-how, and groups throughout massive, advanced firms. To realize this, we offer 4 product suites, Sprinklr Service, Sprinklr Insights, Sprinklr Advertising and marketing, and Sprinklr Social, in addition to a number of self-serve choices.
Every of those merchandise are infused with synthetic intelligence (AI) capabilities to ship distinctive buyer expertise. Sprinklr’s specialised AI fashions streamline information processing, collect invaluable insights, and allow workflows and analytics at scale to drive higher decision-making and productiveness.

On this put up, we describe the dimensions of our AI choices, the challenges with various AI workloads, and the way we optimized blended AI workload inference efficiency with AWS Graviton3 based mostly c7g cases and achieved 20% throughput enchancment, 30% latency discount, and diminished our price by 25–30%.
Sprinklr’s AI scale and challenges with various AI workloads
Our purpose-built AI processes unstructured buyer expertise information from thousands and thousands of sources, offering actionable insights and enhancing productiveness for customer-facing groups to ship distinctive experiences at scale. To know our scaling and value challenges, let’s have a look at some consultant numbers. Sprinklr’s platform makes use of hundreds of servers that fine-tune and serve over 750 pre-built AI fashions throughout over 60 verticals, and run greater than 10 billion predictions per day.
To ship a tailor-made person expertise throughout these verticals, we deploy patented AI fashions fine-tuned for particular enterprise purposes and use 9 layers of machine studying (ML) to extract that means from information throughout codecs: computerized speech recognition, pure language processing, pc imaginative and prescient, community graph evaluation, anomaly detection, developments, predictive evaluation, pure language technology, and similarity engine.

The various and wealthy database of fashions brings distinctive challenges for selecting essentially the most environment friendly deployment infrastructure that provides the perfect latency and efficiency.
For instance, for blended AI workloads, the AI inference is a part of the search engine service with real-time latency necessities. In these instances, the mannequin sizes are smaller, which suggests the communication overhead with GPUs or ML accelerator cases outweighs their compute efficiency advantages. Additionally, inference requests are rare, which suggests accelerators are extra usually idle and never cost-effective. Subsequently, the manufacturing cases weren’t cost-effective for these blended AI workloads, inflicting us to search for new cases that supply the suitable steadiness of scale and cost-effectiveness.
Price-effective ML inference utilizing AWS Graviton3
Graviton3 processors are optimized for ML workloads, together with assist for bfloat16, Scalable Vector Extension (SVE), twice the Single Instruction A number of Knowledge (SIMD) bandwidth, and 50% extra reminiscence bandwidth in comparison with AWS Graviton2 processors, making them a really perfect selection for our blended workloads. Our purpose is to make use of the newest applied sciences for effectivity and value financial savings, so when AWS launched Graviton3-based Amazon Elastic Compute Cloud (Amazon EC2) cases, we have been excited to attempt them in our blended workloads, particularly given our earlier Graviton expertise. For over 3 years, we’ve run our search infrastructure on Graviton2-based EC2 cases and our real-time and batched inference workloads on AWS Inferentia ML-accelerated cases, and in each instances we improved latency by 30% and achieved as much as 40% price-performance advantages over comparable x86 cases.
Emigrate our blended AI workloads from x86-based cases to Graviton3-based c7g cases, we took a two-step method. First, we needed to experiment and benchmark with the intention to decide that Graviton3 was certainly the suitable resolution for us. After that was confirmed, we needed to carry out the precise migration.
First, we began by benchmarking our workloads utilizing the available Graviton Deep Learning Containers (DLCs) in a standalone atmosphere. As early adopters of Graviton for ML workloads, it was initially difficult to determine the suitable software program variations and the runtime tunings. Throughout this journey, we collaborated with our AWS technical account supervisor and the Graviton software program engineering groups. We collaborated carefully and continuously for the optimized software program packages and detailed directions on find out how to tune them to attain optimum efficiency. In our check atmosphere, we noticed 20% throughput enchancment and 30% latency discount throughout a number of pure language processing fashions.
After we had validated that Graviton3 met our wants, we built-in the optimizations into our manufacturing software program stack. The AWS account crew assisted us promptly, serving to us ramp up shortly to fulfill our deployment timelines. Total, migration to Graviton3-based cases was clean, and it took lower than 2 months to attain the efficiency enhancements in our manufacturing workloads.
Outcomes
By migrating our blended inference/search workloads to Graviton3-based c7g cases from the comparable x86-based cases, we achieved the next:
- Greater efficiency – We realized 20% throughput enchancment and 30% latency discount.
- Diminished price – We achieved 25–30% price financial savings.
- Improved buyer expertise – By decreasing the latency and growing throughput, we considerably improved the efficiency of our services and products, offering the perfect person expertise for our prospects.
- Sustainable AI – As a result of we noticed a better throughput on the identical variety of cases, we have been in a position to decrease our total carbon footprint, and we made our merchandise interesting to environmentally aware prospects.
- Higher software program high quality and upkeep – The AWS engineering crew upstreamed all of the software program optimizations into PyTorch and TensorFlow open supply repositories. In consequence, our present software program improve course of on Graviton3-based cases is seamless. For instance, PyTorch (v2.0+), TensorFlow (v2.9+), and Graviton DLCs include Graviton3 optimizations and the user guides present greatest practices for runtime tuning.
To this point, we’ve migrated PyTorch and TensorFlow based mostly Distil RoBerta-base, spaCy clustering, prophet, and xlmr fashions to Graviton3-based c7g cases. These fashions are serving intent detection, textual content clustering, inventive insights, textual content classification, good funds allocation, and picture obtain companies. These companies energy our unified buyer expertise (unified-cxm) platform and conversional AI to permit manufacturers to construct extra self-serve use instances for his or her prospects. Subsequent, we’re migrating ONNX and different bigger fashions to Graviton3-based m7g normal goal and Graviton2-based g5g GPU cases to attain comparable efficiency enhancements and value financial savings.
Conclusion
Switching to Graviton3-based cases was fast by way of engineering time, and resulted in 20% throughput enchancment, 30% latency discount, 25–30% price financial savings, improved buyer expertise, and a decrease carbon footprint for our workloads. Primarily based on our expertise, we are going to proceed to hunt new compute from AWS that can scale back our prices and enhance the shopper expertise.
For additional studying, consult with the next:
Concerning the Authors
 Sunita Nadampalli is a Software program Improvement Supervisor at AWS. She leads Graviton software program efficiency optimizations for Machine Studying and HPC workloads. She is captivated with open supply software program improvement and delivering high-performance and sustainable software program options with Arm SoCs.
Sunita Nadampalli is a Software program Improvement Supervisor at AWS. She leads Graviton software program efficiency optimizations for Machine Studying and HPC workloads. She is captivated with open supply software program improvement and delivering high-performance and sustainable software program options with Arm SoCs.
 Gaurav Garg is a Sr. Technical Account Supervisor at AWS with 15 years of expertise. He has a robust operations background. In his function he works with Impartial Software program Distributors to construct scalable and cost-effective options with AWS that meet the enterprise necessities. He’s captivated with Safety and Databases.
Gaurav Garg is a Sr. Technical Account Supervisor at AWS with 15 years of expertise. He has a robust operations background. In his function he works with Impartial Software program Distributors to construct scalable and cost-effective options with AWS that meet the enterprise necessities. He’s captivated with Safety and Databases.
 Ratnesh Jamidar is a AVP Engineering at Sprinklr with 8 years of expertise. He’s a seasoned Machine Studying skilled with experience in designing, implementing large-scale, distributed, and extremely obtainable AI merchandise and infrastructure.
Ratnesh Jamidar is a AVP Engineering at Sprinklr with 8 years of expertise. He’s a seasoned Machine Studying skilled with experience in designing, implementing large-scale, distributed, and extremely obtainable AI merchandise and infrastructure.
 Vinayak Trivedi is an Affiliate Director of Engineering at Sprinklr with 4 years of expertise in Backend & AI. He’s proficient in Utilized Machine Studying & Knowledge Science, with a historical past of constructing large-scale, scalable and resilient techniques.
Vinayak Trivedi is an Affiliate Director of Engineering at Sprinklr with 4 years of expertise in Backend & AI. He’s proficient in Utilized Machine Studying & Knowledge Science, with a historical past of constructing large-scale, scalable and resilient techniques.