Enhance productiveness with video conferencing transcripts and summaries with the Amazon Chime SDK Assembly Summarizer resolution
Companies at this time closely depend on video conferencing platforms for efficient communication, collaboration, and decision-making. Nonetheless, regardless of the comfort these platforms provide, there are persistent challenges in seamlessly integrating them into present workflows. One of many main ache factors is the shortage of complete instruments to automate the method of becoming a member of conferences, recording discussions, and extracting actionable insights from them. This hole ends in inefficiencies, missed alternatives, and restricted productiveness, hindering the seamless move of knowledge and decision-making processes inside organizations.
To handle this problem, we’ve developed the Amazon Chime SDK Assembly Summarizer software deployed with the Amazon Cloud Development Kit (AWS CDK). This software makes use of an Amazon Chime SDK SIP media software, Amazon Transcribe, and Amazon Bedrock to seamlessly be a part of conferences, document assembly audio, and course of recordings for transcription and summarization. By integrating these companies programmatically by means of the AWS CDK, we purpose to streamline the assembly workflow, empower customers with actionable insights, and drive higher decision-making outcomes. Our resolution presently integrates with well-liked platforms reminiscent of Amazon Chime, Zoom, Cisco Webex, Microsoft Groups, and Google Meet.
Along with deploying the answer, we’ll additionally train you the intricacies of immediate engineering on this submit. We information you thru addressing parsing and data extraction challenges, together with speaker diarization, name scheduling, summarization, and transcript cleansing. By way of detailed directions and structured approaches tailor-made to every use case, we illustrate the effectiveness of Amazon Bedrock, powered by Anthropic Claude fashions.
Resolution overview
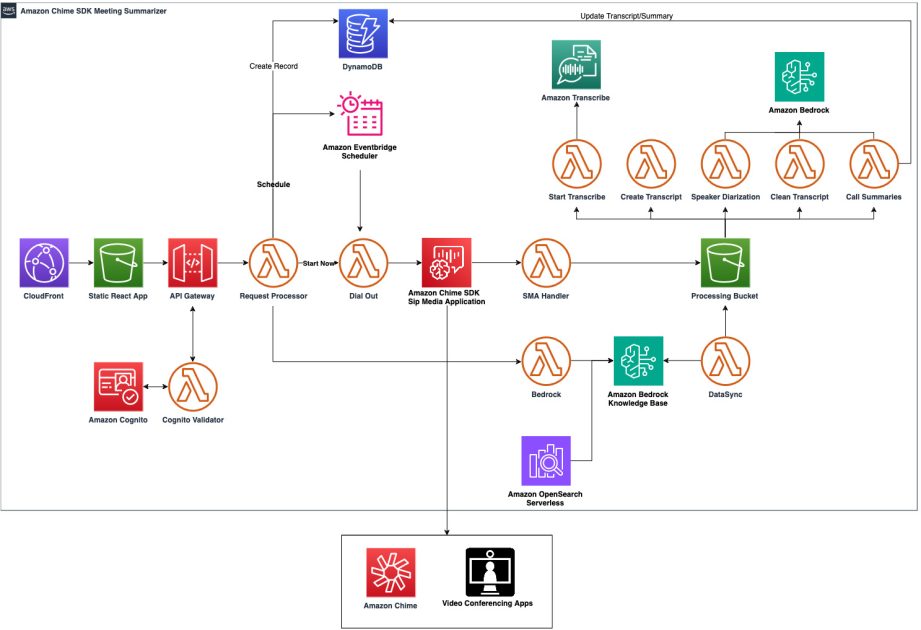
The next infrastructure diagram offers an summary of the AWS companies which can be used to create this assembly summarization bot. The core companies used on this resolution are:
- An Amazon Chime SDK SIP Media Application is used to dial into the assembly and document assembly audio
- Amazon Transcribe is used to carry out speech-to-text processing of the recorded audio, together with speaker diarization
- Anthropic Claude models in Amazon Bedrock are used to determine names, enhance the standard of the transcript, and supply an in depth abstract of the assembly
For an in depth clarification of the answer, confer with the Amazon Chime Meeting Summarizer documentation.

Conditions
Earlier than diving into the mission setup, ensure you have the next necessities in place:
- Yarn – Yarn have to be put in in your machine.
- AWS account – You’ll want an lively AWS account.
- Allow Claude Anthropic fashions – These fashions needs to be enabled in your AWS account. For extra data, see Model access.
- Allow Amazon Titan – Amazon Titan needs to be activated in your AWS account. For extra data, see Amazon Titan Models.
Seek advice from our GitHub repository for a step-by-step information on deploying this resolution.
Entry the assembly with Amazon Chime SDK
To seize the audio of a gathering, an Amazon Chime SDK SIP media software will dial into the assembly utilizing the assembly supplier’s dial-in quantity. The Amazon Chime SDK SIP media software (SMA) is a programable telephony service that can make a telephone name over the general public switched phone community (PSTN) and seize the audio. SMA makes use of a request/response model with an AWS Lambda function to course of actions. On this demo, an outbound name is made utilizing the CreateSipMediaApplicationCall API. This may trigger the Lambda operate to be invoked with a NEW_OUTBOUND_CALL occasion.
As a result of most dial-in mechanisms for conferences require a PIN or different identification to be made, the SMA will use the SendDigits motion to ship these twin tone multi-frequency (DTMF) digits to the assembly supplier. When the appliance has joined the assembly, it should introduce itself utilizing the Speak motion after which document the audio utilizing the RecordAudio motion. This audio shall be saved in MP3 format and saved to an Amazon Simple Storage Service (Amazon S3) bucket.
Speaker diarization with Amazon Transcribe
As a result of the SMA is joined to the assembly as a participant, the audio shall be a single channel of all of the individuals. To course of this audio file, Amazon Transcribe shall be used with the ShowSpeakerLabels setting:
With speaker diarization, Amazon Transcribe will distinguish totally different audio system within the transcription output. The JSON file that’s produced will embrace the transcripts and objects together with speaker labels grouped by speaker with begin and finish timestamps. With this data supplied by Amazon Transcribe, a turn-by-turn transcription might be generated by parsing by means of the JSON. The consequence shall be a extra readable transcription. See the next instance:
spk_0: Hey Court docket , how’s it going ?
spk_1: Hey Adam, it’s going good . How are you
spk_0: doing ? Properly , uh hey , thanks for uh becoming a member of me at this time on this name . I’m excited to speak to you about uh architecting on Aws .
spk_1: Superior . Yeah , thanks for inviting me . So ,
spk_0: uh are you able to inform me somewhat bit about uh the servers you’re presently utilizing on premises ?
spk_1: Yeah . So for our servers , we presently have 4 internet servers working with 4 gigabyte of RA M and two CP US and we’re presently working Linux as our working system .
spk_0: Okay . And what are you utilizing to your database ?
spk_1: Oh , yeah , for a database , we presently have a 200 gigabyte database working my as to will and I can’t bear in mind the model . However um the factor about our database is typically it lags . So we’re actually in search of a sooner possibility for
spk_0: that . So , um while you’re , you’re noticing lags with reads or with rights to the database
spk_1: with , with reads .
spk_0: Yeah . Okay . Have you ever heard of uh learn replicas ?
spk_1: I’ve not .
spk_0: Okay . That might be a possible uh resolution to your downside . Um When you don’t thoughts , I’ll go forward and simply uh ship you some data on that later for you and your crew to assessment .
spk_1: Oh , yeah , thanks , Adam . Yeah . Something that would assist . Yeah , be actually useful .
spk_0: Okay , final query earlier than I allow you to go . Um what are you doing uh to enhance the safety of your on premises ? Uh knowledge ?
spk_1: Yeah , so , so primary , we have now been experiencing some esto injection assaults . We do have a Palo Alto firewall , however we’re not capable of absolutely obtain layer server safety . So we do want a greater possibility for that .
spk_0: Have you ever ex have you ever skilled uh my sequel assaults prior to now or sequel injections ?
spk_1: Sure.
spk_0: Okay , nice . Uh All proper . After which are you guys sure by any compliance requirements like PC I DS S or um you already know GDR ? Uh what’s one other one ? Any of these C simply uh
spk_1: we’re sure by destiny , average complaints . So .
spk_0: Okay . Properly , it’s important to transition to fed ramp excessive at any time .
spk_1: Uh Not within the close to future . No .
spk_0: Okay . All proper , Court docket . Properly , thanks for that uh context . I shall be reaching out to you once more right here quickly with a comply with up e-mail and uh yeah , I’m wanting ahead to speaking to you once more uh subsequent week .
spk_1: Okay . Sounds good . Thanks , Adam to your assist .
spk_0: All proper . Okay , bye .
spk_1: All proper . Take care .
Right here, audio system have been recognized primarily based on the order they spoke. Subsequent, we present you tips on how to additional improve this transcription by figuring out audio system utilizing their names, moderately than spk_0, spk_1, and so forth.
Use Anthropic Claude and Amazon Bedrock to reinforce the answer
This software makes use of a big language mannequin (LLM) to finish the next duties:
- Speaker title identification
- Transcript cleansing
- Name summarization
- Assembly invitation parsing
Immediate engineering for speaker title identification
The primary process is to reinforce the transcription by assigning names to speaker labels. These names are extracted from the transcript itself when an individual introduces themselves after which are returned as output in JSON format by the LLM.
Particular directions are supplied for instances the place just one speaker is recognized to offer consistency within the response construction. By following these directions, the LLM will course of the assembly transcripts and precisely extract the names of the audio system with out extra phrases or spacing within the response. If no names are recognized by the LLM, we prompted the mannequin to return an Unknown tag.
On this demo, the prompts are designed utilizing Anthropic Claude Sonnet because the LLM. You might must tune the prompts to switch the answer to make use of one other accessible mannequin on Amazon Bedrock.
Human: You’re a assembly transcript names extractor. Go over the transcript and extract the names from it. Use the next directions within the <directions></directions> xml tags
<transcript> ${transcript} </transcript>
<directions>
– Extract the names like this instance – spk_0: “name1”, spk_1: “name2”.
– Solely extract the names like the instance above and don’t add every other phrases to your response
– Your response ought to solely have a listing of “audio system” and their related title separated by a “:” surrounded by {}
– if there is just one speaker recognized then encompass your reply with {}
– the format ought to seem like this {“spk_0” : “Title”, “spk_1: “Name2”, and many others.}, no pointless spacing needs to be added
</directions>Assistant: Ought to I add anything in my reply?
Human: Solely return a JSON formatted response with the Title and the speaker label related to it. Don’t add every other phrases to your reply. Do NOT EVER add any introductory sentences in your reply. Solely give the names of the audio system actively talking within the assembly. Solely give the names of the audio system actively talking within the assembly within the format proven above.
Assistant:
After the audio system are recognized and returned in JSON format, we will substitute the generic speaker labels with the title attributed speaker labels within the transcript. The consequence shall be a extra enhanced transcription:
Adam: Hey Court docket , how’s it going ?
Court docket: Hey Adam , it’s going good . How are you
Adam: doing ? Properly , uh hey , thanks for uh becoming a member of me at this time on this name . I’m excited to speak to you about uh architecting on Aws .
Court docket: Superior . Yeah , thanks for inviting me . So ,
Adam: uh are you able to inform me somewhat bit about uh the servers you’re presently utilizing on premises ?
Court docket: Yeah . So for our servers , we presently have 4 internet servers working with 4 gigabyte of RA M and two CP US and we’re presently working Linux as our working system .… transcript continues….
However what if a speaker can’t be recognized as a result of they by no means launched themselves. In that case, we wish to let the LLM depart them as unknown, moderately than attempt to pressure or a hallucinate a label.
We are able to add the next to the directions:
If no title is discovered for a speaker, use UNKNOWN_X the place X is the speaker label quantity
The next transcript has three audio system, however solely two recognized audio system. The LLM should label a speaker as UNKNOWN moderately than forcing a reputation or different response on the speaker.
spk_0: Yeah .
spk_1: Uh Thanks for becoming a member of us Court docket . I’m your account govt right here at Aws . Uh Becoming a member of us on the decision is Adam , one in all our options architect at Aws . Adam want to introduce your self .
spk_2: Hey , everyone . Excessive Court docket . Good to satisfy you . Uh As your devoted options architect right here at Aws . Uh my job is to assist uh you at each step of your cloud journey . Uh My , my position includes serving to you perceive architecting on Aws , together with finest practices for the cloud . Uh So with that , I’d like it in the event you may simply take a minute to introduce your self and perhaps inform me somewhat about what you’re presently working on premises .
spk_0: Yeah , nice . It’s uh nice to satisfy you , Adam . Um My title is Court docket . I’m the V P of engineering right here at any firm . And uh yeah , actually excited to listen to what you are able to do for us .
spk_1: Thanks , work . Properly , we , we talked somewhat little bit of final time about your targets for migrating to Aws . I invited Adam to , to affix us at this time to get a greater understanding of your present infrastructure and different technical necessities .
spk_2: Yeah . So co may you inform me somewhat bit about what you’re presently working on premises ?
spk_1: Certain . Yeah , we’re , uh ,
spk_0: we’re working a 3 tier internet app on premise .
After we give Claude Sonnet the choice to not pressure a reputation , we see outcomes like this:
{“spk_0”: “Court docket”, “spk_1”: “UNKNOWN_1”, “spk_2”: “Adam”}
Immediate engineering for cleansing the transcript
Now that the transcript has been diarized with speaker attributed names, we will use Amazon Bedrock to scrub the transcript. Cleansing duties embrace eliminating distracting filler phrases, figuring out and rectifying misattributed homophones, and addressing any diarization errors stemming from subpar audio high quality. For steerage on conducting these duties utilizing Anthropic Claude Sonnet fashions, see the supplied immediate:
Human: You’re a transcript editor, please comply with the <directions> tags.
<transcript> ${transcript} </transcript>
<directions>
– The <transcript> incorporates a speaker diarized transcript
– Go over the transcript and take away all filler phrases. For instance “um, uh, er, properly, like, you already know, okay, so, really, mainly, actually, anyway, actually, proper, I imply.”
– Repair any errors in transcription which may be attributable to homophones primarily based on the context of the sentence. For instance, “one as an alternative of received” or “excessive as an alternative of hello”
– As well as, please repair the transcript in instances the place diarization is badly carried out. For instance, in some instances you will notice that sentences are break up between two audio system. On this case infer who the precise speaker is and attribute it to them.– Please assessment the next instance of this,
Enter Instance
Court docket: Adam you’re saying the unsuitable factor. What
Adam: um do you imply, Court docket?Output:
Court docket: Adam you’re saying the unsuitable factor.
Adam: What do you imply, Court docket?– In your response, return your entire cleaned transcript, together with all the filler phrase elimination and the improved diarization. Solely return the transcript, don’t embrace any main or trailing sentences. You aren’t summarizing. You might be cleansing the transcript. Don’t embrace any xml tags <>
</directions>
Assistant:
Transcript Processing
After the preliminary transcript is handed into the LLM, it returns a refined transcript, free from errors. The next are excerpts from the transcript:
Speaker Identification
Enter:
spk_0: Hey Court docket , how’s it going ?
spk_1: Hey Adam, it’s going good . How are you
spk_0: doing ? Properly , uh hey , thanks for uh becoming a member of me at this time on this name . I’m excited to speak to you about uh architecting on Aws .
Output:
Adam: Hey Court docket, how’s it going?
Court docket: Hey Adam, it’s going good. How are you?
Adam: Thanks for becoming a member of me at this time. I’m excited to speak to you about architecting on AWS
Homophone Substitute
Enter:
Adam: Have you ever ex have you ever skilled uh my sequel assaults prior to now or sequel injections ?
Court docket: Sure .
Output:
Adam: Have you ever skilled SQL injections prior to now?
Court docket: Sure.
Filler Phrase Removing
Enter:
Adam: Okay , nice . Uh All proper . After which are you guys sure by any compliance requirements like PC I DS S or um you already know GDR ? Uh what’s one other one ? Any of these C simply uh
Court docket: we’re sure by destiny , average complaints . So .
Adam: Okay . Properly , it’s important to transition to fed ramp excessive at any time
Output:
Adam: Okay, nice. After which are you guys sure by any compliance requirements like PCI DSS or GDPR? What’s one other one? Any of these? CJIS?
Court docket: We’re sure by FedRAMP average compliance.
Adam: Okay. Will it’s important to transition to FedRAMP excessive at any time?
Immediate engineering for summarization
Now that the transcript has been created by Amazon Transcribe, diarized, and enhanced with Amazon Bedrock, the transcript might be summarized with Amazon Bedrock and an LLM. A easy model may seem like the next:
Human:
You’re a transcript summarizing bot. You’ll go over the transcript under and supply a abstract of the transcript.
Transcript: ${transcript}Assistant:
Though this may work, it may be improved with extra directions. You need to use XML tags to offer construction and readability to the duty necessities:
Human: You’re a transcript summarizing bot. You’ll go over the transcript under and supply a abstract of the content material inside the <directions> tags.
<transcript> ${transcript} </transcript><directions>
– Go over the dialog that was had within the transcript.
– Create a abstract primarily based on what occurred within the assembly.
– Spotlight particular motion objects that got here up within the assembly, together with follow-up duties for every individual.
</directions>Assistant:
As a result of conferences usually contain motion objects and date/time data, directions are added to explicitly request the LLM to incorporate this data. As a result of the LLM is aware of the speaker names, every individual is assigned particular motion objects for them if any are discovered. To stop hallucinations, an instruction is included that enables the LLM to fail gracefully.
Human: You’re a transcript summarizing bot. You’ll go over the transcript under and supply a abstract of the content material inside the <directions> tags.
<transcript> ${transcript} </transcript>
<directions>
– Go over the dialog that was had within the transcript.
– Create a abstract primarily based on what occurred within the assembly.
– Spotlight particular motion objects that got here up within the assembly, together with follow-up duties for every individual.
– If related, give attention to what particular AWS companies had been talked about throughout the dialog.
– If there’s adequate context, infer the speaker’s position and point out it within the abstract. As an illustration, “Bob, the client/designer/gross sales rep/…”
– Embrace vital date/time, and point out urgency if mandatory (e.g., deadline/ETAs for outcomes and subsequent steps)
</directions>Assistant: Ought to I add anything in my reply?
Human: If there’s not sufficient context to generate a correct abstract, then simply return a string that claims “Assembly not lengthy sufficient to generate a transcript.
Assistant:
Alternatively, we invite you to discover Amazon Transcribe Name Analytics generative call summarization for an out-of-the-box resolution that integrates straight with Amazon Transcribe.
Immediate engineering for assembly invitation parsing
Included on this demo is a React-based UI that can begin the method of the SMA becoming a member of the assembly. As a result of this demo helps a number of assembly varieties, the invitation have to be parsed. Moderately than parse this with a posh common expression (regex), it is going to be processed with an LLM. This immediate will first determine the assembly kind: Amazon Chime, Zoom, Google Meet, Microsoft Groups, or Cisco Webex. Based mostly on the assembly kind, the LLM will extract the assembly ID and dial-in data. Merely copy/paste the assembly invitation to the UI, and the invitation shall be processed by the LLM to find out tips on how to name the assembly supplier. This may be finished for a gathering that’s presently taking place or scheduled for a future assembly. See the next instance:
Human: You might be an data extracting bot. Go over the assembly invitation under and decide what the assembly id and assembly kind are <directions></directions> xml tags
<meeting_invitation>
${meetingInvitation}
</meeting_invitation><directions>
1. Determine Assembly Sort:
Decide if the assembly invitation is for Chime, Zoom, Google, Microsoft Groups, or Webex conferences.2. Chime, Zoom, and Webex
– Discover the meetingID
– Take away all areas from the assembly ID (e.g., #### ## #### -> ##########).3. If Google – Directions Extract Assembly ID and Dial in
– For Google solely, the assembly invitation will name a meetingID a ‘pin’, so deal with it as a meetingID
– Take away all areas from the assembly ID (e.g., #### ## #### -> ##########).
– Extract Google and Microsoft Dial-In Quantity (if relevant):
– If the assembly is a Google assembly, extract the distinctive dial-in quantity.
– Find the dial-in quantity following the textual content “to affix by telephone dial.”
– Format the extracted Google dial-in quantity as (+1 ###-###-####), eradicating dashes and areas. For instance +1 111-111-1111 would turn into +11111111111)4. If Microsoft Groups – Directions if assembly kind is Microsoft Groups.
– Take note of these directions fastidiously
– The meetingId we wish to retailer within the generated response is the ‘Telephone Convention ID’ : ### ### ###
– within the assembly invitation, there are two IDs a ‘Assembly ID’ (### ### ### ##) and a ‘Telephone Convention ID’ (### ### ###), ignore the ‘Assembly ID’ use the ‘Telephone Convention ID’
– The meetingId we wish to retailer within the generated response is the ‘Telephone Convention ID’ : ### ### ###
– The meetingID that we would like is referenced because the ‘Telephone Convention ID’ retailer that one because the assembly ID.
– Discover the telephone quantity, extract it and retailer it because the dialIn quantity (format (+1 ###-###-####), eradicating dashes and areas. For instance +1 111-111-1111 would turn into +11111111111)5. meetingType guidelines
– The one legitimate responses for meetingType are ‘Chime’, ‘Webex’, ‘Zoom’, ‘Google’, ‘Groups’6. Generate Response:
– Create a response object with the next format:
{
meetingId: “assembly id goes right here with areas eliminated”,
meetingType: “assembly kind goes right here (choices: ‘Chime’, ‘Webex’, ‘Zoom’, ‘Google’, ‘Groups’)”,
dialIn: “Insert Google/Microsoft Groups Dial-In quantity with no dashes or areas, or N/A if not a Google/Microsoft Groups Assembly”
}Assembly ID Codecs:
Zoom: ### #### ####
Webex: #### ### ####
Chime: #### ## ####
Google: ### ### ####
Groups: ### ### ###Be certain that this system doesn’t create faux telephone numbers and solely contains the Microsoft or Google dial-in quantity if the assembly kind is Google or Groups.
</directions>
Assistant: Ought to I add anything in my reply?
Human: Solely return a JSON formatted response with the meetingid and assembly kind related to it. Don’t add every other phrases to your reply. Don’t add any introductory sentences in your reply.
Assistant:
With this data extracted from the invitation, a name is positioned to the assembly supplier in order that the SMA can be a part of the assembly as a participant.
Clear up
When you deployed this pattern resolution, clear up your sources by destroying the AWS CDK software from the AWS Command Line Interface (AWS CLI). This may be finished utilizing the next command:
Conclusion
On this submit, we confirmed tips on how to improve Amazon Transcribe with an LLM utilizing Amazon Bedrock by extracting data that may in any other case be troublesome for a regex to extract. We additionally used this methodology to extract data from a gathering invitation despatched from an unknown supply. Lastly, we confirmed tips on how to use an LLM to offer a summarization of the assembly utilizing detailed directions to provide motion objects and embrace date/time data within the response.
We invite you to deploy this demo into your personal account. We’d love to listen to from you. Tell us what you suppose within the points discussion board of the Amazon Chime SDK Meeting Summarizer GitHub repository. Alternatively, we invite you to discover different strategies for assembly transcription and summarization, reminiscent of Amazon Live Meeting Assistant, which makes use of a browser extension to gather name audio.
In regards to the authors
 Adam Neumiller is a Options Architect for AWS. He’s centered on serving to public sector prospects drive cloud adoption by means of the usage of infrastructure as code. Outdoors of labor, he enjoys spending time together with his household and exploring the good outside.
Adam Neumiller is a Options Architect for AWS. He’s centered on serving to public sector prospects drive cloud adoption by means of the usage of infrastructure as code. Outdoors of labor, he enjoys spending time together with his household and exploring the good outside.
 Court docket Schuett is a Principal Specialist SA – GenAI centered on third celebration fashions and the way they can be utilized to assist remedy buyer issues. When he’s not coding, he spends his time exploring parks, touring together with his household, and listening to music.
Court docket Schuett is a Principal Specialist SA – GenAI centered on third celebration fashions and the way they can be utilized to assist remedy buyer issues. When he’s not coding, he spends his time exploring parks, touring together with his household, and listening to music.
 Christopher Lott is a Principal Options Architect within the AWS AI Language Providers crew. He has 20 years of enterprise software program improvement expertise. Chris lives in Sacramento, California, and enjoys gardening, cooking, aerospace/basic aviation, and touring the world.
Christopher Lott is a Principal Options Architect within the AWS AI Language Providers crew. He has 20 years of enterprise software program improvement expertise. Chris lives in Sacramento, California, and enjoys gardening, cooking, aerospace/basic aviation, and touring the world.
 Dangle Su is a Senior Utilized Scientist at AWS AI. He has been main AWS Transcribe Contact Lens Science crew. His curiosity lies in call-center analytics, LLM-based abstractive summarization, and basic conversational AI.
Dangle Su is a Senior Utilized Scientist at AWS AI. He has been main AWS Transcribe Contact Lens Science crew. His curiosity lies in call-center analytics, LLM-based abstractive summarization, and basic conversational AI.
 Jason Cai is an Utilized Scientist at AWS AI. He has made contributions to AWS Bedrock, Contact Lens, Lex and Transcribe. His pursuits embrace LLM brokers, dialogue summarization, LLM prediction refinement, and information graph.
Jason Cai is an Utilized Scientist at AWS AI. He has made contributions to AWS Bedrock, Contact Lens, Lex and Transcribe. His pursuits embrace LLM brokers, dialogue summarization, LLM prediction refinement, and information graph.
 Edgar Costa Filho is a Senior Cloud Infrastructure Architect with a give attention to Foundations and Containers, together with experience in integrating Amazon EKS with open-source tooling like Crossplane, Terraform, and GitOps. In his position, Edgar is devoted to helping prospects in reaching their enterprise goals by implementing finest practices in cloud infrastructure design and administration.
Edgar Costa Filho is a Senior Cloud Infrastructure Architect with a give attention to Foundations and Containers, together with experience in integrating Amazon EKS with open-source tooling like Crossplane, Terraform, and GitOps. In his position, Edgar is devoted to helping prospects in reaching their enterprise goals by implementing finest practices in cloud infrastructure design and administration.





