7 Steps to Mastering Exploratory Information Evaluation
Picture by Writer
Exploratory Information Evaluation (or EDA) stands as a core section inside the Information Evaluation Course of, emphasizing an intensive investigation right into a dataset’s interior particulars and traits.
Its major goal is to uncover underlying patterns, grasp the dataset’s construction, and establish any potential anomalies or relationships between variables.
By performing EDA, information professionals examine the standard of the information. Due to this fact, it ensures that additional evaluation is predicated on correct and insightful data, thereby decreasing the probability of errors in subsequent levels.
So let’s attempt to perceive collectively what are the fundamental steps to carry out an excellent EDA for our subsequent Information Science mission.
I’m fairly positive you have got already heard the phrase:
Rubbish in, Rubbish out
Enter information high quality is all the time a very powerful issue for any profitable information mission.
Sadly, most information is grime at first. By the method of Exploratory Information Evaluation, a dataset that’s almost usable might be remodeled into one that’s totally usable.
It is necessary to make clear that it isn’t a magic resolution for purifying any dataset. Nonetheless, quite a few EDA methods are efficient at addressing a number of typical points encountered inside datasets.
So… let’s study essentially the most primary steps in accordance with Ayodele Oluleye in his e book Exploratory Information Evaluation with Python Cookbook.
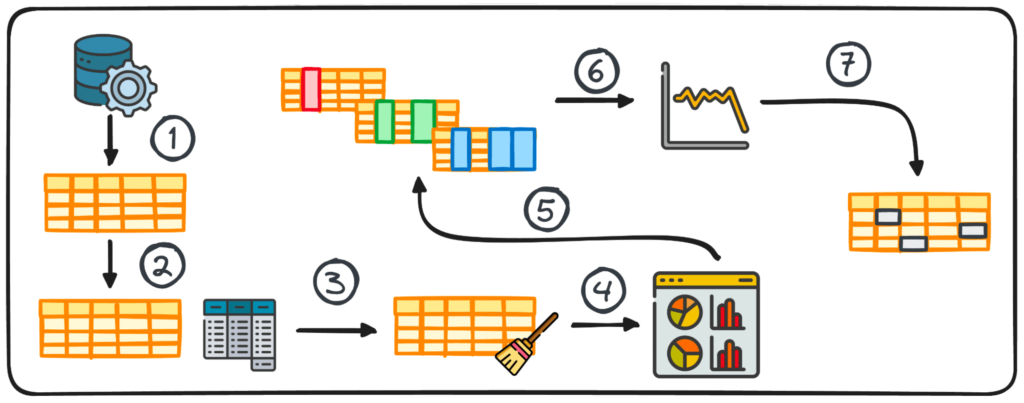
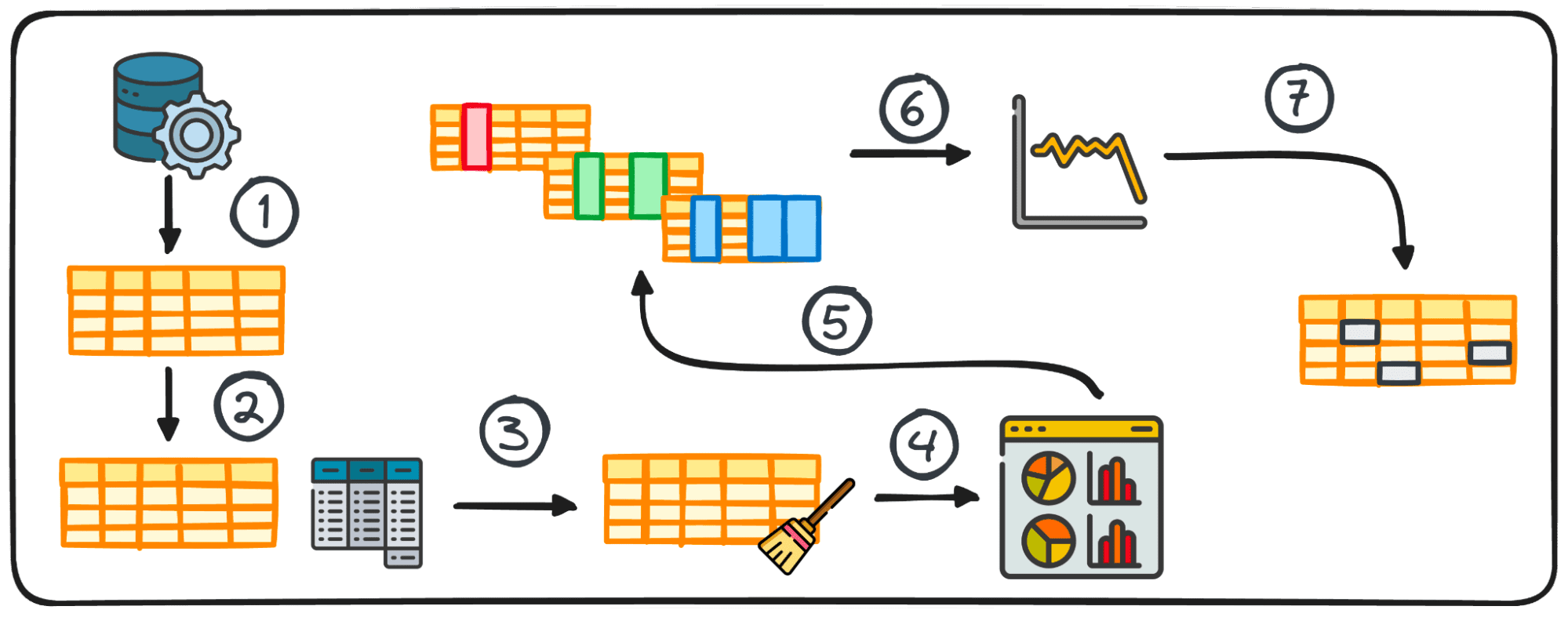
Step 1: Information Assortment
The preliminary step in any information mission is having the information itself. This primary step is the place information is gathered from varied sources for subsequent evaluation.
2. Abstract Statistics
In information evaluation, dealing with tabular information is kind of frequent. Through the evaluation of such information, it is typically crucial to realize speedy insights into the information’s patterns and distribution.
These preliminary insights function a base for additional exploration and in-depth evaluation and are often called abstract statistics.
They provide a concise overview of the dataset’s distribution and patterns, encapsulated by means of metrics resembling imply, median, mode, variance, normal deviation, vary, percentiles, and quartiles.
Picture by Writer
3. Making ready Information for EDA
Earlier than beginning our exploration, information often must be ready for additional evaluation. Information preparation entails reworking, aggregating, or cleansing information utilizing Python’s pandas library to swimsuit the wants of your evaluation.
This step is tailor-made to the information’s construction and might embody grouping, appending, merging, sorting, categorizing, and coping with duplicates.
In Python, engaging in this process is facilitated by the pandas library by means of its varied modules.
The preparation course of for tabular information does not adhere to a common technique; as a substitute, it is formed by the particular traits of our information, together with its rows, columns, information varieties, and the values it accommodates.
4. Visualizing Information
Visualization is a core part of EDA, making complicated relationships and tendencies inside the dataset simply understandable.
Utilizing the correct charts can assist us establish tendencies inside a giant dataset and discover hidden patterns or outliers. Python provides completely different libraries for information visualization, together with Matplotlib or Seaborn amongst others.
Picture by Writer
5. Performing Variable Evaluation:
Variable evaluation might be both univariate, bivariate, or multivariate. Every of them supplies insights into the distribution and correlations between the dataset’s variables. Strategies range relying on the variety of variables analyzed:
Univariate
The principle focus in univariate evaluation is on inspecting every variable inside our dataset by itself. Throughout this evaluation, we are able to uncover insights such because the median, mode, most, vary, and outliers.
Any such evaluation is relevant to each categorical and numerical variables.
Bivariate
Bivariate evaluation goals to disclose insights between two chosen variables and focuses on understanding the distribution and relationship between these two variables.
As we analyze two variables on the similar time, this sort of evaluation might be trickier. It might probably embody three completely different pairs of variables: numerical-numerical, numerical-categorical, and categorical-categorical.
Multivariate
A frequent problem with giant datasets is the simultaneous evaluation of a number of variables. Despite the fact that univariate and bivariate evaluation strategies supply worthwhile insights, that is often not sufficient for analyzing datasets containing a number of variables (often greater than 5).
This concern of managing high-dimensional information, often known as the curse of dimensionality, is well-documented. Having numerous variables might be advantageous because it permits the extraction of extra insights. On the similar time, this benefit might be towards us because of the restricted variety of strategies accessible for analyzing or visualizing a number of variables concurrently.
6. Analyzing Time Sequence Information
This step focuses on the examination of knowledge factors collected over common time intervals. Time collection information applies to information that change over time. This mainly means our dataset consists of a gaggle of knowledge factors which are recorded over common time intervals.
Once we analyze time collection information, we are able to sometimes uncover patterns or tendencies that repeat over time and current a temporal seasonality. Key elements of time collection information embody tendencies, seasonal differences, cyclical variations, and irregular variations or noise.
7. Coping with Outliers and Lacking Values
Outliers and lacking values can skew evaluation outcomes if not correctly addressed. Because of this we should always all the time think about a single section to take care of them.
Figuring out, eradicating, or changing these information factors is essential for sustaining the integrity of the dataset’s evaluation. Due to this fact, it’s extremely necessary to deal with them earlier than begin analyzing our information.
- Outliers are information factors that current a major deviation from the remainder. They often current unusually excessive or low values.
- Lacking values are the absence of knowledge factors equivalent to a particular variable or remark.
A vital preliminary step in coping with lacking values and outliers is to know why they’re current within the dataset. This understanding typically guides the choice of essentially the most appropriate technique for addressing them. Further components to think about are the traits of the information and the particular evaluation that shall be performed.
EDA not solely enhances the dataset’s readability but in addition allows information professionals to navigate the curse of dimensionality by offering methods for managing datasets with quite a few variables.
By these meticulous steps, EDA with Python equips analysts with the instruments essential to extract significant insights from information, laying a stable basis for all subsequent information evaluation endeavors.
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is presently working within the Information Science subject utilized to human mobility. He’s a part-time content material creator centered on information science and expertise. You possibly can contact him on LinkedIn, Twitter or Medium.