Federated studying on AWS utilizing FedML, Amazon EKS, and Amazon SageMaker
This publish is co-written with Chaoyang He, Al Nevarez and Salman Avestimehr from FedML.
Many organizations are implementing machine studying (ML) to boost their enterprise decision-making by means of automation and using giant distributed datasets. With elevated entry to information, ML has the potential to supply unparalleled enterprise insights and alternatives. Nevertheless, the sharing of uncooked, non-sanitized delicate data throughout completely different places poses vital safety and privateness dangers, particularly in regulated industries resembling healthcare.
To deal with this problem, federated studying (FL) is a decentralized and collaborative ML coaching method that gives information privateness whereas sustaining accuracy and constancy. Not like conventional ML coaching, FL coaching happens inside an remoted shopper location utilizing an unbiased safe session. The shopper solely shares its output mannequin parameters with a centralized server, often called the coaching coordinator or aggregation server, and never the precise information used to coach the mannequin. This strategy alleviates many information privateness issues whereas enabling efficient collaboration on mannequin coaching.
Though FL is a step in the direction of reaching higher information privateness and safety, it’s not a assured resolution. Insecure networks missing entry management and encryption can nonetheless expose delicate data to attackers. Moreover, domestically skilled data can expose non-public information if reconstructed by means of an inference assault. To mitigate these dangers, the FL mannequin makes use of customized coaching algorithms and efficient masking and parameterization earlier than sharing data with the coaching coordinator. Sturdy community controls at native and centralized places can additional scale back inference and exfiltration dangers.
On this publish, we share an FL strategy utilizing FedML, Amazon Elastic Kubernetes Service (Amazon EKS), and Amazon SageMaker to enhance affected person outcomes whereas addressing information privateness and safety issues.
The necessity for federated studying in healthcare
Healthcare depends closely on distributed information sources to make correct predictions and assessments about affected person care. Limiting the accessible information sources to guard privateness negatively impacts outcome accuracy and, in the end, the standard of affected person care. Subsequently, ML creates challenges for AWS clients who want to make sure privateness and safety throughout distributed entities with out compromising affected person outcomes.
Healthcare organizations should navigate strict compliance rules, such because the Well being Insurance coverage Portability and Accountability Act (HIPAA) in the US, whereas implementing FL options. Guaranteeing information privateness, safety, and compliance turns into much more vital in healthcare, requiring strong encryption, entry controls, auditing mechanisms, and safe communication protocols. Moreover, healthcare datasets typically comprise advanced and heterogeneous information sorts, making information standardization and interoperability a problem in FL settings.
Use case overview
The use case outlined on this publish is of coronary heart illness information in several organizations, on which an ML mannequin will run classification algorithms to foretell coronary heart illness within the affected person. As a result of this information is throughout organizations, we use federated studying to collate the findings.
The Heart Disease dataset from the College of California Irvine’s Machine Studying Repository is a broadly used dataset for cardiovascular analysis and predictive modeling. It consists of 303 samples, every representing a affected person, and incorporates a mix of medical and demographic attributes, in addition to the presence or absence of coronary heart illness.
This multivariate dataset has 76 attributes within the affected person data, out of which 14 attributes are mostly used for growing and evaluating ML algorithms to foretell the presence of coronary heart illness primarily based on the given attributes.
FedML framework
There’s a huge number of FL frameworks, however we determined to make use of the FedML framework for this use case as a result of it’s open supply and helps a number of FL paradigms. FedML offers a preferred open supply library, MLOps platform, and software ecosystem for FL. These facilitate the event and deployment of FL options. It offers a complete suite of instruments, libraries, and algorithms that allow researchers and practitioners to implement and experiment with FL algorithms in a distributed setting. FedML addresses the challenges of knowledge privateness, communication, and mannequin aggregation in FL, providing a user-friendly interface and customizable elements. With its deal with collaboration and information sharing, FedML goals to speed up the adoption of FL and drive innovation on this rising discipline. The FedML framework is mannequin agnostic, together with not too long ago added assist for big language fashions (LLMs). For extra data, discuss with Releasing FedLLM: Build Your Own Large Language Models on Proprietary Data using the FedML Platform.
FedML Octopus
System hierarchy and heterogeneity is a key problem in real-life FL use instances, the place completely different information silos could have completely different infrastructure with CPU and GPUs. In such eventualities, you need to use FedML Octopus.
FedML Octopus is the industrial-grade platform of cross-silo FL for cross-organization and cross-account coaching. Coupled with FedML MLOps, it allows builders or organizations to conduct open collaboration from anyplace at any scale in a safe method. FedML Octopus runs a distributed coaching paradigm inside every information silo and makes use of synchronous or asynchronous trainings.
FedML MLOps
FedML MLOps allows native growth of code that may later be deployed anyplace utilizing FedML frameworks. Earlier than initiating coaching, it’s essential to create a FedML account, in addition to create and add the server and shopper packages in FedML Octopus. For extra particulars, discuss with steps and Introducing FedML Octopus: scaling federated learning into production with simplified MLOps.
Resolution overview
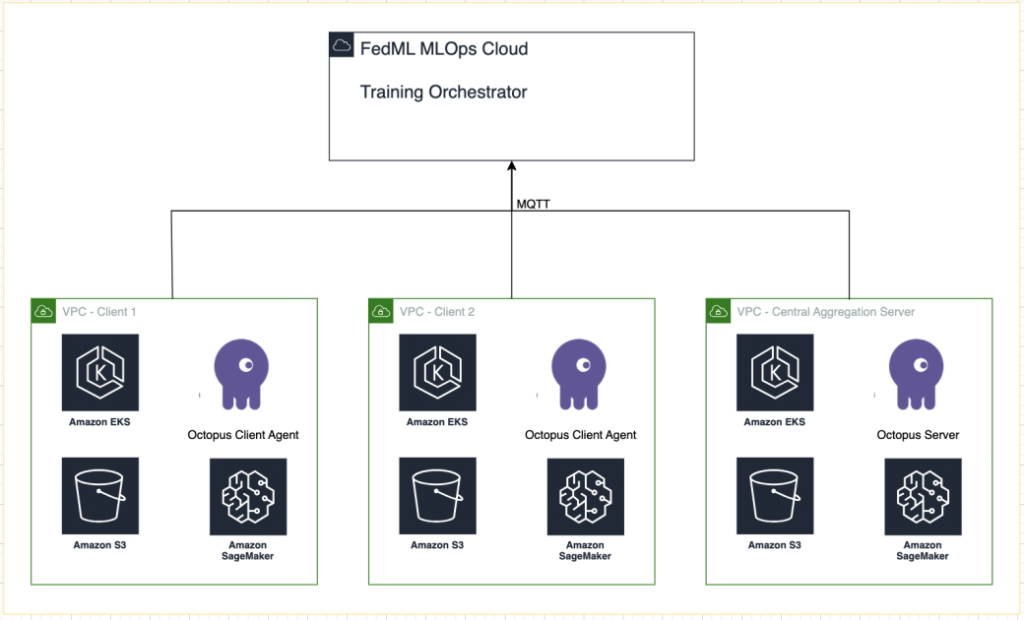
We deploy FedML into a number of EKS clusters built-in with SageMaker for experiment monitoring. We use Amazon EKS Blueprints for Terraform to deploy the required infrastructure. EKS Blueprints helps compose full EKS clusters which can be totally bootstrapped with the operational software program that’s wanted to deploy and function workloads. With EKS Blueprints, the configuration for the specified state of EKS setting, such because the management aircraft, employee nodes, and Kubernetes add-ons, is described as an infrastructure as code (IaC) blueprint. After a blueprint is configured, it may be used to create constant environments throughout a number of AWS accounts and Areas utilizing steady deployment automation.
The content material shared on this publish displays real-life conditions and experiences, but it surely’s essential to notice that the deployment of those conditions in several places could range. Though we make the most of a single AWS account with separate VPCs, it’s essential to know that particular person circumstances and configurations could differ. Subsequently, the data offered needs to be used as a normal information and should require adaptation primarily based on particular necessities and native situations.
The next diagram illustrates our resolution structure.

Along with the monitoring offered by FedML MLOps for every coaching run, we use Amazon SageMaker Experiments to trace the efficiency of every shopper mannequin and the centralized (aggregator) mannequin.
SageMaker Experiments is a functionality of SageMaker that permits you to create, handle, analyze, and examine your ML experiments. By recording experiment particulars, parameters, and outcomes, researchers can precisely reproduce and validate their work. It permits for efficient comparability and evaluation of various approaches, resulting in knowledgeable decision-making. Moreover, monitoring experiments facilitates iterative enchancment by offering insights into the development of fashions and enabling researchers to study from earlier iterations, in the end accelerating the event of more practical options.
We ship the next to SageMaker Experiments for every run:
- Mannequin analysis metrics – Coaching loss and Space Beneath the Curve (AUC)
- Hyperparameters – Epoch, studying charge, batch measurement, optimizer, and weight decay
Stipulations
To observe together with this publish, you must have the next conditions:
Deploy the answer
To start, clone the repository internet hosting the pattern code domestically:
Then deploy the use case infrastructure utilizing the next instructions:
The Terraform template could take 20–half-hour to totally deploy. After it’s deployed, observe the steps within the subsequent sections to run the FL software.
Create an MLOps deployment bundle
As part of the FedML documentation, we have to create the shopper and server packages, which the MLOps platform will distribute to the server and shoppers to start coaching.
To create these packages, run the next script discovered within the root listing:
This can create the respective packages within the following listing within the challenge’s root listing:
Add the packages to the FedML MLOps platform
Full the next steps to add the packages:
- On the FedML UI, select My Functions within the navigation pane.
- Select New Software.

- Add the shopper and server packages out of your workstation.

- You can too modify the hyperparameters or create new ones.

Set off federated coaching
To run federated coaching, full the next steps:
- On the FedML UI, select Undertaking Record within the navigation pane.
- Select Create a brand new challenge.
- Enter a bunch title and a challenge title, then select OK.

- Select the newly created challenge and select Create new run to set off a coaching run.

- Choose the sting shopper gadgets and the central aggregator server for this coaching run.
- Select the appliance that you simply created within the earlier steps.

- Replace any of the hyperparameters or use the default settings.
- Select Begin to begin coaching.

- Select the Coaching Standing tab and await the coaching run to finish. You can too navigate to the tabs accessible.
- When coaching is full, select the System tab to see the coaching time durations in your edge servers and aggregation occasions.
View outcomes and experiment particulars
When the coaching is full, you possibly can view the outcomes utilizing FedML and SageMaker.
On the FedML UI, on the Fashions tab, you possibly can see the aggregator and shopper mannequin. You can too obtain these fashions from the web site.
You can too log in to Amazon SageMaker Studio and select Experiments within the navigation pane.
The next screenshot reveals the logged experiments.

Experiment monitoring code
On this part, we discover the code that integrates SageMaker experiment monitoring with the FL framework coaching.
In an editor of your alternative, open the next folder to see the edits to the code to inject SageMaker experiment monitoring code as part of the coaching:
For monitoring the coaching, we create a SageMaker experiment with parameters and metrics logged utilizing the log_parameter and log_metric command as outlined within the following code pattern.
An entry within the config/fedml_config.yaml file declares the experiment prefix, which is referenced within the code to create distinctive experiment names: sm_experiment_name: "fed-heart-disease". You’ll be able to replace this to any worth of your alternative.
For instance, see the next code for the heart_disease_trainer.py, which is utilized by every shopper to coach the mannequin on their very own dataset:
For every shopper run, the experiment particulars are tracked utilizing the next code in heart_disease_trainer.py:
Equally, you need to use the code in heart_disease_aggregator.py to run a take a look at on native information after updating the mannequin weights. The main points are logged after every communication run with the shoppers.
Clear up
Whenever you’re accomplished with the answer, be certain that to wash up the assets used to make sure environment friendly useful resource utilization and price administration, and keep away from pointless bills and useful resource wastage. Energetic tidying up the setting, resembling deleting unused cases, stopping pointless providers, and eradicating momentary information, contributes to a clear and arranged infrastructure. You should utilize the next code to wash up your assets:
Abstract
By utilizing Amazon EKS because the infrastructure and FedML because the framework for FL, we’re in a position to present a scalable and managed setting for coaching and deploying shared fashions whereas respecting information privateness. With the decentralized nature of FL, organizations can collaborate securely, unlock the potential of distributed information, and enhance ML fashions with out compromising information privateness.
As at all times, AWS welcomes your suggestions. Please go away your ideas and questions within the feedback part.
Concerning the Authors
 Randy DeFauw is a Senior Principal Options Architect at AWS. He holds an MSEE from the College of Michigan, the place he labored on pc imaginative and prescient for autonomous autos. He additionally holds an MBA from Colorado State College. Randy has held quite a lot of positions within the expertise area, starting from software program engineering to product administration. He entered the large information area in 2013 and continues to discover that space. He’s actively engaged on tasks within the ML area and has offered at quite a few conferences, together with Strata and GlueCon.
Randy DeFauw is a Senior Principal Options Architect at AWS. He holds an MSEE from the College of Michigan, the place he labored on pc imaginative and prescient for autonomous autos. He additionally holds an MBA from Colorado State College. Randy has held quite a lot of positions within the expertise area, starting from software program engineering to product administration. He entered the large information area in 2013 and continues to discover that space. He’s actively engaged on tasks within the ML area and has offered at quite a few conferences, together with Strata and GlueCon.
 Arnab Sinha is a Senior Options Architect for AWS, performing as Discipline CTO to assist organizations design and construct scalable options supporting enterprise outcomes throughout information middle migrations, digital transformation and software modernization, huge information, and machine studying. He has supported clients throughout quite a lot of industries, together with power, retail, manufacturing, healthcare, and life sciences. Arnab holds all AWS Certifications, together with the ML Specialty Certification. Previous to becoming a member of AWS, Arnab was a expertise chief and beforehand held architect and engineering management roles.
Arnab Sinha is a Senior Options Architect for AWS, performing as Discipline CTO to assist organizations design and construct scalable options supporting enterprise outcomes throughout information middle migrations, digital transformation and software modernization, huge information, and machine studying. He has supported clients throughout quite a lot of industries, together with power, retail, manufacturing, healthcare, and life sciences. Arnab holds all AWS Certifications, together with the ML Specialty Certification. Previous to becoming a member of AWS, Arnab was a expertise chief and beforehand held architect and engineering management roles.
 Prachi Kulkarni is a Senior Options Architect at AWS. Her specialization is machine studying, and he or she is actively engaged on designing options utilizing varied AWS ML, huge information, and analytics choices. Prachi has expertise in a number of domains, together with healthcare, advantages, retail, and schooling, and has labored in a spread of positions in product engineering and structure, administration, and buyer success.
Prachi Kulkarni is a Senior Options Architect at AWS. Her specialization is machine studying, and he or she is actively engaged on designing options utilizing varied AWS ML, huge information, and analytics choices. Prachi has expertise in a number of domains, together with healthcare, advantages, retail, and schooling, and has labored in a spread of positions in product engineering and structure, administration, and buyer success.
 Tamer Sherif is a Principal Options Architect at AWS, with a various background within the expertise and enterprise consulting providers realm, spanning over 17 years as a Options Architect. With a deal with infrastructure, Tamer’s experience covers a broad spectrum of trade verticals, together with business, healthcare, automotive, public sector, manufacturing, oil and fuel, media providers, and extra. His proficiency extends to numerous domains, resembling cloud structure, edge computing, networking, storage, virtualization, enterprise productiveness, and technical management.
Tamer Sherif is a Principal Options Architect at AWS, with a various background within the expertise and enterprise consulting providers realm, spanning over 17 years as a Options Architect. With a deal with infrastructure, Tamer’s experience covers a broad spectrum of trade verticals, together with business, healthcare, automotive, public sector, manufacturing, oil and fuel, media providers, and extra. His proficiency extends to numerous domains, resembling cloud structure, edge computing, networking, storage, virtualization, enterprise productiveness, and technical management.
 Hans Nesbitt is a Senior Options Architect at AWS primarily based out of Southern California. He works with clients throughout the western US to craft extremely scalable, versatile, and resilient cloud architectures. In his spare time, he enjoys spending time together with his household, cooking, and taking part in guitar.
Hans Nesbitt is a Senior Options Architect at AWS primarily based out of Southern California. He works with clients throughout the western US to craft extremely scalable, versatile, and resilient cloud architectures. In his spare time, he enjoys spending time together with his household, cooking, and taking part in guitar.
 Chaoyang He is Co-founder and CTO of FedML, Inc., a startup operating for a neighborhood constructing open and collaborative AI from anyplace at any scale. His analysis focuses on distributed and federated machine studying algorithms, programs, and purposes. He acquired his PhD in Laptop Science from the College of Southern California.
Chaoyang He is Co-founder and CTO of FedML, Inc., a startup operating for a neighborhood constructing open and collaborative AI from anyplace at any scale. His analysis focuses on distributed and federated machine studying algorithms, programs, and purposes. He acquired his PhD in Laptop Science from the College of Southern California.
 Al Nevarez is Director of Product Administration at FedML. Earlier than FedML, he was a bunch product supervisor at Google, and a senior supervisor of knowledge science at LinkedIn. He has a number of information product-related patents, and he studied engineering at Stanford College.
Al Nevarez is Director of Product Administration at FedML. Earlier than FedML, he was a bunch product supervisor at Google, and a senior supervisor of knowledge science at LinkedIn. He has a number of information product-related patents, and he studied engineering at Stanford College.
 Salman Avestimehr is Co-founder and CEO of FedML. He has been a Dean’s Professor at USC, Director of the USC-Amazon Heart on Reliable AI, and an Amazon Scholar in Alexa AI. He’s an professional on federated and decentralized machine studying, data idea, safety, and privateness. He’s a Fellow of IEEE and acquired his PhD in EECS from UC Berkeley.
Salman Avestimehr is Co-founder and CEO of FedML. He has been a Dean’s Professor at USC, Director of the USC-Amazon Heart on Reliable AI, and an Amazon Scholar in Alexa AI. He’s an professional on federated and decentralized machine studying, data idea, safety, and privateness. He’s a Fellow of IEEE and acquired his PhD in EECS from UC Berkeley.
 Samir Lad is an completed enterprise technologist with AWS who works intently with clients’ C-level executives. As a former C-suite government who has pushed transformations throughout a number of Fortune 100 corporations, Samir shares his invaluable experiences to assist his shoppers reach their very own transformation journey.
Samir Lad is an completed enterprise technologist with AWS who works intently with clients’ C-level executives. As a former C-suite government who has pushed transformations throughout a number of Fortune 100 corporations, Samir shares his invaluable experiences to assist his shoppers reach their very own transformation journey.
 Stephen Kraemer is a Board and CxO advisor and former government at AWS. Stephen advocates tradition and management because the foundations of success. He professes safety and innovation the drivers of cloud transformation enabling extremely aggressive, data-driven organizations.
Stephen Kraemer is a Board and CxO advisor and former government at AWS. Stephen advocates tradition and management because the foundations of success. He professes safety and innovation the drivers of cloud transformation enabling extremely aggressive, data-driven organizations.