Intel Releases a Low-bit Quantized Open LLM Leaderboard for Evaluating Language Mannequin Efficiency by way of 10 Key Benchmarks
The area of huge language mannequin (LLM) quantization has garnered consideration as a result of its potential to make highly effective AI applied sciences extra accessible, particularly in environments the place computational assets are scarce. By lowering the computational load required to run these fashions, quantization ensures that superior AI might be employed in a wider array of sensible eventualities with out sacrificing efficiency.
Conventional massive fashions require substantial assets, which bars their deployment in much less outfitted settings. Subsequently, creating and refining quantization methods, strategies that compress fashions to require fewer computational assets with no vital loss in accuracy, is essential.
Numerous instruments and benchmarks are employed to judge the effectiveness of various quantization methods on LLMs. These benchmarks span a broad spectrum, together with common data and reasoning duties throughout varied fields. They assess fashions in each zero-shot and few-shot eventualities, analyzing how effectively these quantized fashions carry out underneath several types of cognitive and analytical duties with out intensive fine-tuning or with minimal example-based studying, respectively.
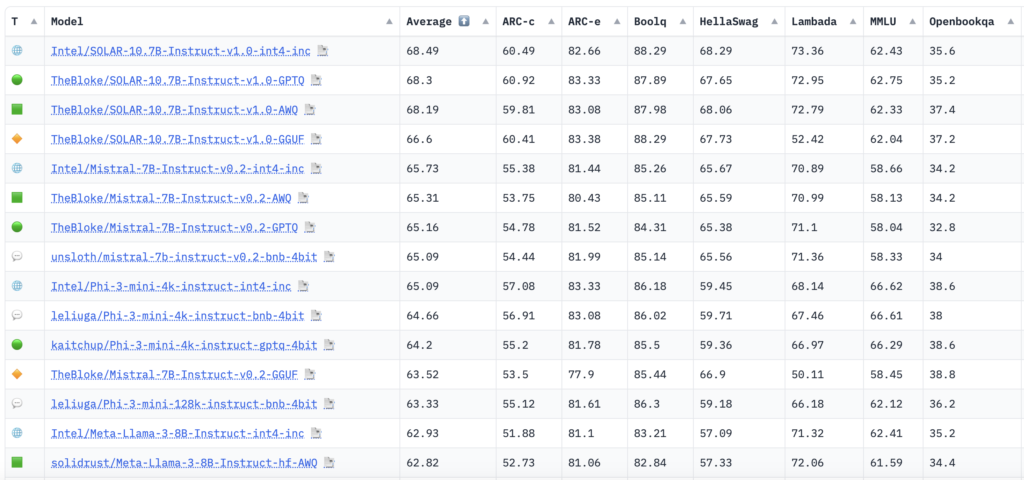
Researchers from Intel launched the Low-bit Quantized Open LLM Leaderboard on Hugging Face. This leaderboard offers a platform for evaluating the efficiency of varied quantized fashions utilizing a constant and rigorous analysis framework. Doing so permits researchers and builders to measure progress within the area extra successfully and pinpoint which quantization strategies yield the most effective stability between effectivity and effectiveness.
The tactic employed entails rigorous testing by way of the Eleuther AI-Language Model Evaluation Harness, which runs fashions by way of a battery of duties designed to check varied features of mannequin efficiency. Duties embody understanding and producing human-like responses based mostly on given prompts, problem-solving in educational topics like arithmetic and science, and discerning truths in complicated query eventualities. The fashions are scored based mostly on accuracy and the constancy of their outputs in comparison with anticipated human responses.
Ten key benchmarks used for evaluating fashions on the Eleuther AI-Language Model Evaluation Harness:
- AI2 Reasoning Challenge (0-shot): This set of grade-school science questions includes a Problem Set of two,590 “arduous” questions that each retrieval and co-occurrence strategies sometimes fail to reply accurately.
- AI2 Reasoning Easy (0-shot): This can be a assortment of simpler grade-school science questions, with an Straightforward Set comprising 5,197 questions.
- HellaSwag (0-shot): Assessments commonsense inference, which is easy for people (roughly 95% accuracy) however proves difficult for state-of-the-art (SOTA) fashions.
- MMLU (0-shot): Evaluates a textual content mannequin’s multitask accuracy throughout 57 various duties, together with elementary arithmetic, US historical past, pc science, regulation, and extra.
- TruthfulQA (0-shot): Measures a mannequin’s tendency to duplicate on-line falsehoods. It’s technically a 6-shot process as a result of every instance begins with six question-answer pairs.
- Winogrande (0-shot): An adversarial commonsense reasoning problem at scale, designed to be troublesome for fashions to navigate.
- PIQA (0-shot): Focuses on bodily commonsense reasoning, evaluating fashions utilizing a particular benchmark dataset.
- Lambada_Openai (0-shot): A dataset assessing computational fashions’ textual content understanding capabilities by way of a phrase prediction process.
- OpenBookQA (0-shot): An issue-answering dataset that mimics open ebook exams to evaluate human-like understanding of varied topics.
- BoolQ (0-shot): An issue-answering process the place every instance consists of a quick passage adopted by a binary sure/no query.
In conclusion, These benchmarks collectively check a variety of reasoning expertise and common data in zero and few-shot settings. The outcomes from the leaderboard present a various vary of efficiency throughout completely different fashions and duties. Fashions optimized for sure kinds of reasoning or particular data areas typically wrestle with different cognitive duties, highlighting the trade-offs inherent in present quantization methods. As an example, whereas some fashions could excel in narrative understanding, they could underperform in data-heavy areas like statistics or logical reasoning. These discrepancies are essential for guiding future mannequin design and coaching strategy enhancements.
Sources:
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.