Producing trend product descriptions by fine-tuning a vision-language mannequin with SageMaker and Amazon Bedrock
On this planet of on-line retail, creating high-quality product descriptions for hundreds of thousands of merchandise is an important, however time-consuming process. Utilizing machine studying (ML) and pure language processing (NLP) to automate product description era has the potential to save lots of guide effort and rework the best way ecommerce platforms function. One of many foremost benefits of high-quality product descriptions is the advance in searchability. Clients can extra simply find merchandise which have right descriptions, as a result of it permits the search engine to determine merchandise that match not simply the final class but additionally the particular attributes talked about within the product description. For instance, a product that has an outline that features phrases comparable to “lengthy sleeve” and “cotton neck” might be returned if a client is on the lookout for a “lengthy sleeve cotton shirt.” Moreover, having factoid product descriptions can improve buyer satisfaction by enabling a extra customized shopping for expertise and enhancing the algorithms for recommending extra related merchandise to customers, which increase the chance that customers will make a purchase order.
With the development of Generative AI, we will use vision-language models (VLMs) to foretell product attributes straight from photos. Pre-trained picture captioning or visible query answering (VQA) fashions carry out nicely on describing every-day photos however can’t to seize the domain-specific nuances of ecommerce merchandise wanted to realize passable efficiency in all product classes. To resolve this downside, this publish reveals you tips on how to predict domain-specific product attributes from product photos by fine-tuning a VLM on a trend dataset utilizing Amazon SageMaker, after which utilizing Amazon Bedrock to generate product descriptions utilizing the anticipated attributes as enter. So you’ll be able to observe alongside, we’re sharing the code in a GitHub repository.
Amazon Bedrock is a completely managed service that provides a selection of high-performing basis fashions (FMs) from main AI corporations like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, together with a broad set of capabilities you must construct generative AI purposes with safety, privateness, and accountable AI.
You should use a managed service, comparable to Amazon Rekognition, to foretell product attributes as defined in Automating product description generation with Amazon Bedrock. Nevertheless, in the event you’re attempting to extract specifics and detailed traits of your product or your area (trade), fine-tuning a VLM on Amazon SageMaker is important.
Imaginative and prescient-language fashions
Since 2021, there was an increase in curiosity in vision-language fashions (VLMs), which led to the discharge of options comparable to Contrastive Language-Image Pre-training (CLIP) and Bootstrapping Language-Image Pre-training (BLIP). With regards to duties comparable to picture captioning, text-guided picture era, and visible question-answering, VLMs have demonstrated state-of-the artwork efficiency.
On this publish, we use BLIP-2, which was launched in BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models, as our VLM. BLIP-2 consists of three fashions: a CLIP-like picture encoder, a Querying Transformer (Q-Former) and a big language mannequin (LLM). We use a version of BLIP-2, that contains Flan-T5-XL because the LLM.
The next diagram illustrates the overview of BLIP-2:

Determine 1: BLIP-2 overview
The pre-trained model of the BLIP-2 mannequin has been demonstrated in Build an image-to-text generative AI application using multimodality models on Amazon SageMaker and Build a generative AI-based content moderation solution on Amazon SageMaker JumpStart. On this publish, we reveal tips on how to fine-tune BLIP-2 for a domain-specific use case.
Resolution overview
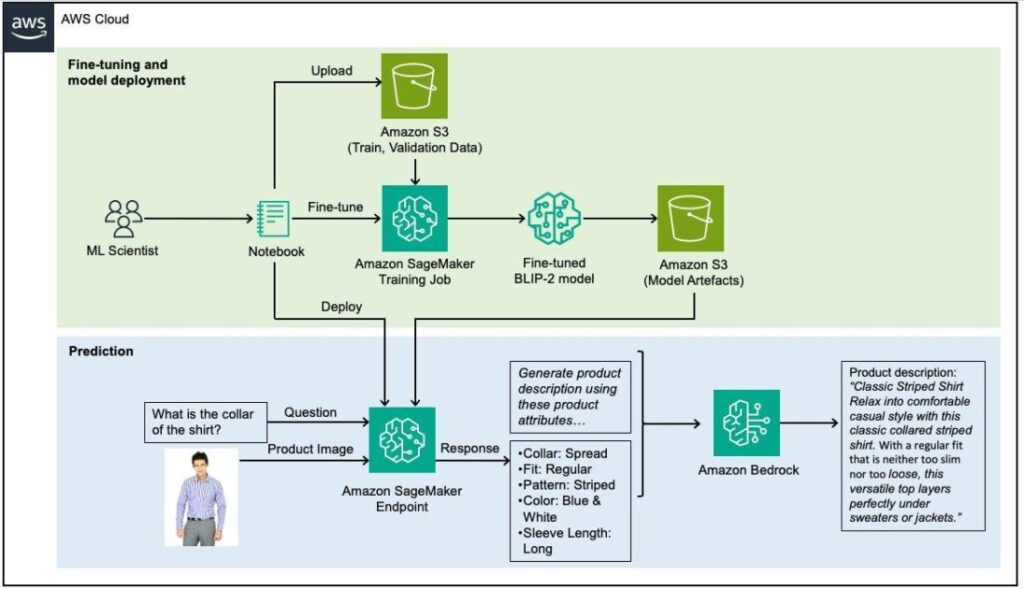
The next diagram illustrates the answer structure.

Determine 2: Excessive-level answer structure
The high-level overview of the answer is:
- An ML scientist makes use of Sagemaker notebooks to course of and break up the information into coaching and validation information.
- The datasets are uploaded to Amazon Simple Storage Service (Amazon S3) utilizing the S3 shopper (a wrapper round an HTTP name).
- Then the Sagemaker shopper is used to launch a Sagemaker Coaching job, once more a wrapper for an HTTP name.
- The coaching job manages the copying of the datasets from S3 to the coaching container, the coaching of the mannequin, and the saving of its artifacts to S3.
- Then, via one other name of the Sagemaker shopper, an endpoint is generated, copying the mannequin artifacts into the endpoint internet hosting container.
- The inference workflow is then invoked via an AWS Lambda request, which first makes an HTTP request to the Sagemaker endpoint, after which makes use of that to make one other request to Amazon Bedrock.
Within the following sections, we reveal tips on how to:
- Arrange the event atmosphere
- Load and put together the dataset
- Wonderful-tune the BLIP-2 mannequin to be taught product attributes utilizing SageMaker
- Deploy the fine-tuned BLIP-2 mannequin and predict product attributes utilizing SageMaker
- Generate product descriptions from predicted product attributes utilizing Amazon Bedrock
Arrange the event atmosphere
An AWS account is required with an AWS Identity and Access Management (IAM) role that has permissions to handle sources created as a part of the answer. For particulars, see Creating an AWS account.
We use Amazon SageMaker Studio with the ml.t3.medium occasion and the Information Science 3.0 picture. Nevertheless, you may also use an Amazon SageMaker notebook instance or any built-in improvement atmosphere (IDE) of your selection.
Be aware: Make sure to arrange your AWS Command Line Interface (AWS CLI) credentials appropriately. For extra data, see Configure the AWS CLI.
An ml.g5.2xlarge occasion is used for SageMaker Coaching jobs, and an ml.g5.2xlarge occasion is used for SageMaker endpoints. Guarantee adequate capability for this occasion in your AWS account by requesting a quota increase if required. Additionally examine the pricing of the on-demand cases.
You’ll want to clone this GitHub repository for replicating the answer demonstrated on this publish. First, launch the pocket book foremost.ipynb in SageMaker Studio by choosing the Picture as Information Science and Kernel as Python 3. Set up all of the required libraries talked about within the necessities.txt.
Load and put together the dataset
For this publish, we use the Kaggle Fashion Images Dataset, which comprise 44,000 merchandise with a number of class labels, descriptions, and excessive decision photos. On this publish we need to reveal tips on how to fine-tune a mannequin to be taught attributes comparable to material, match, collar, sample, and sleeve size of a shirt utilizing the picture and a query as inputs.
Every product is recognized by an ID comparable to 38642, and there’s a map to all of the merchandise in kinds.csv. From right here, we will fetch the picture for this product from photos/38642.jpg and the entire metadata from kinds/38642.json. To fine-tune our mannequin, we have to convert our structured examples into a group of query and reply pairs. Our ultimate dataset has the next format after processing for every attribute:
Id | Query | Reply38642 | What's the material of the clothes on this image? | Material: Cotton
Wonderful-tune the BLIP-2 mannequin to be taught product attributes utilizing SageMaker
To launch a SageMaker Coaching job, we’d like the HuggingFace Estimator. SageMaker begins and manages the entire mandatory Amazon Elastic Compute Cloud (Amazon EC2) cases for us, provides the suitable Hugging Face container, uploads the required scripts, and downloads information from our S3 bucket to the container to /choose/ml/enter/information.
We fine-tune BLIP-2 utilizing the Low-Rank Adaptation (LoRA) approach, which provides trainable rank decomposition matrices to each Transformer construction layer whereas preserving the pre-trained mannequin weights in a static state. This method can improve coaching throughput and cut back the quantity of GPU RAM required by 3 occasions and the variety of trainable parameters by 10,000 occasions. Regardless of utilizing fewer trainable parameters, LoRA has been demonstrated to carry out in addition to or higher than the complete fine-tuning approach.
We ready entrypoint_vqa_finetuning.py which implements fine-tuning of BLIP-2 with the LoRA approach utilizing Hugging Face Transformers, Accelerate, and Parameter-Efficient Fine-Tuning (PEFT). The script additionally merges the LoRA weights into the mannequin weights after coaching. Because of this, you’ll be able to deploy the mannequin as a standard mannequin with none further code.
We are able to begin our coaching job by working with the .match() technique and passing our Amazon S3 path for photos and our enter file.
Deploy the fine-tuned BLIP-2 mannequin and predict product attributes utilizing SageMaker
We deploy the fine-tuned BLIP-2 mannequin to the SageMaker actual time endpoint utilizing the HuggingFace Inference Container. It’s also possible to use the large model inference (LMI) container, which is described in additional element in Build a generative AI-based content moderation solution on Amazon SageMaker JumpStart, which deploys a pre-trained BLIP-2 mannequin. Right here, we reference our fine-tuned mannequin in Amazon S3 as an alternative of the pre-trained mannequin out there within the Hugging Face hub. We first create the mannequin and deploy the endpoint.
When the endpoint standing turns into in service, we will invoke the endpoint for the instructed vision-to-language era process with an enter picture and a query as a immediate:
The output response appears to be like like the next:
{"Sleeve Size": "Lengthy Sleeves"}
Generate product descriptions from predicted product attributes utilizing Amazon Bedrock
To get began with Amazon Bedrock, request entry to the foundational fashions (they don’t seem to be enabled by default). You possibly can observe the steps within the documentation to allow mannequin entry. On this publish, we use Anthropic’s Claude in Amazon Bedrock to generate product descriptions. Particularly, we use the mannequin anthropic.claude-3-sonnet-20240229-v1 as a result of it gives good efficiency and velocity.
After creating the boto3 shopper for Amazon Bedrock, we create a immediate string that specifies that we need to generate product descriptions utilizing the product attributes.
You're an professional in writing product descriptions for shirts. Use the information under to create product description for a web site. The product description ought to comprise all given attributes.Present some inspirational sentences, for instance, how the material strikes. Take into consideration what a possible buyer needs to know in regards to the shirts. Listed here are the information you must create the product descriptions: [Here we insert the predicted attributes by the BLIP-2 model]
The immediate and mannequin parameters, together with most variety of tokens used within the response and the temperature, are handed to the physique. The JSON response should be parsed earlier than the ensuing textual content is printed within the ultimate line.
The generated product description response appears to be like like the next:
"Traditional Striped Shirt Loosen up into snug informal type with this basic collared striped shirt. With a daily match that's neither too slim nor too free, this versatile prime layers completely underneath sweaters or jackets."
Conclusion
We’ve proven you ways the mixture of VLMs on SageMaker and LLMs on Amazon Bedrock current a robust answer for automating trend product description era. By fine-tuning the BLIP-2 mannequin on a trend dataset utilizing Amazon SageMaker, you’ll be able to predict domain-specific and nuanced product attributes straight from photos. Then, utilizing the capabilities of Amazon Bedrock, you’ll be able to generate product descriptions from the anticipated product attributes, enhancing the searchability and personalization of ecommerce platforms. As we proceed to discover the potential of generative AI, LLMs and VLMs emerge as a promising avenue for revolutionizing content material era within the ever-evolving panorama of on-line retail. As a subsequent step, you’ll be able to attempt fine-tuning this mannequin by yourself dataset utilizing the code offered within the GitHub repository to check and benchmark the outcomes to your use circumstances.
In regards to the Authors
 Antonia Wiebeler is a Information Scientist on the AWS Generative AI Innovation Middle, the place she enjoys constructing proofs of idea for patrons. Her ardour is exploring how generative AI can remedy real-world issues and create worth for patrons. Whereas she shouldn’t be coding, she enjoys working and competing in triathlons.
Antonia Wiebeler is a Information Scientist on the AWS Generative AI Innovation Middle, the place she enjoys constructing proofs of idea for patrons. Her ardour is exploring how generative AI can remedy real-world issues and create worth for patrons. Whereas she shouldn’t be coding, she enjoys working and competing in triathlons.
 Daniel Zagyva is a Information Scientist at AWS Skilled Companies. He focuses on growing scalable, production-grade machine studying options for AWS prospects. His expertise extends throughout completely different areas, together with pure language processing, generative AI, and machine studying operations.
Daniel Zagyva is a Information Scientist at AWS Skilled Companies. He focuses on growing scalable, production-grade machine studying options for AWS prospects. His expertise extends throughout completely different areas, together with pure language processing, generative AI, and machine studying operations.
 Lun Yeh is a Machine Studying Engineer at AWS Skilled Companies. She focuses on NLP, forecasting, MLOps, and generative AI and helps prospects undertake machine studying of their companies. She graduated from TU Delft with a level in Information Science & Expertise.
Lun Yeh is a Machine Studying Engineer at AWS Skilled Companies. She focuses on NLP, forecasting, MLOps, and generative AI and helps prospects undertake machine studying of their companies. She graduated from TU Delft with a level in Information Science & Expertise.
 Fotinos Kyriakides is an AI/ML Advisor at AWS Skilled Companies specializing in growing production-ready ML options and platforms for AWS prospects. In his free time Fotinos enjoys working and exploring.
Fotinos Kyriakides is an AI/ML Advisor at AWS Skilled Companies specializing in growing production-ready ML options and platforms for AWS prospects. In his free time Fotinos enjoys working and exploring.





