RAG structure with Voyage AI embedding fashions on Amazon SageMaker JumpStart and Anthropic Claude 3 fashions
This submit is a visitor submit co-written with Tengyu Ma and Wen Phan from Voyage AI.
Organizations at this time have entry to huge quantities of information, a lot of it proprietary, which holds the potential to unlock worthwhile insights when used successfully in generative synthetic intelligence (AI) functions. Retrieval Augmented Technology (RAG) is a strong approach designed to faucet into this reservoir of data. By dynamically pulling related knowledge from these intensive databases through the response era course of, RAG allows AI fashions to provide extra correct, related, and contextually wealthy outputs.
Embedding fashions are essential elements within the RAG structure, serving as the muse for successfully figuring out and retrieving essentially the most related data from a big dataset. These fashions convert massive volumes of textual content into compact, numerical representations, permitting the system to shortly sift by and match query-related knowledge with unprecedented precision. By facilitating a extra environment friendly and correct retrieval course of, embedding fashions ensure that the generative element of RAG is fed with essentially the most pertinent data.
On this submit, we offer an summary of the state-of-the-art embedding fashions by Voyage AI and present a RAG implementation with Voyage AI’s textual content embedding mannequin on Amazon SageMaker Jumpstart, Anthropic’s Claude 3 mannequin on Amazon Bedrock, and Amazon OpenSearch Service. Voyage AI’s embedding fashions are the popular embedding fashions for Anthropic. Along with general-purpose embedding fashions, Voyage AI gives domain-specific embedding fashions which can be tuned to a specific area.
RAG structure and embedding fashions
RAG is the predominant design sample for enterprise chatbots the place a retrieval system fetches validated sources and paperwork which can be pertinent to the question and inputs them to a big language mannequin (LLM) to generate a response. It combines the generative capabilities of fashions with the informational breadth present in huge databases, enabling the mannequin to drag related exterior paperwork to boost its responses. This leads to outputs that aren’t solely contextually wealthy but in addition factually correct, considerably boosting the reliability and utility of LLMs throughout various functions.
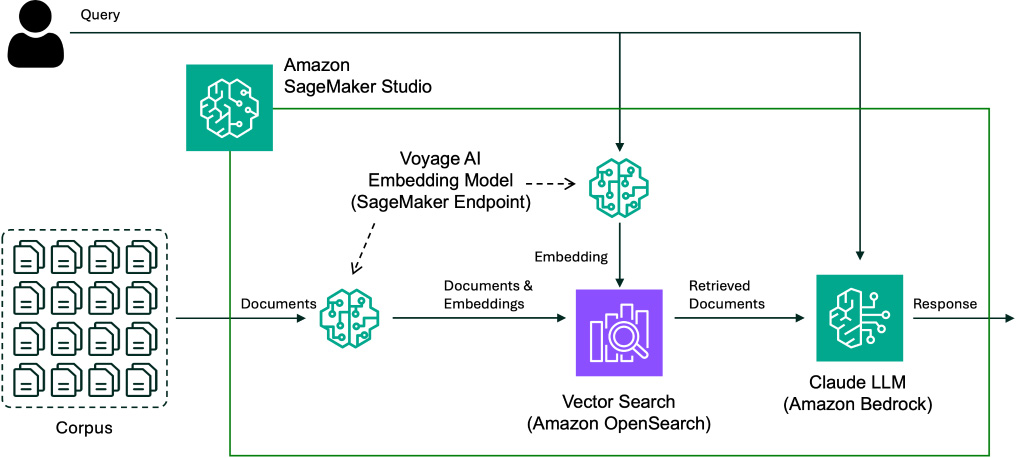
Let’s briefly evaluate RAG utilizing the next determine.

RAG methods are empowered by semantic search utilizing dense-vector representations of the paperwork known as embeddings. These vectors are saved in a vector retailer, the place they are often effectively retrieved later. At question time, a question can be transformed right into a vector after which used to seek out and retrieve related paperwork saved within the vector retailer through a k-nearest neighbor (k-NN) search in opposition to the doc vector representations. Lastly, the retrieved paperwork together with the question are used to immediate the generative mannequin, usually leading to higher-quality responses and fewer hallucinations.
Embedding fashions are neural community fashions that rework queries and paperwork into embeddings. The retrieval high quality is solely determined by how the info is represented as vectors, and the effectiveness of embedding fashions is evaluated based mostly on their accuracy in retrieving related data. Due to this fact, the retrieval high quality of the embedding fashions is very correlated with the standard of the RAG system responses—to make your RAG extra profitable, it is best to contemplate bettering your embeddings. Take a look at this blog for an in depth rationalization.
Voyage AI’s general-purpose and domain-specific embedding fashions
Voyage AI develops cutting-edge embedding models with state-of-the-art retrieval accuracy. voyage-large-2 is Voyage’s strongest generalist embedding mannequin, outperforming widespread competing fashions. Voyage additionally gives voyage-2, a base generalist embedding mannequin optimized for latency and high quality. The next desk summarizes the Voyage embedding fashions at the moment obtainable on SageMaker JumpStart.
| Voyage AI Mannequin | SageMaker JumpStart Mannequin ID | Description |
voyage-2 |
voyage-2-embedding |
Common-purpose embedding mannequin optimized for a steadiness between value, latency, and retrieval high quality |
voyage-large-2 |
voyage-large-2-embedding |
Common-purpose embedding mannequin optimized for retrieval high quality |
voyage-code-2 |
voyage-code-2-embedding |
Area-specific embedding mannequin optimized for code retrieval (17% higher than options) |
Along with general-purpose embedding fashions, Voyage AI gives domain-specific ones which can be tuned to a specific area. These domain-specific embedding fashions are skilled on large domain-specific datasets, permitting them to deeply perceive and excel in that area. For instance, Voyage’s code embedding mannequin (voyage-code-2) outperforms general-purpose embedding fashions on code-related knowledge paperwork, attaining a few 15% enchancment over the following greatest mannequin. This efficiency hole over the following greatest general-purpose embedding improves much more for datasets requiring deeper code understanding. See voyage-code-2: Elevate Your Code Retrieval for voyage-code-2 particulars. Extra lately, Voyage launched a authorized embedding mannequin (voyage-law-2) that’s optimized for authorized retrieval and tops the MTEB leaderboard for legal retrieval. See Domain-Specific Embeddings and Retrieval: Legal Edition (voyage-law-2) for voyage-law-2 particulars. Voyage AI plans to proceed releasing extra domain-specific embedding fashions within the close to future, together with finance, healthcare, and multi-language. For an inventory of all obtainable Voyage AI embedding fashions, see Embeddings.
Voyage AI gives API endpoints for embedding fashions, making it seamless to combine with different elements of your RAG stack. The Voyage AI embedding fashions can be found on AWS Marketplace and deployable as Amazon SageMaker endpoints inside your account and VPC, eliminating safety and compliance considerations. As a part of SageMaker JumpStart, you’ll be able to deploy Voyage AI embedding fashions with a number of clicks and begin working your RAG stack on AWS.
Resolution overview
On this RAG answer, we use Voyage AI embedding fashions deployed with SageMaker JumpStart to exhibit an instance utilizing the Apple 2022 annual report (SEC Type 10-Ok) because the corpus to retrieve from. Particularly, we deploy the SageMaker mannequin bundle of the voyage-large-2 mannequin. For the LLM, we use the Anthropic Claude 3 Sonnet mannequin on Amazon Bedrock. We use OpenSearch Service because the vector retailer. You may also comply with together with the notebook. The next diagram illustrates the answer structure.

SageMaker JumpStart is the machine studying (ML) hub of SageMaker that gives one-click entry to over 350 open supply and third-party fashions. These fashions may be found and deployed by the Amazon SageMaker Studio UI or utilizing the SageMaker Python SDK. SageMaker JumpStart gives notebooks to customise and deploy basis fashions into your VPC.

Anthropic’s Claude 3 fashions are the following era of state-of-the-art fashions from Anthropic. For the overwhelming majority of workloads, Sonnet is quicker on inputs and outputs than Anthropic’s Claude 2 and a pair of.1 fashions, with larger ranges of intelligence. Amazon Bedrock is a totally managed service that gives a alternative of high-performing basis fashions (FMs) from main AI corporations like Anthropic by an API, making it simple to construct generative AI functions. To comply with alongside, you should definitely request model access to Anthropic Claude 3 Sonnet on Amazon Bedrock.
Amazon OpenSearch Service is a managed service that makes it simple to deploy, function, and scale OpenSearch, a well-liked open supply, distributed search analytics suite derived from Elasticsearch. OpenSearch gives the flexibility to do vector search through the k-NN search.
Stipulations
To comply with alongside, it’s essential to create an OpenSearch Service domain. For the needs of this walkthrough, the Simple create possibility is ok. Preserve the Allow fine-grained entry management possibility chosen. Choose Create grasp person and supply a person identify and password. After the area has been created, the area particulars may have the area endpoint, which you’ll want—together with the person identify and password—to entry your OpenSearch occasion. You don’t want to fret about creating an index or inserting knowledge. We use the OpenSearch Python client to work with our vector retailer within the walkthrough.
Deploy Embedding mannequin endpoint
To make use of voyage-large-2, it’s essential to subscribe to the SageMaker mannequin bundle in AWS Market. For directions, see Subscribe to the model package. Selecting the mannequin card within the SageMaker JumpStart UI may even convey you to the mannequin itemizing web page on AWS Market.
After you’re subscribed, you’ll be able to initialize and deploy the embedding mannequin as a SageMaker endpoint as follows:
# Set embedding endpoint configuration
(embedding_model_id, embedding_model_version, embedding_instance_type) = (
"voyage-large-2-embedding",
"*",
"ml.g5.xlarge", # See AWS Market mannequin bundle for supported occasion varieties
)
# Instantiate embedding mannequin from JumpStart
from sagemaker.jumpstart.mannequin import JumpStartModel
embedding_model = JumpStartModel(
model_id=embedding_model_id,
model_version=embedding_model_version,
instance_type=embedding_instance_type,
)
# Deploy mannequin as inference endpoint. This will take a number of minutes to deploy (5 to 10 minutes)
embedding_endpoint = embedding_model.deploy()Vectorize Paperwork
With the embedding endpoint deployed, you’ll be able to index your paperwork for retrieval.
Remodel and chunk paperwork
You want an inventory of strings to invoke the deployed voyage-large-2 mannequin. For a lot of paperwork, like our instance annual report, every string is a semantically significant chunk of textual content. There are a number of methods you’ll be able to load and chunk paperwork for vectorization. The code on this part is only one instance; be at liberty to make use of what fits your knowledge supply and information.
On this walkthrough, we load and chunk the supply PDF file with the LangChain PyPDFLoader (which makes use of pypdf) and recursive character text splitter:
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = PyPDFLoader("apple-10k-2022.pdf")
document_chunks = loader.load_and_split(
RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
)In apply, choosing the textual content splitting chunk dimension and overlap requires some experimentation. The are many strategies for appropriately chunking paperwork for high-quality retrieval, however that’s past the scope of this submit.
Generate doc embeddings
Now you can vectorize your paperwork—or extra exactly, your doc chunks. See the next code:
# Set batch dimension
BATCH_SIZE = 45
In [ ]:
# Vectorize chunks in batches
index_list = []
for i in vary(0, len(chunk_list), BATCH_SIZE):
docs_playload = {
"enter": chunk_list[i:i + BATCH_SIZE],
"input_type": "doc",
"truncation": "true",
}
embed_docs_response = embedding_endpoint.predict(json.dumps(docs_playload))
doc_embeddings_list = [d["embedding"] for d in embed_docs_response["data"]]
index_list += [
{"document": document, "embedding": embedding}
for document, embedding in zip(chunk_list[i:i + BATCH_SIZE], doc_embeddings_list)
]Create a vector retailer index
The following step is to populate your OpenSearch vector search index with the doc embeddings utilizing the OpenSearch Python consumer:
# Populate index with doc, embedding, and ID
for id, i in zip(vary(0, len(index_list)), index_list):
index_response = opensearch_client.index(
index=INDEX_NAME_OPENSEARCH,
physique={
"doc": i["document"],
"embedding": i["embedding"],
},
id=id,
refresh=True,
)Retrieve related paperwork
Together with your listed vector retailer, now you can use embeddings to seek out related paperwork to your question:
# Set variety of paperwork to retrieve
TOP_K = 3
In [ ]:
# Set vector search payload
vector_search_payload = {
"dimension": TOP_K,
"question": {"knn": {"embedding": {"vector": query_embedding, "ok": TOP_K}}},
}
In [ ]:
vector_search_response = opensearch_client.search(
index=INDEX_NAME_OPENSEARCH,
physique=vector_search_payload,
)
The next is a formatted semantic search results of the highest three most-relevant doc chunks, indicating the index ID, similarity rating, and the primary a number of characters of the chunk:
ID: 4
Rating: 0.7956404
Doc: below Part 404(b) of the Sarbanes-Oxley Act (15 U.S.C. 7262(b)) by the registered public accounting agency that ready or issued its audit report. ☒
Point out by verify mark whether or not the Registrant is a shell firm (as outlined in Rule 12b-2 of the Act).
Sure ☐ No ☒
The combination market worth of the voting and non-voting inventory held by non-affiliates of the Registrant, as of March 25, 2022, the final enterprise day of the Registrant’s most lately accomplished second fiscal quarter, was roughly $2,830,067,000,000. Solely for functions of this disclosure, shares of frequent inventory held by govt officers and administrators of the Registrant as of such date have been excluded as a result of such individuals could also be deemed to be associates. This dedication of govt officers and administrators as associates will not be essentially a conclusive dedication for every other functions. 15,908,118,000 shares of frequent inventory have been issued and excellent as of October 14, 2022.
ID: 5
Rating: 0.7367379
Doc: 15,908,118,000 shares of frequent inventory have been issued and excellent as of October 14, 2022.
DOCUMENTS INCORPORATED BY REFERENCE
Parts of the Registrant’s definitive proxy assertion regarding its 2023 annual assembly of shareholders are integrated by reference into Half III of this Annual Report on Type 10-Ok the place indicated. The Registrant’s definitive proxy assertion will probably be filed with the U.S. Securities and Alternate Fee inside 120 days after the top of the fiscal 12 months to which this report relates.
ID: 178
Rating: 0.7263324
Doc: Observe 3 – Monetary Devices
Money, Money Equivalents and Marketable Securities
The next tables present the Firm’ s money, money equivalents and marketable securities by important funding class as of September 24, 2022 and September 25, 2021 (in thousands and thousands):
2022
Adjusted Value
Unrealized Features
Unrealized Losses
Honest Worth
Money and Money Equivalents
Present Marketable Securities
Non-Present Marketable Securities
Money $ 18,546 $ — $ — $ 18,546 $ 18,546 $ — $ —
Stage 1 :
Cash market funds 2,929 — — 2,929 2,929 — —
Mutual funds 274 — (47) 227 — 227 —
Subtotal 3,203 — (47) 3,156 2,929 227 —
Stage 2 :
U.S. Treasury securities 25,134 — (1,725) 23,409 338 5,091 17,980
U.S. company securities 5,823 — (655) 5,168 — 240 4,928
Non-U.S. authorities securities 16,948 2 (1,201) 15,749 — 8,806 6,943 Certificates of deposit and time deposits 2,067 — — 2,067 1,805 262 —
Industrial paper 718 — — 718 28 690 —
Company debt securities 87,148 9 (7,707) 79,450 — 9,023 70,427
The highest retrieved doc chunk (ID 4 with a rating of 0.7956404) accommodates a press release that gives a direct reply to our question:
The combination market worth of the voting and non-voting inventory held by non-affiliates of the Registrant, as of March 25, 2022, the final enterprise day of the Registrant’s most lately accomplished second fiscal quarter, was roughly $2,830,067,000,000.
This extra context will allow Claude to supply a response that solutions your question.
Generate a retrieval augmented response
Now you can immediate Claude to make use of the retrieved paperwork to reply your question:
# Create retrieval-augmented immediate
rag_prompt = f"""Human:
INSTRUCTIONS:
Reply the QUERY utilizing the CONTEXT textual content supplied beneath. Preserve your reply
grounded within the details of the CONTEXT. If the CONTEXT doesn’t comprise the
details to reply the QUERY simply reply with "I shouldn't have sufficient context
to answer this question.".
QUERY: {question}
CONTEXT: {context}
Assistant:
"""
Subsequent initialize the Amazon Bedrock consumer to invoke Anthropic’s Claude3 Sonnet mannequin in us-east-1.
# Record obtainable LLMs on Amazon Bedrock
bedrock_client = boto3.consumer('bedrock', region_name="us-east-1")
bedrock_fm = bedrock_client.list_foundation_models()
print([(m["modelId"], m["modelName"]) for m in bedrock_fm["modelSummaries"]])
In [ ]:
# Set Bedrock LLM mannequin ID
LLM_MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0"
In [ ]:
bedrock_runtime_client = boto3.consumer('bedrock-runtime', region_name="us-east-1")
In [ ]:
# Invoke LLM inference
attempt:
llm_rag_response = bedrock_runtime_client.invoke_model(
modelId=LLM_MODEL_ID,
physique=json.dumps(rag_payload),
settle for="software/json",
contentType="software/json",
)
besides botocore.exceptions.ClientError as error:
print("Shopper error")
increase error
Claude produces an accurate response that solutions the question utilizing the context supplied:
In keeping with the context supplied, "The combination market worth of the voting and non-voting inventory held by non-affiliates of the Registrant, as of March 25, 2022, the final enterprise day of the Registrant's most lately accomplished second fiscal quarter, was roughly $2,830,067,000,000."
Generate a response with out retrieved paperwork
For comparability, let’s see how Claude will reply to a question straight—with none extra context. Particularly, we ask “What’s the combination market worth of the voting and non-voting inventory held by non-affiliates of the Registrant, as of March 25, 2022?”
The next is Claude’s response:
Sadly, with out entry to the precise monetary filings or experiences for the corporate you're asking about, I shouldn't have sufficient data to find out the mixture market worth of the voting and non-voting inventory held by non-affiliates as of March 25, 2022.
Public corporations are required to reveal this data of their annual experiences and different SEC filings, however I shouldn't have entry to these paperwork for the actual firm or "Registrant" you're referring to. The combination market worth calculation takes under consideration issues just like the variety of excellent shares, current inventory costs, and which shareholders are thought of associates versus non-affiliates.
Except you'll be able to present the corporate's identify and the precise report containing this knowledge level, I can't lookup or calculate that combination market worth determine. My position is to supply useful data to you, however I shouldn't have a approach to entry every public firm's proprietary monetary knowledge straight. Please let me know should you can share extra particulars concerning the firm in query.
Claude signifies it doesn’t have sufficient context, particularly as a result of the question didn’t explicitly point out the registrant (the corporate).
Clear up
Should you’ve been following alongside, don’t overlook to delete the SageMaker endpoint and delete the OpenSearch Service domain if you’re accomplished so that you don’t incur pointless prices:
embedding_endpoint.delete_model()
embedding_endpoint.delete_endpoint()Conclusion
Embeddings are on the coronary heart of a RAG system, and Voyage AI gives the most effective general-purpose and domain-specific embedding fashions at this time. Get began or degree up your present RAG stack on AWS at this time with Voyage AI embedding fashions—it’s seamless with SageMaker JumpStart. You’ll be able to attempt the notebook on this submit your self. Be taught extra about Voyage AI and comply with them on X (Twitter) or LinkedIn for updates!
Concerning the Authors
 Tengyu Ma is CEO and Co-Founding father of Voyage AI and an assistant professor of laptop science at Stanford College. His analysis pursuits broadly embody matters in machine studying, algorithms and their concept, resembling deep studying, (deep) reinforcement studying, pre-training / basis fashions, robustness, non-convex optimization, distributed optimization, and high-dimensional statistics. Tengyu earned his PhD from Princeton College and has labored at Fb and Google as visiting scientists.
Tengyu Ma is CEO and Co-Founding father of Voyage AI and an assistant professor of laptop science at Stanford College. His analysis pursuits broadly embody matters in machine studying, algorithms and their concept, resembling deep studying, (deep) reinforcement studying, pre-training / basis fashions, robustness, non-convex optimization, distributed optimization, and high-dimensional statistics. Tengyu earned his PhD from Princeton College and has labored at Fb and Google as visiting scientists.
 Wen Phan is Head of Product at Voyage AI and has spent the final decade creating and commercializing AI and knowledge merchandise for enterprises. He has labored with a whole bunch of customers and organizations all over the world to use AI and knowledge to their use instances in monetary providers, healthcare, protection, and expertise, to call a number of. Wen holds a B.S. in electrical engineering and M.S. in analytics and determination sciences. Personally, he enjoys spinning hip-hop data, eating out, and spending time along with his spouse and two youngsters — oh, and guzzling cookies and cream milkshakes, too!
Wen Phan is Head of Product at Voyage AI and has spent the final decade creating and commercializing AI and knowledge merchandise for enterprises. He has labored with a whole bunch of customers and organizations all over the world to use AI and knowledge to their use instances in monetary providers, healthcare, protection, and expertise, to call a number of. Wen holds a B.S. in electrical engineering and M.S. in analytics and determination sciences. Personally, he enjoys spinning hip-hop data, eating out, and spending time along with his spouse and two youngsters — oh, and guzzling cookies and cream milkshakes, too!
 Vivek Gangasani is an AI/ML Options Architect working with Generative AI startups on AWS. He helps world main AI startups practice, host and operationalize LLMs to construct progressive Generative AI options. Presently, he’s centered on creating methods for fine-tuning and optimizing the inference efficiency at scale for LLMs. In his free time, Vivek enjoys mountain climbing, watching films and making an attempt completely different cuisines.
Vivek Gangasani is an AI/ML Options Architect working with Generative AI startups on AWS. He helps world main AI startups practice, host and operationalize LLMs to construct progressive Generative AI options. Presently, he’s centered on creating methods for fine-tuning and optimizing the inference efficiency at scale for LLMs. In his free time, Vivek enjoys mountain climbing, watching films and making an attempt completely different cuisines.





