Fantastic-tune and deploy language fashions with Amazon SageMaker Canvas and Amazon Bedrock
Think about harnessing the ability of superior language fashions to know and reply to your clients’ inquiries. Amazon Bedrock, a totally managed service offering entry to such fashions, makes this potential. Fantastic-tuning giant language fashions (LLMs) on domain-specific knowledge supercharges duties like answering product questions or producing related content material.
On this submit, we present how Amazon Bedrock and Amazon SageMaker Canvas, a no-code AI suite, enable enterprise customers with out deep technical experience to fine-tune and deploy LLMs. You’ll be able to remodel buyer interplay utilizing datasets like product Q&As with just some clicks utilizing Amazon Bedrock and Amazon SageMaker JumpStart fashions.
Answer overview
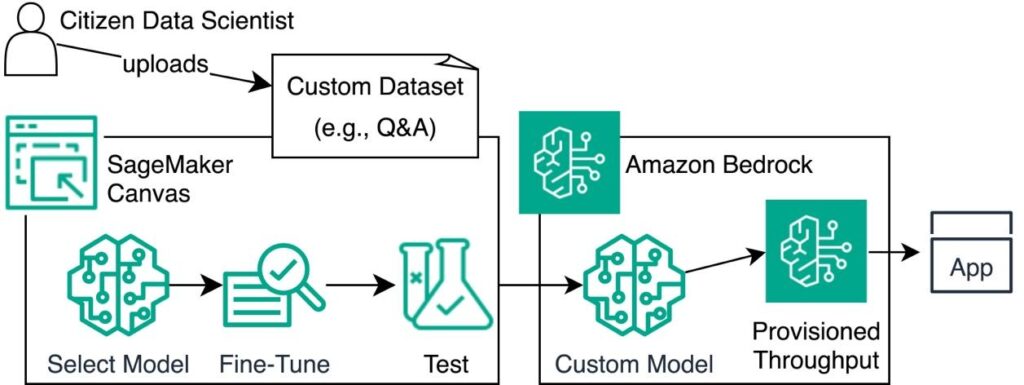
The next diagram illustrates this structure.

Within the following sections, we present you the best way to fine-tune a mannequin by making ready your dataset, creating a brand new mannequin, importing the dataset, and choosing a basis mannequin. We additionally reveal the best way to analyze and check the mannequin, after which deploy the mannequin by way of Amazon Bedrock.
Conditions
First-time customers want an AWS account and AWS Identity and Access Management (IAM) function with SageMaker, Amazon Bedrock, and Amazon Simple Storage Service (Amazon S3) entry.
To observe together with this submit, full the prerequisite steps to create a website and allow entry to Amazon Bedrock fashions:
- Create a SageMaker domain.
- On the area particulars web page, view the person profiles.
- Select Launch by your profile, and select Canvas.
- Affirm that your SageMaker IAM function and area roles have the necessary permissions and trust relationships.
- On the Amazon Bedrock console, select Mannequin entry within the navigation pane.
- Select Handle mannequin entry.
- Choose Amazon to allow the Amazon Titan mannequin.
Put together your dataset
Full the next steps to arrange your dataset:
- Obtain the next CSV dataset of question-answer pairs.
- Affirm that your dataset is free from formatting points.
- Copy the info to a brand new sheet and delete the unique.
Create a brand new mannequin
SageMaker Canvas allows simultaneous fine-tuning of multiple models, enabling you to match and select one of the best one from a leaderboard after fine-tuning. Nevertheless, this submit focuses on the Amazon Titan Textual content G1-Categorical LLM. Full the next steps to create your mannequin:
- In SageMaker canvas, select My fashions within the navigation pane.
- Select New mannequin.
- For Mannequin identify, enter a reputation (for instance,
MyModel). - For Downside kind¸ choose Fantastic-tune basis mannequin.
- Select Create.

The subsequent step is to import your dataset into SageMaker Canvas:
- Create a dataset named QA-Pairs.
- Add the ready CSV file or choose it from an S3 bucket.
- Select the dataset, then select Choose dataset.
Choose a basis mannequin
After you add your dataset, choose a basis mannequin and fine-tune it together with your dataset. Full the next steps:
- On the Fantastic-tune tab, on the Choose base fashions menu¸ choose Titan Categorical.
- For Choose enter column, select query.
- For Choose output column, select reply.
- Select Fantastic-tune.

Wait 2–5 hours for SageMaker to complete fine-tuning your fashions.
Analyze the mannequin
When the fine-tuning is full, you may view the stats about your new mannequin, together with:
- Coaching loss – The penalty for every mistake in next-word prediction throughout coaching. Decrease values point out higher efficiency.
- Coaching perplexity – A measure of the mannequin’s shock when encountering textual content throughout coaching. Decrease perplexity suggests increased mannequin confidence.
- Validation loss and validation perplexity – Just like the coaching metrics, however measured through the validation stage.
To get an in depth report in your {custom} mannequin’s efficiency throughout varied dimensions, resembling toxicity and accuracy, select Generate analysis report. Then choose Obtain report.

Canvas provides a Python Jupyter pocket book detailing your fine-tuning job, assuaging issues about vendor lock-in related to no-code instruments and enabling element sharing with knowledge science groups for additional validation and deployment.
In the event you chosen a number of basis fashions to create {custom} fashions out of your dataset, try the Mannequin leaderboard to match them on dimensions like loss and perplexity.

Take a look at the fashions
You now have entry to {custom} fashions that may be examined in SageMaker Canvas. Full the next steps to check the fashions:
- Select Take a look at in Prepared-to-Use Fashions and wait 15–half-hour to your check endpoint to be deployed.
This check endpoint will solely watch for 2 hours to keep away from unintended prices.
When the deployment is full, you’ll be redirected to the SageMaker Canvas playground, together with your mannequin pre-selected.
- Select Evaluate and choose the inspiration mannequin used to your {custom} mannequin.
- Enter a phrase immediately out of your coaching dataset, to ensure the {custom} mannequin no less than does higher at such a query.
For this instance, we enter the query, “Who developed the lie-detecting algorithm Fraudoscope?”
The fine-tuned mannequin responded appropriately:
“The lie-detecting algorithm Fraudoscope was developed by Tselina Information Lab.”
Amazon Titan responded incorrectly and verbosely. Nevertheless, to its credit score, the mannequin produced vital moral issues and limitations of facial recognition applied sciences on the whole:

Let’s ask a query about an NVIDIA chip, which powers Amazon Elastic Compute Cloud (Amazon EC2) P4d situations: “How a lot reminiscence in an A100?”
Once more, the {custom} mannequin not solely will get the reply extra right, but it surely additionally solutions with the brevity you’d need from a question-answer bot:
“An A100 GPU supplies as much as 40 GB of high-speed HBM2 reminiscence.”
The Amazon Titan reply is wrong:

Deploy the mannequin by way of Amazon Bedrock
For manufacturing use, particularly for those who’re contemplating offering entry to dozens and even hundreds of workers by embedding the mannequin into an utility, you may deploy the fashions as API endpoints. Full the next steps to deploy your mannequin:
- On the Amazon Bedrock console, select Basis fashions within the navigation pane, then select Customized fashions.
- Find the mannequin with the prefix Canvas- with Amazon Titan because the supply.
Alternatively, you should utilize the AWS Command Line Interface (AWS CLI): aws bedrock list-custom-models
- Make word of the
modelArn, which you’ll use within the subsequent step, and themodelName, or save them immediately as variables:
To begin utilizing your mannequin, you could provision throughput.
- On the Amazon Bedrock console, select Buy Provisioned Throughput.
- Title it, set 1 mannequin unit, no dedication time period.
- Affirm the acquisition.
Alternatively, you should utilize the AWS CLI:
Or, for those who saved the values as variables within the earlier step, use the next code:
After about 5 minutes, the mannequin standing modifications from Creating to InService.
In the event you’re utilizing the AWS CLI, you may see the standing by way of aws bedrock list-provisioned-model-throughputs.
Use the mannequin
You’ll be able to entry your fine-tuned LLM by way of the Amazon Bedrock console, API, CLI, or SDKs.
Within the Chat Playground, select the class of fine-tuned fashions, choose your Canvas- prefixed mannequin, and the provisioned throughput.

Enrich your present software program as a service (SaaS), software program platforms, net portals, or cellular apps together with your fine-tuned LLM utilizing the API or SDKs. These allow you to ship prompts to the Amazon Bedrock endpoint utilizing your most well-liked programming language.
The response demonstrates the mannequin’s tailor-made potential to reply all these questions:
“The lie-detecting algorithm Fraudoscope was developed by Tselina Information Lab.”
This improves the response from Amazon Titan earlier than fine-tuning:
“Marston Morse developed the lie-detecting algorithm Fraudoscope.”
For a full instance of invoking fashions on Amazon Bedrock, discuss with the next GitHub repository. This repository supplies a ready-to-use code base that allows you to experiment with varied LLMs and deploy a flexible chatbot structure inside your AWS account. You now have the abilities to make use of this together with your {custom} mannequin.
One other repository which will spark your creativeness is Amazon Bedrock Samples, which may also help you get began on a variety of different use instances.
Conclusion
On this submit, we confirmed you the best way to fine-tune an LLM to higher match your corporation wants, deploy your {custom} mannequin as an Amazon Bedrock API endpoint, and use that endpoint in utility code. This unlocked the {custom} language mannequin’s energy to a broader set of individuals inside your corporation.
Though we used examples based mostly on a pattern dataset, this submit showcased these instruments’ capabilities and potential functions in real-world eventualities. The method is simple and relevant to varied datasets, resembling your group’s FAQs, offered they’re in CSV format.
Take what you discovered and begin brainstorming methods to make use of {custom} AI fashions in your group. For additional inspiration, see Overcoming common contact center challenges with generative AI and Amazon SageMaker Canvas and AWS re:Invent 2023 – New LLM capabilities in Amazon SageMaker Canvas, with Bain & Company (AIM363).
Concerning the Authors
![]() Yann Stoneman is a Options Architect at AWS centered on machine studying and serverless utility growth. With a background in software program engineering and a mix of arts and tech training from Juilliard and Columbia, Yann brings a inventive strategy to AI challenges. He actively shares his experience by way of his YouTube channel, weblog posts, and shows.
Yann Stoneman is a Options Architect at AWS centered on machine studying and serverless utility growth. With a background in software program engineering and a mix of arts and tech training from Juilliard and Columbia, Yann brings a inventive strategy to AI challenges. He actively shares his experience by way of his YouTube channel, weblog posts, and shows.
 Davide Gallitelli is a Specialist Options Architect for AI/ML within the EMEA area. He’s based mostly in Brussels and works intently with buyer all through Benelux. He has been a developer since very younger, beginning to code on the age of seven. He began studying AI/ML in his later years of college, and has fallen in love with it since then.
Davide Gallitelli is a Specialist Options Architect for AI/ML within the EMEA area. He’s based mostly in Brussels and works intently with buyer all through Benelux. He has been a developer since very younger, beginning to code on the age of seven. He began studying AI/ML in his later years of college, and has fallen in love with it since then.





