Construct an lively studying pipeline for automated annotation of photographs with AWS companies
This weblog submit is co-written with Caroline Chung from Veoneer.
Veoneer is a world automotive electronics firm and a world chief in automotive digital security programs. They provide best-in-class restraint management programs and have delivered over 1 billion digital management items and crash sensors to automotive producers globally. The corporate continues to construct on a 70-year historical past of automotive security growth, specializing in cutting-edge {hardware} and programs that forestall visitors incidents and mitigate accidents.
Automotive in-cabin sensing (ICS) is an rising area that makes use of a mixture of a number of kinds of sensors similar to cameras and radar, and synthetic intelligence (AI) and machine studying (ML) primarily based algorithms for enhancing security and bettering using expertise. Constructing such a system could be a advanced activity. Builders should manually annotate massive volumes of photographs for coaching and testing functions. That is very time consuming and useful resource intensive. The turnaround time for such a activity is a number of weeks. Moreover, firms should cope with points similar to inconsistent labels as a result of human errors.
AWS is targeted on serving to you enhance your growth pace and decrease your prices for constructing such programs by way of superior analytics like ML. Our imaginative and prescient is to make use of ML for automated annotation, enabling retraining of security fashions, and making certain constant and dependable efficiency metrics. On this submit, we share how, by collaborating with Amazon’s Worldwide Specialist Group and the Generative AI Innovation Center, we developed an lively studying pipeline for in-cabin picture head bounding packing containers and key factors annotation. The answer reduces value by over 90%, accelerates the annotation course of from weeks to hours when it comes to the turnaround time, and permits reusability for related ML information labeling duties.
Resolution overview
Energetic studying is an ML strategy that entails an iterative course of of choosing and annotating essentially the most informative information to coach a mannequin. Given a small set of labeled information and a big set of unlabeled information, lively studying improves mannequin efficiency, reduces labeling effort, and integrates human experience for sturdy outcomes. On this submit, we construct an lively studying pipeline for picture annotations with AWS companies.
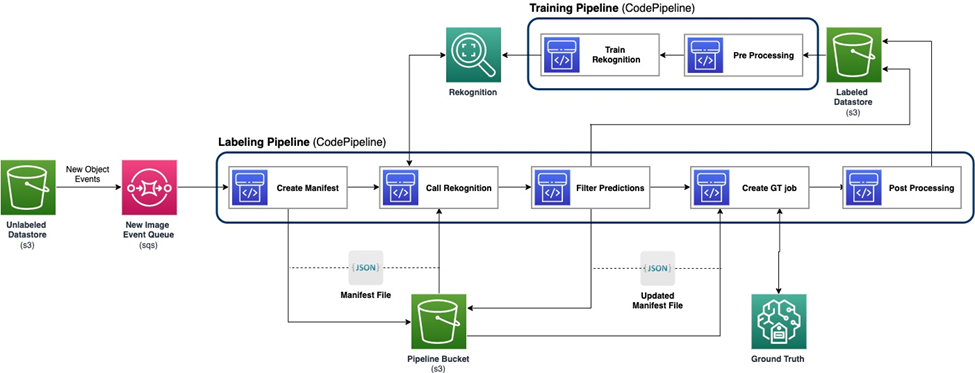
The next diagram demonstrates the general framework for our lively studying pipeline. The labeling pipeline takes photographs from an Amazon Simple Storage Service (Amazon S3) bucket and outputs annotated photographs with the cooperation of ML fashions and human experience. The coaching pipeline preprocesses information and makes use of them to coach ML fashions. The preliminary mannequin is ready up and educated on a small set of manually labeled information, and shall be used within the labeling pipeline. The labeling pipeline and coaching pipeline will be iterated regularly with extra labeled information to boost the mannequin’s efficiency.

Within the labeling pipeline, an Amazon S3 Event Notification is invoked when a brand new batch of photographs comes into the Unlabeled Datastore S3 bucket, activating the labeling pipeline. The mannequin produces the inference outcomes on the brand new photographs. A personalized judgement perform selects components of the information primarily based on the inference confidence rating or different user-defined capabilities. This information, with its inference outcomes, is distributed for a human labeling job on Amazon SageMaker Ground Truth created by the pipeline. The human labeling course of helps annotate the information, and the modified outcomes are mixed with the remaining auto annotated information, which can be utilized later by the coaching pipeline.
Mannequin retraining occurs within the coaching pipeline, the place we use the dataset containing the human-labeled information to retrain the mannequin. A manifest file is produced to explain the place the information are saved, and the identical preliminary mannequin is retrained on the brand new information. After retraining, the brand new mannequin replaces the preliminary mannequin, and the subsequent iteration of the lively studying pipeline begins.
Mannequin deployment
Each the labeling pipeline and coaching pipeline are deployed on AWS CodePipeline. AWS CodeBuild cases are used for implementation, which is versatile and quick for a small quantity of information. When pace is required, we use Amazon SageMaker endpoints primarily based on the GPU occasion to allocate extra sources to help and speed up the method.
The mannequin retraining pipeline will be invoked when there may be new dataset or when the mannequin’s efficiency wants enchancment. One crucial activity within the retraining pipeline is to have the model management system for each the coaching information and the mannequin. Though AWS companies similar to Amazon Rekognition have the built-in model management function, which makes the pipeline simple to implement, personalized fashions require metadata logging or extra model management instruments.
The whole workflow is applied utilizing the AWS Cloud Development Kit (AWS CDK) to create essential AWS parts, together with the next:
- Two roles for CodePipeline and SageMaker jobs
- Two CodePipeline jobs, which orchestrate the workflow
- Two S3 buckets for the code artifacts of the pipelines
- One S3 bucket for labeling the job manifest, datasets, and fashions
- Preprocessing and postprocessing AWS Lambda capabilities for the SageMaker Floor Fact labeling jobs
The AWS CDK stacks are extremely modularized and reusable throughout totally different duties. The coaching, inference code, and SageMaker Floor Fact template will be changed for any related lively studying situations.
Mannequin coaching
Mannequin coaching contains two duties: head bounding field annotation and human key factors annotation. We introduce them each on this part.
Head bounding field annotation
Head bounding field annotation is a activity to foretell the situation of a bounding field of the human head in a picture. We use an Amazon Rekognition Custom Labels mannequin for head bounding field annotations. The next sample notebook offers a step-by-step tutorial on find out how to prepare a Rekognition Customized Labels mannequin through SageMaker.
We first want to arrange the information to begin the coaching. We generate a manifest file for the coaching and a manifest file for the take a look at dataset. A manifest file incorporates a number of gadgets, every of which is for a picture. The next is an instance of the manifest file, which incorporates the picture path, dimension, and annotation data:
Utilizing the manifest information, we will load datasets to a Rekognition Customized Labels mannequin for coaching and testing. We iterated the mannequin with totally different quantities of coaching information and examined it on the identical 239 unseen photographs. On this take a look at, the mAP_50 rating elevated from 0.33 with 114 coaching photographs to 0.95 with 957 coaching photographs. The next screenshot reveals the efficiency metrics of the ultimate Rekognition Customized Labels mannequin, which yields nice efficiency when it comes to F1 rating, precision, and recall.

We additional examined the mannequin on a withheld dataset that has 1,128 photographs. The mannequin constantly predicts correct bounding field predictions on the unseen information, yielding a excessive mAP_50 of 94.9%. The next instance reveals an auto-annotated picture with a head bounding field.

Key factors annotation
Key factors annotation produces areas of key factors, together with eyes, ears, nostril, mouth, neck, shoulders, elbows, wrists, hips, and ankles. Along with the situation prediction, visibility of every level is required to foretell on this particular activity, for which we design a novel methodology.
For key factors annotation, we use a Yolo 8 Pose model on SageMaker because the preliminary mannequin. We first put together the information for coaching, together with producing label information and a configuration .yaml file following Yolo’s necessities. After getting ready the information, we prepare the mannequin and save artifacts, together with the mannequin weights file. With the educated mannequin weights file, we will annotate the brand new photographs.
Within the coaching stage, all of the labeled factors with areas, together with seen factors and occluded factors, are used for coaching. Due to this fact, this mannequin by default offers the situation and confidence of the prediction. Within the following determine, a big confidence threshold (fundamental threshold) close to 0.6 is able to dividing the factors which can be seen or occluded versus outdoors of digicam’s viewpoints. Nonetheless, occluded factors and visual factors are usually not separated by the arrogance, which implies the anticipated confidence is just not helpful for predicting the visibility.

To get the prediction of visibility, we introduce an extra mannequin educated on the dataset containing solely seen factors, excluding each occluded factors and out of doors of digicam’s viewpoints. The next determine reveals the distribution of factors with totally different visibility. Seen factors and different factors will be separated within the extra mannequin. We are able to use a threshold (extra threshold) close to 0.6 to get the seen factors. By combining these two fashions, we design a technique to foretell the situation and visibility.

A key level is first predicted by the primary mannequin with location and fundamental confidence, then we get the extra confidence prediction from the extra mannequin. Its visibility is then labeled as follows:
- Seen, if its fundamental confidence is larger than its fundamental threshold, and its extra confidence is larger than the extra threshold
- Occluded, if its fundamental confidence is larger than its fundamental threshold, and its extra confidence is lower than or equal to the extra threshold
- Outdoors of digicam’s assessment, if in any other case
An instance of key factors annotation is demonstrated within the following picture, the place strong marks are seen factors and hole marks are occluded factors. Outdoors of the digicam’s assessment factors are usually not proven.

Based mostly on the usual OKS definition on the MS-COCO dataset, our methodology is ready to obtain mAP_50 of 98.4% on the unseen take a look at dataset. When it comes to visibility, the tactic yields a 79.2% classification accuracy on the identical dataset.
Human labeling and retraining
Though the fashions obtain nice efficiency on take a look at information, there are nonetheless prospects for making errors on new real-world information. Human labeling is the method to appropriate these errors for enhancing mannequin efficiency utilizing retraining. We designed a judgement perform that mixed the arrogance worth that output from the ML fashions for the output of all head bounding field or key factors. We use the ultimate rating to determine these errors and the resultant dangerous labeled photographs, which have to be despatched to the human labeling course of.
Along with dangerous labeled photographs, a small portion of photographs are randomly chosen for human labeling. These human-labeled photographs are added into the present model of the coaching set for retraining, enhancing mannequin efficiency and general annotation accuracy.
Within the implementation, we use SageMaker Floor Fact for the human labeling course of. SageMaker Floor Fact offers a user-friendly and intuitive UI for information labeling. The next screenshot demonstrates a SageMaker Floor Fact labeling job for head bounding field annotation.

The next screenshot demonstrates a SageMaker Floor Fact labeling job for key factors annotation.

Value, pace, and reusability
Value and pace are the important thing benefits of utilizing our resolution in comparison with human labeling, as proven within the following tables. We use these tables to signify the associated fee financial savings and pace accelerations. Utilizing the accelerated GPU SageMaker occasion ml.g4dn.xlarge, the entire life coaching and inference value on 100,000 photographs is 99% lower than the price of human labeling, whereas the pace is 10–10,000 instances quicker than the human labeling, relying on the duty.
The primary desk summarizes the associated fee efficiency metrics.
| Mannequin | mAP_50 primarily based on 1,128 take a look at photographs | Coaching value primarily based on 100,000 photographs | Inference value primarily based on 100,000 photographs | Value discount in comparison with human annotation | Inference time primarily based on 100,000 photographs | Time acceleration in comparison with human annotation |
| Rekognition head bounding field | 0.949 | $4 | $22 | 99% much less | 5.5 h | Days |
| Yolo Key factors | 0.984 | $27.20 | * $10 | 99.9% much less | minutes | Weeks |
The next desk summarizes efficiency metrics.
| Annotation Process | mAP_50 (%) | Coaching Value ($) | Inference Value ($) | Inference Time |
| Head Bounding Field | 94.9 | 4 | 22 | 5.5 hours |
| Key Factors | 98.4 | 27 | 10 | 5 minutes |
Furthermore, our resolution offers reusability for related duties. Digicam notion developments for different programs like superior driver help system (ADAS) and in-cabin programs can even undertake our resolution.
Abstract
On this submit, we confirmed find out how to construct an lively studying pipeline for automated annotation of in-cabin photographs using AWS companies. We exhibit the facility of ML, which allows you to automate and expedite the annotation course of, and the flexibleness of the framework that makes use of fashions both supported by AWS companies or personalized on SageMaker. With Amazon S3, SageMaker, Lambda, and SageMaker Floor Fact, you possibly can streamline information storage, annotation, coaching, and deployment, and obtain reusability whereas lowering prices considerably. By implementing this resolution, automotive firms can turn out to be extra agile and cost-efficient through the use of ML-based superior analytics similar to automated picture annotation.
Get began at present and unlock the facility of AWS services and machine studying on your automotive in-cabin sensing use circumstances!
Concerning the Authors
 Yanxiang Yu is an Utilized Scientist at on the Amazon Generative AI Innovation Middle. With over 9 years of expertise constructing AI and machine studying options for industrial functions, he focuses on generative AI, laptop imaginative and prescient, and time sequence modeling.
Yanxiang Yu is an Utilized Scientist at on the Amazon Generative AI Innovation Middle. With over 9 years of expertise constructing AI and machine studying options for industrial functions, he focuses on generative AI, laptop imaginative and prescient, and time sequence modeling.
 Tianyi Mao is an Utilized Scientist at AWS primarily based out of Chicago space. He has 5+ years of expertise in constructing machine studying and deep studying options and focuses on laptop imaginative and prescient and reinforcement studying with human feedbacks. He enjoys working with prospects to grasp their challenges and remedy them by creating progressive options utilizing AWS companies.
Tianyi Mao is an Utilized Scientist at AWS primarily based out of Chicago space. He has 5+ years of expertise in constructing machine studying and deep studying options and focuses on laptop imaginative and prescient and reinforcement studying with human feedbacks. He enjoys working with prospects to grasp their challenges and remedy them by creating progressive options utilizing AWS companies.
 Yanru Xiao is an Utilized Scientist on the Amazon Generative AI Innovation Middle, the place he builds AI/ML options for patrons’ real-world enterprise issues. He has labored in a number of fields, together with manufacturing, power, and agriculture. Yanru obtained his Ph.D. in Pc Science from Outdated Dominion College.
Yanru Xiao is an Utilized Scientist on the Amazon Generative AI Innovation Middle, the place he builds AI/ML options for patrons’ real-world enterprise issues. He has labored in a number of fields, together with manufacturing, power, and agriculture. Yanru obtained his Ph.D. in Pc Science from Outdated Dominion College.
 Paul George is an completed product chief with over 15 years of expertise in automotive applied sciences. He’s adept at main product administration, technique, Go-to-Market and programs engineering groups. He has incubated and launched a number of new sensing and notion merchandise globally. At AWS, he’s main technique and go-to-market for autonomous automobile workloads.
Paul George is an completed product chief with over 15 years of expertise in automotive applied sciences. He’s adept at main product administration, technique, Go-to-Market and programs engineering groups. He has incubated and launched a number of new sensing and notion merchandise globally. At AWS, he’s main technique and go-to-market for autonomous automobile workloads.
 Caroline Chung is an engineering supervisor at Veoneer (acquired by Magna Worldwide), she has over 14 years of expertise growing sensing and notion programs. She at the moment leads inside sensing pre-development applications at Magna Worldwide managing a workforce of compute imaginative and prescient engineers and information scientists.
Caroline Chung is an engineering supervisor at Veoneer (acquired by Magna Worldwide), she has over 14 years of expertise growing sensing and notion programs. She at the moment leads inside sensing pre-development applications at Magna Worldwide managing a workforce of compute imaginative and prescient engineers and information scientists.




