This AI Paper from China Introduces Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visible-Motional Tokenization
There was a current uptick within the growth of general-purpose multimodal AI assistants able to following visible and written instructions, due to the exceptional success of Giant Language Fashions (LLMs). By using the spectacular reasoning capabilities of LLMs and data present in big alignment corpus (akin to image-text pairs), they exhibit the immense potential for successfully understanding and creating visible content material. Regardless of their success with image-text knowledge, adaptation for video modality is underexplored in these multimodal LLMs. Video is a extra pure match with human visible notion than nonetheless pictures due to its dynamic nature. To enhance AI’s potential to know the actual world, it is extremely vital to be taught from video efficiently.
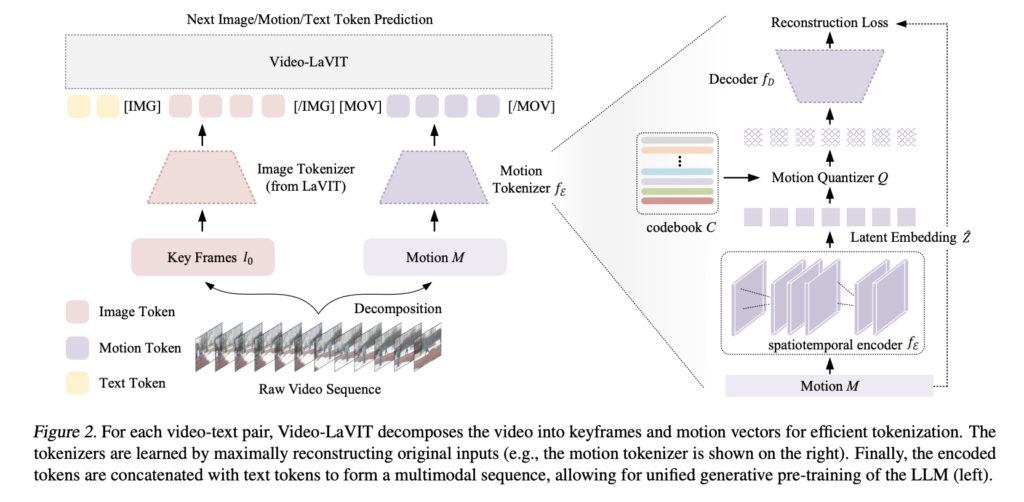
By investigating a time-saving video illustration that breaks down video into keyframes and temporal motions, a brand new research by Peking College and Kuaishou Know-how overcomes the shortcomings of video-language pretraining. Their work is majorly impressed by the inherent qualities of video knowledge that present the premise. Most movies are break up into a number of pictures, and there’s normally a lot redundant data within the video frames inside every shot. Together with these frames within the generative pretraining of LLMs as tokens is pointless.
Keyframes include the principle visible semantics, and movement vectors present the dynamic evolution of their corresponding keyframe over time; this reality strongly motivates us to divide every film into these alternating halves. Such deconstructed illustration has a number of benefits:
- Using movement vectors with a single keyframe is extra environment friendly for large-scale pretraining than processing consecutive video frames utilizing 3D encoders as a result of it requires fewer tokens to precise video temporal dynamics.
- As an alternative of ranging from zero in terms of modeling time, the mannequin can use the visible information it has gained from a pre-made image-only LLM for its personal functions.
For these causes, the workforce has launched Video-LaVIT (Language-VIsion Transformer). This novel multimodal pretraining technique equips LLMs to know and produce video materials inside a cohesive framework. Video-LaVIT has two foremost parts to handle video modalities: a tokenizer and a detokenizer. By using a longtime picture tokenizer to course of the keyframes, the video tokenizer makes an attempt to transform the continual video knowledge right into a sequence of compact discrete tokens much like a overseas language. Encoding spatiotemporal motions might be encoded by remodeling them right into a corresponding discrete illustration. It vastly improves LLMs’ capability to know advanced video actions by capturing the time-varying contextual data in retrieved movement vectors. The video detokenizer restores the unique steady pixel area from which the discretized video token produced by LLMs was initially mapped.
Customers might optimize video throughout coaching utilizing the identical subsequent token prediction goal with totally different modalities for the reason that video is an alternating discrete visual-motion token sequence. This mixed autoregressive pretraining aids in understanding the sequential relationships of assorted video clips, which is vital as a result of video is a time sequence.
As a multimodal generalist, VideoLaVIT confirmed promise in understanding and producing duties even with out further tuning. Outcomes from in depth quantitative and qualitative exams present that Video-LaVIT outperforms the competitors in varied duties, together with text-to-video and picture-to-video manufacturing, video and picture understanding, and extra.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and Google News. Be part of our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our newsletter..
Don’t Overlook to affix our Telegram Channel
Dhanshree Shenwai is a Laptop Science Engineer and has a very good expertise in FinTech corporations masking Monetary, Playing cards & Funds and Banking area with eager curiosity in purposes of AI. She is smitten by exploring new applied sciences and developments in right now’s evolving world making everybody’s life straightforward.