5 Easy Steps to Automate Knowledge Cleansing with Python
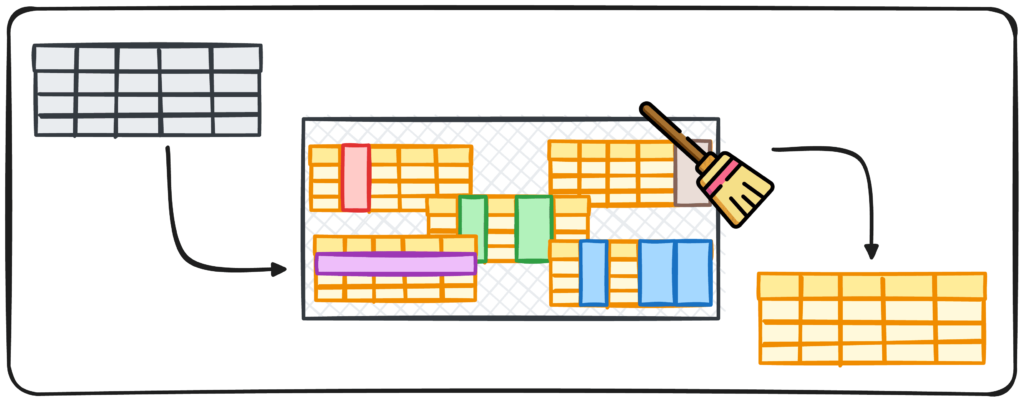
Picture by Writer
It’s a broadly unfold truth amongst Knowledge Scientists that knowledge cleansing makes up a giant proportion of our working time. Nonetheless, it is without doubt one of the least thrilling elements as properly. So this results in a really pure query:
Is there a method to automate this course of?
Automating any course of is at all times simpler stated than achieved for the reason that steps to carry out rely totally on the particular mission and purpose. However there are at all times methods to automate, at the very least, a number of the elements.
This text goals to generate a pipeline with some steps to verify our knowledge is clear and prepared for use.
Knowledge Cleansing Course of
Earlier than continuing to generate the pipeline, we have to perceive what elements of the processes will be automated.
Since we wish to construct a course of that can be utilized for nearly any knowledge science mission, we have to first decide what steps are carried out time and again.
So when working with a brand new knowledge set, we often ask the next questions:
- What format does the information are available?
- Does the information comprise duplicates?
- Does the knowledge comprise lacking values?
- What knowledge sorts does the information comprise?
- Does the information comprise outliers?
These 5 questions can simply be transformed into 5 blocks of code to take care of every of the questions:
1.Knowledge Format
Knowledge can come in numerous codecs, equivalent to JSON, CSV, and even XML. Each format requires its personal knowledge parser. For example, pandas present read_csv for CSV information, and read_json for JSON information.
By figuring out the format, you may select the appropriate software to start the cleansing course of.
We are able to simply determine the format of the file we’re coping with utilizing the trail.plaintext perform from the os library. Due to this fact, we are able to create a perform that first determines what extension we’ve got, after which applies on to the corresponding parser.
2. Duplicates
It occurs very often that some rows of the information comprise the identical actual values as different rows, what we all know as duplicates. Duplicated knowledge can skew outcomes and result in inaccurate analyses, which isn’t good in any respect.
Because of this we at all times want to verify there aren’t any duplicates.
Pandas received us lined with the drop_duplicated() technique, which erases all duplicated rows of a dataframe.
We are able to create an easy perform that makes use of this technique to take away all duplicates. If vital, we add a columns enter variable that adapts the perform to remove duplicates based mostly on a selected checklist of column names.
3. Lacking Values
Lacking knowledge is a standard challenge when working with knowledge as properly. Relying on the character of your knowledge, we are able to merely delete the observations containing lacking values, or we are able to fill these gaps utilizing strategies like ahead fill, backward fill, or substituting with the imply or median of the column.
Pandas gives us the .fillna() and .dropna() strategies to deal with these lacking values successfully.
The selection of how we deal with lacking values is determined by:
- The kind of values which can be lacking
- The proportion of lacking values relative to the variety of complete data we’ve got.
Coping with lacking values is a fairly advanced activity to carry out – and often one of the necessary ones! – you may be taught extra about it in the following article.
For our pipeline, we’ll first verify the whole variety of rows that current null values. If solely 5% of them or much less are affected, we’ll erase these data. In case extra rows current lacking values, we’ll verify column by column and can proceed with both:
- Imputing the median of the worth.
- Generate a warning to additional examine.
On this case, we’re assessing the lacking values with a hybrid human validation course of. As you already know, assessing lacking values is a vital activity that may not be ignored.
When working with common knowledge sorts we are able to proceed to remodel the columns instantly with the pandas .astype() perform, so you possibly can truly modify the code to generate common conversations.
In any other case, it’s often too dangerous to imagine {that a} transformation shall be carried out easily when working with new knowledge.
5. Coping with Outliers
Outliers can considerably have an effect on the outcomes of your knowledge evaluation. Methods to deal with outliers embrace setting thresholds, capping values, or utilizing statistical strategies like Z-score.
With the intention to decide if we’ve got outliers in our dataset, we use a standard rule and take into account any document exterior of the next vary as an outlier. [Q1 — 1.5 * IQR , Q3 + 1.5 * IQR]
The place IQR stands for the interquartile vary and Q1 and Q3 are the first and the third quartiles. Beneath you may observe all of the earlier ideas displayed in a boxplot.
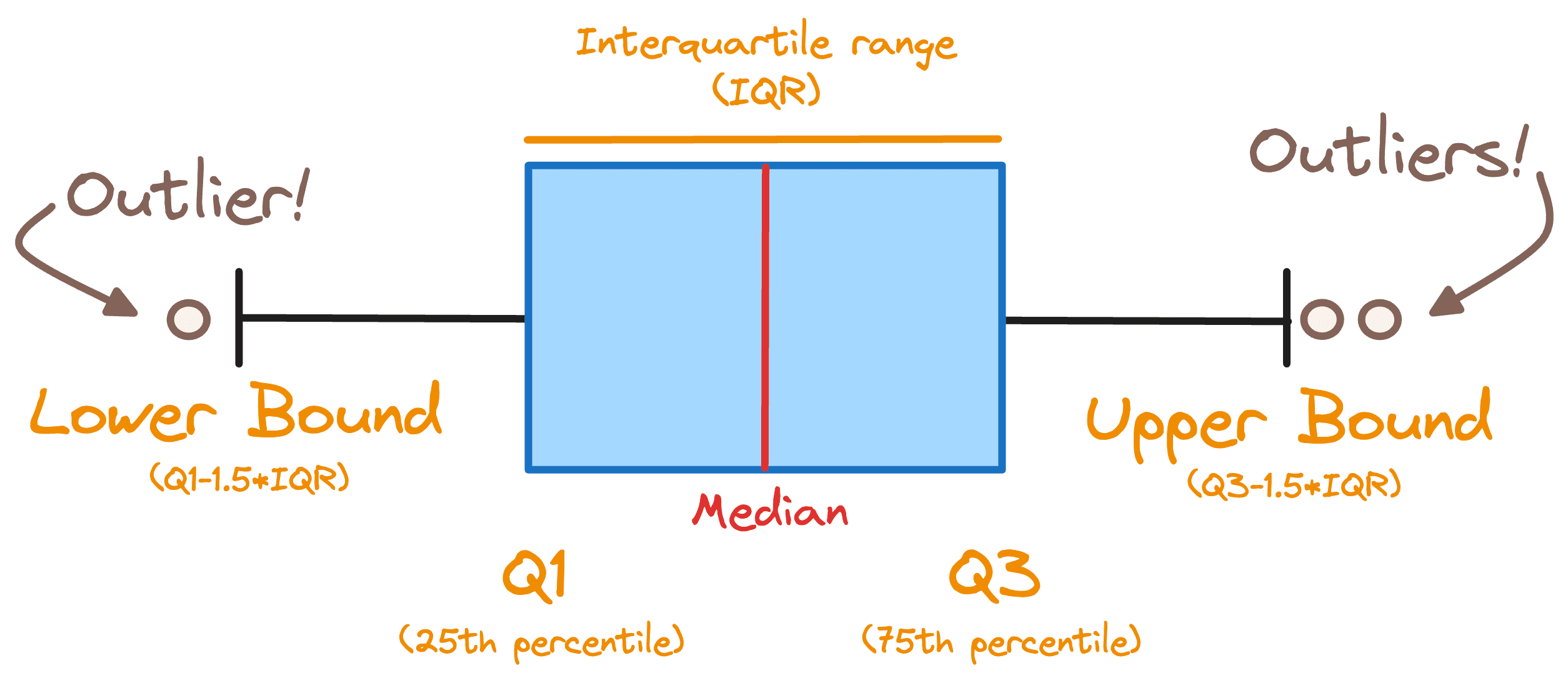
Picture by Writer
To detect the presence of outliers, we are able to simply outline a perform that checks what columns current values which can be out of the earlier vary and generate a warning.
Last Ideas
Knowledge Cleansing is a vital a part of any knowledge mission, nevertheless, it’s often probably the most boring and time-wasting part as properly. Because of this this text successfully distills a complete method right into a sensible 5-step pipeline for automating knowledge cleansing utilizing Python and.
The pipeline is not only about implementing code. It integrates considerate decision-making standards that information the consumer by dealing with totally different knowledge eventualities.
This mix of automation with human oversight ensures each effectivity and accuracy, making it a sturdy resolution for knowledge scientists aiming to optimize their workflow.
You possibly can go verify my entire code within the following GitHub repo.
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is at present working within the knowledge science area utilized to human mobility. He’s a part-time content material creator targeted on knowledge science and expertise. Josep writes on all issues AI, masking the appliance of the continuing explosion within the area.





