Mistral vs Mixtral: Evaluating the 7B, 8x7B, and 8x22B Giant Language Fashions | by Dmitrii Eliuseev | Apr, 2024

Operating the 7B and 22B Fashions in Google Colab

Not so way back, all IT information channels reported concerning the new open Mixtral 8x22B mannequin, which outperforms ChatGPT 3.5 on benchmarks like MMLU (huge multitask language understanding) or WinoGrande (commonsense reasoning). It is a nice achievement for the world of open fashions. Naturally, educational benchmarks are fascinating, however how does this mannequin virtually work? What system necessities does it have, and is it actually higher in comparison with earlier language fashions? On this article, I’ll check 4 totally different fashions (7B, 8x7B, 22B, and 8x22B, with and with out a “Combination of Consultants” structure), and we are going to see the outcomes.
Let’s get began!
As an apart notice, I’ve no enterprise relationship with Mistral AI, and all exams listed below are finished by myself.
Sparse Combination of Consultants (SMoE)
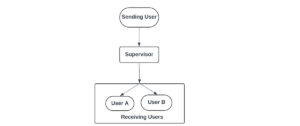
Already at the start of the LLM period, it grew to become identified that bigger fashions are, typically talking, smarter, have extra data, and might obtain higher outcomes. However bigger fashions are additionally extra computationally costly. No one will look forward to the chatbot’s response if it takes 5 minutes. The intuitive thought behind the “combination of specialists” is straightforward — let’s take a number of fashions and add a particular layer that may ahead totally different inquiries to the totally different fashions:

As we will see, the concept isn’t new. The paper about MoE was revealed in 2017, however solely 5–7 years later, when the mannequin’s use shifted from an educational to a business perspective, it grew to become necessary. The MoE strategy offers us a big enchancment: we will have a big language mannequin that has lots of data however on the similar time works sooner, like a smaller one. For instance, a Mixtral 8x7B mannequin has 47B parameters, however solely 13B parameters are energetic at any given time. A Mixtral 8x22B mannequin has 141B parameters, however solely 39B are energetic.
Now, once we get a normal thought, it’s time to see the way it virtually works. Right here, I’ll check 4 fashions: