How Skyflow creates technical content material in days utilizing Amazon Bedrock
This visitor put up is co-written with Manny Silva, Head of Documentation at Skyflow, Inc.
Startups transfer shortly, and engineering is usually prioritized over documentation. Sadly, this prioritization results in launch cycles that don’t match, the place options launch however documentation lags behind. This results in elevated help calls and sad clients.
Skyflow is an information privateness vault supplier that makes it easy to safe delicate information and implement privateness insurance policies. Skyflow skilled this development and documentation problem in early 2023 because it expanded globally from 8 to 22 AWS Areas, together with China and different areas of the world. The documentation group, consisting of solely two individuals, discovered itself overwhelmed because the engineering group, with over 60 individuals, up to date the product to help the dimensions and speedy characteristic launch cycles.
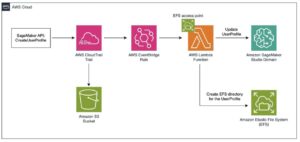
Given the crucial nature of Skyflow’s function as an information privateness firm, the stakes have been significantly excessive. Clients entrust Skyflow with their information and anticipate Skyflow to handle it each securely and precisely. The accuracy of Skyflow’s technical content material is paramount to incomes and retaining buyer belief. Though new options have been launched each different week, documentation for the options took a mean of three weeks to finish, together with drafting, evaluation, and publication. The next diagram illustrates their content material creation workflow.

Taking a look at our documentation workflows, we at Skyflow found areas the place generative artificial intelligence (AI) may enhance our effectivity. Particularly, creating the primary draft—sometimes called overcoming the “clean web page drawback”—is often probably the most time-consuming step. The evaluation course of is also lengthy relying on the variety of inaccuracies discovered, resulting in further revisions, further opinions, and extra delays. Each drafting and reviewing wanted to be shorter to make doc goal timelines match these of engineering.
To do that, Skyflow constructed VerbaGPT, a generative AI instrument based mostly on Amazon Bedrock. Amazon Bedrock is a completely managed service that makes basis fashions (FMs) from main AI startups and Amazon out there by means of an API, so you possibly can select from a variety of FMs to seek out the mannequin that’s greatest suited in your use case. With the Amazon Bedrock serverless expertise, you will get began shortly, privately customise FMs with your individual information, and combine and deploy them into your purposes utilizing the AWS instruments with out having to handle any infrastructure. With Amazon Bedrock, VerbaGPT is ready to immediate massive language fashions (LLMs), no matter mannequin supplier, and makes use of Retrieval Augmented Era (RAG) to offer correct first drafts that make for fast opinions.
On this put up, we share how Skyflow improved their workflow to create documentation in days as an alternative of weeks utilizing Amazon Bedrock.
Answer overview
VerbaGPT makes use of Contextual Composition (CC), a method that includes a base instruction, a template, related context to tell the execution of the instruction, and a working draft, as proven within the following determine. For the instruction, VerbaGPT tells the LLM to create content material based mostly on the desired template, consider the context to see if it’s relevant, and revise the draft accordingly. The template consists of the construction of the specified output, expectations for what kind of data ought to exist in a piece, and a number of examples of content material for every part to information the LLM on the way to course of context and draft content material appropriately. With the instruction and template in place, VerbaGPT consists of as a lot out there context from RAG outcomes as it may well, then sends that off for inference. The LLM returns the revised working draft, which VerbaGPT then passes again into a brand new immediate that features the identical instruction, the identical template, and as a lot context as it may well match, ranging from the place the earlier iteration left off. This repeats till all context is taken into account and the LLM outputs a draft matching the included template.

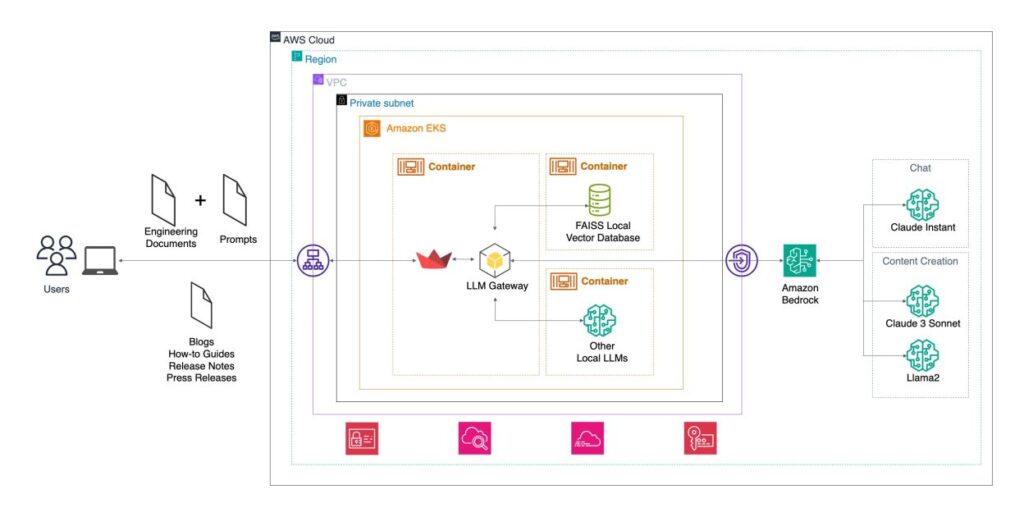
The next determine illustrates how Skyflow deployed VerbaGPT on AWS. The appliance is utilized by the documentation group and inside customers. The answer includes deploying containers on Amazon Elastic Kubernetes Service (Amazon EKS) that host a Streamlit consumer interface and a backend LLM gateway that is ready to invoke Amazon Bedrock or native LLMs, as wanted. Customers add paperwork and immediate VerbaGPT to generate new content material. Within the LLM gateway, prompts are processed in Python utilizing LangChain and Amazon Bedrock.

When constructing this resolution on AWS, Skyflow adopted these steps:
- Select an inference toolkit and LLMs.
- Construct the RAG pipeline.
- Create a reusable, extensible immediate template.
- Create content material templates for every content material sort.
- Construct an LLM gateway abstraction layer.
- Construct a frontend.
Let’s dive into every step, together with the targets and necessities and the way they have been addressed.
Select an inference toolkit and LLMs
The inference toolkit you select, if any, dictates your interface along with your LLMs and what different tooling is on the market to you. VerbaGPT makes use of LangChain as an alternative of instantly invoking LLMs. LangChain has broad adoption within the LLM neighborhood, so there was a gift and sure future capability to reap the benefits of the newest developments and neighborhood help.
When constructing a generative AI utility, there are lots of components to think about. As an example, Skyflow needed the pliability to work together with completely different LLMs relying on the use case. We additionally wanted to maintain context and immediate inputs non-public and safe, which meant not utilizing LLM suppliers who would log that data or fine-tune their fashions on our information. We would have liked to have quite a lot of fashions with distinctive strengths at our disposal (corresponding to lengthy context home windows or textual content labeling) and to have inference redundancy and fallback choices in case of outages.
Skyflow selected Amazon Bedrock for its strong help of a number of FMs and its give attention to privateness and safety. With Amazon Bedrock, all visitors stays inside AWS. VerbaGPT’s major basis mannequin is Anthropic Claude 3 Sonnet on Amazon Bedrock, chosen for its substantial context size, although it additionally makes use of Anthropic Claude Instantaneous on Amazon Bedrock for chat-based interactions.
Construct the RAG pipeline
To ship correct and grounded responses from LLMs with out the necessity for fine-tuning, VerbaGPT makes use of RAG to fetch information associated to the consumer’s immediate. Through the use of RAG, VerbaGPT grew to become accustomed to the nuances of Skyflow’s options and procedures, enabling it to generate knowledgeable and complimentary content material.
To construct your individual content material creation resolution, you gather your corpus right into a information base, vectorize it, and retailer it in a vector database. VerbaGPT consists of all of Skyflow’s documentation, weblog posts, and whitepapers in a vector database that it may well question throughout inference. Skyflow makes use of a pipeline to embed content material and retailer the embedding in a vector database. This embedding pipeline is a multi-step course of, and everybody’s pipeline goes to look a bit of completely different. Skyflow’s pipeline begins by transferring artifacts to a typical information retailer, the place they’re de-identified. In case your paperwork have personally identifiable data (PII), cost card data (PCI), private well being data (PHI), or different delicate information, you would possibly use an answer like Skyflow LLM Privacy Vault to make de-identifying your documentation simple. Subsequent, the pipeline chunks the paperwork into items, then lastly calculates vectors for the textual content chunks and shops them in FAISS, an open supply vector retailer. VerbaGPT makes use of FAISS as a result of it’s quick and easy to make use of from Python and LangChain. AWS additionally has quite a few vector shops to select from for a extra enterprise-level content material creation resolution, together with Amazon Neptune, Amazon Relational Database Service (Amazon RDS) for PostgreSQL, Amazon Aurora PostgreSQL-Compatible Edition, Amazon Kendra, Amazon OpenSearch Service, and Amazon DocumentDB (with MongoDB compatibility). The next diagram illustrates the embedding era pipeline.

When chunking your paperwork, understand that LangChain’s default splitting technique could be aggressive. This can lead to chunks of content material which are so small that they lack significant context and end in worse output, as a result of the LLM has to make (largely inaccurate) assumptions concerning the context, producing hallucinations. This challenge is especially noticeable in Markdown recordsdata, the place procedures have been fragmented, code blocks have been divided, and chunks have been usually solely single sentences. Skyflow created its personal Markdown splitter to work extra precisely with VerbaGPT’s RAG output content material.
Create a reusable, extensible immediate template
After you deploy your embedding pipeline and vector database, you can begin intelligently prompting your LLM with a immediate template. VerbaGPT makes use of a system immediate that instructs the LLM the way to behave and features a directive to make use of content material within the Context part to tell the LLM’s response.
The inference course of queries the vector database with the consumer’s immediate, fetches the outcomes above a sure similarity threshold, and consists of the leads to the system immediate. The answer then sends the system immediate and the consumer’s immediate to the LLM for inference.
The next is a pattern immediate for drafting with Contextual Composition that features all the mandatory parts, system immediate, template, context, a working draft, and extra directions:
Create content material templates
To spherical out the immediate template, it’s worthwhile to outline content material templates that match your required output, corresponding to a weblog put up, how-to information, or press launch. You’ll be able to jumpstart this step by sourcing high-quality templates. Skyflow sourced documentation templates from The Good Docs Project. Then, we tailored the how-to and idea templates to align with inside types and particular wants. We additionally tailored the templates to be used in immediate templates by offering directions and examples per part. By clearly and persistently defining the anticipated construction and supposed content material of every part, the LLM was in a position to output content material within the codecs wanted, whereas being each informative and stylistically per Skyflow’s model.
LLM gateway abstraction layer
Amazon Bedrock supplies a single API to invoke quite a lot of FMs. Skyflow additionally needed to have inference redundancy and fallback choices in case VerbaGPT skilled Amazon Bedrock service restrict exceeded errors. To that finish, VerbaGPT has an LLM gateway that acts as an abstraction layer that’s invoked.
The principle part of the gateway is the mannequin catalog, which may return a LangChain llm mannequin object for the desired mannequin, up to date to incorporate any parameters. You’ll be able to create this with a easy if/else assertion like that proven within the following code:
By mapping normal enter codecs into the perform and dealing with all customized LLM object development throughout the perform, the remainder of the code stays clear by utilizing LangChain’s llm object.
Construct a frontend
The ultimate step was so as to add a UI on high of the applying to cover the internal workings of LLM calls and context. A easy UI is vital for generative AI purposes, so customers can effectively immediate the LLMs with out worrying concerning the particulars pointless to their workflow. As proven within the resolution structure, VerbaGPT makes use of Streamlit to shortly construct helpful, interactive UIs that permit customers to add paperwork for added context and draft new paperwork quickly utilizing Contextual Composition. Streamlit is Python based mostly, which makes it simple for information scientists to be environment friendly at constructing UIs.
Outcomes
Through the use of the ability of Amazon Bedrock for inferencing and Skyflow for information privateness and delicate information de-identification, your group can considerably velocity up the manufacturing of correct, safe technical paperwork, similar to the answer proven on this put up. Skyflow was ready to make use of current technical content material and best-in-class templates to reliably produce drafts of various content material varieties in minutes as an alternative of days. For instance, given a product necessities doc (PRD) and an engineering design doc, VerbaGPT can produce drafts for a how-to information, conceptual overview, abstract, launch notes line merchandise, press launch, and weblog put up inside 10 minutes. Usually, this might take a number of people from completely different departments a number of days every to provide.
The brand new content material circulation proven within the following determine strikes generative AI to the entrance of all technical content material Skyflow creates. In the course of the “Create AI draft” step, VerbaGPT generates content material within the accepted model and format in simply 5 minutes. Not solely does this resolve the clean web page drawback, first drafts are created with much less interviewing or asking engineers to draft content material, releasing them so as to add worth by means of characteristic growth as an alternative.

The safety measures Amazon Bedrock supplies round prompts and inference aligned with Skyflow’s dedication to information privateness, and allowed Skyflow to make use of further sorts of context, corresponding to system logs, with out the priority of compromising delicate data in third-party programs.
As extra individuals at Skyflow used the instrument, they needed further content material varieties out there: VerbaGPT now has templates for inside studies from system logs, e mail templates from widespread dialog varieties, and extra. Moreover, though Skyflow’s RAG context is clear, VerbaGPT is built-in with Skyflow LLM Privateness Vault to de-identify delicate information in consumer inference inputs, sustaining Skyflow’s stringent requirements of knowledge privateness and safety even whereas utilizing the ability of AI for content material creation.
Skyflow’s journey in constructing VerbaGPT has drastically shifted content material creation, and the toolkit wouldn’t be as strong, correct, or versatile with out Amazon Bedrock. The numerous discount in content material creation time—from a mean of round 3 weeks to as little as 5 days, and typically even a outstanding 3.5 days—marks a considerable leap in effectivity and productiveness, and highlights the ability of AI in enhancing technical content material creation.
Conclusion
Don’t let your documentation lag behind your product growth. Begin creating your technical content material in days as an alternative of weeks, whereas sustaining the very best requirements of knowledge privateness and safety. Be taught extra about Amazon Bedrock and uncover how Skyflow can remodel your method to information privateness.
In the event you’re scaling globally and have privateness or information residency wants in your PII, PCI, PHI, or different delicate information, attain out to your AWS consultant to see if Skyflow is on the market in your area.
Concerning the authors
 Manny Silva is Head of Documentation at Skyflow and the creator of Doc Detective. Technical author by day and engineer by evening, he’s obsessed with intuitive and scalable developer experiences and likes diving into the deep finish because the 0th developer.
Manny Silva is Head of Documentation at Skyflow and the creator of Doc Detective. Technical author by day and engineer by evening, he’s obsessed with intuitive and scalable developer experiences and likes diving into the deep finish because the 0th developer.
 Jason Westra is a Senior Options Architect for AWS AI/ML startups. He supplies steerage and technical help that allows clients to construct scalable, extremely out there, safe AI and ML workloads in AWS Cloud.
Jason Westra is a Senior Options Architect for AWS AI/ML startups. He supplies steerage and technical help that allows clients to construct scalable, extremely out there, safe AI and ML workloads in AWS Cloud.