Artificial Information for Machine Studying
It’s no secret that supervised machine studying fashions must be skilled on high-quality labeled datasets. Nevertheless, amassing sufficient high-quality labeled information is usually a important problem, particularly in conditions the place privateness and information availability are main issues. Happily, this downside will be mitigated with artificial information. Artificial information is information that’s artificially generated slightly than collected from real-world occasions. This information can both increase actual information or can be utilized instead of actual information. It may be created in a number of methods together with via using statistics, information augmentation/computer-generated imagery (CGI), or generative AI relying on the use case. On this submit, we are going to go over:
- The Worth of Artificial Information
- Artificial Information for Edge Circumstances
- Find out how to Generate Artificial Information
https://youtu.be/PIzDYbATawY?si=Eb9M8aAfgVBym4Ih
Issues with actual information have led to many use instances for artificial information, which you’ll be able to try under.
Privateness points

Picture by Google Research
Healthcare information is broadly recognized to have privateness restrictions. For instance, whereas incorporating digital well being information (EHR) into machine studying purposes might improve affected person outcomes, doing so whereas adhering to affected person privateness rules like HIPAA is troublesome. Even methods to anonymize information aren’t excellent. In response, researchers at Google got here up with EHR-Protected which is a framework for producing reasonable and privacy-preserving artificial EHR.
Security Points
Amassing actual information will be harmful. One of many core issues with robotic purposes like self-driving vehicles is that they’re bodily purposes of machine studying. An unsafe mannequin can’t be deployed in the actual world and causes a crash resulting from a scarcity of related information. Augmenting a dataset with artificial information will help fashions keep away from these issues.
Actual information assortment and labeling are sometimes not scalable
Annotating medical photographs is crucial for coaching machine studying fashions. Nevertheless, every picture must be labeled by professional clinicians, which is a time-consuming and costly course of that’s typically topic to strict privateness rules. Artificial information can handle this by producing massive volumes of labeled photographs with out requiring intensive human annotation or compromising affected person privateness.
Handbook labeling of actual information can generally be very laborious if not unattainable
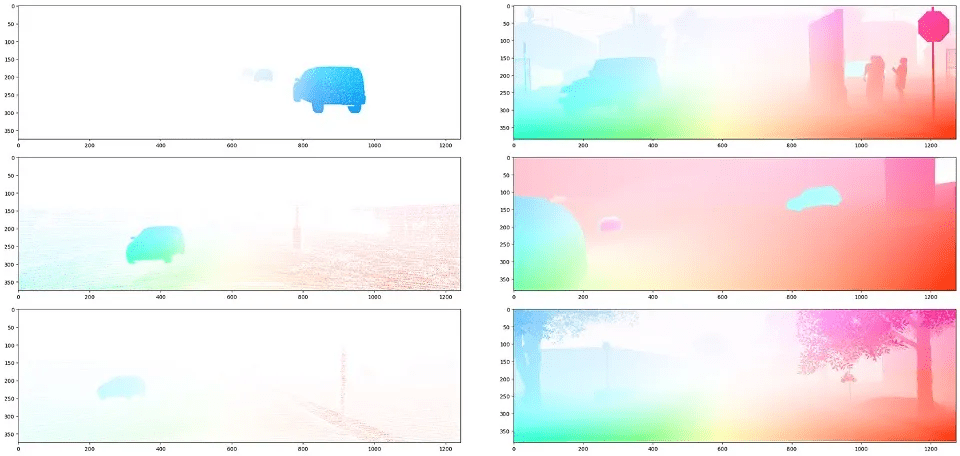
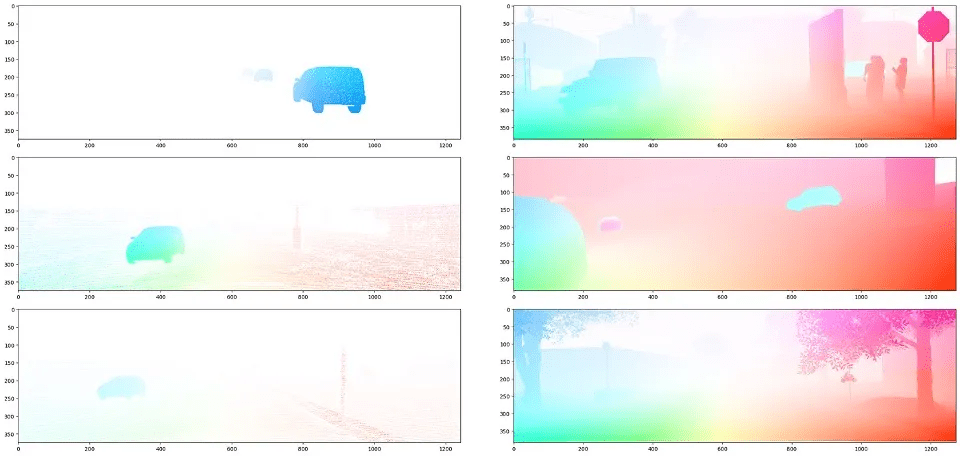
Optical circulation labels of the sparse real-world information KITTI (left) and the artificial information from Parallel Area (proper). The colour signifies the path and magnitude of circulation. Picture by writer.
In self-driving, estimating per-pixel movement between video frames, also referred to as optical circulation, is difficult with real-world information. Actual information labeling can solely be executed utilizing LiDAR info to estimate object movement, whether or not dynamic or static, from the autonomous car’s trajectory. As a result of LiDAR scans are sparse, the only a few public optical circulation datasets are additionally sparse. That is one cause why some optical circulation artificial information has been proven to tremendously enhance efficiency on optical circulation duties.
A standard use case of artificial information is to cope with a scarcity of uncommon lessons and edge instances in actual datasets. Earlier than producing artificial information for this use case, please try the ideas under to contemplate what must be generated and the way a lot of it’s wanted.
Establish your edge instances and uncommon lessons
It is very important perceive what edge instances are contained in a dataset. This might be uncommon illnesses in medical photographs or traditional animals and jaywalkers in self-driving. It is usually essential to contemplate what edge instances are NOT in a dataset. If a mannequin must establish an edge case not current within the dataset, extra information assortment or artificial information era could be vital.
Confirm the artificial information is consultant of the real-world
Artificial information ought to characterize real-world eventualities with minimal area gaps that are variations between two distinct datasets (e.g., actual and artificial information). This may be executed by handbook inspection or by utilizing a separate mannequin skilled on actual information.
Make potential artificial efficiency enhancements quantifiable
A objective of supervised studying is to construct a mannequin that performs properly on new information. That is why there are mannequin validation procedures like train test split. When augmenting an actual dataset with artificial information, information would possibly must be balanced primarily based on uncommon lessons. For instance, in self-driving purposes, a machine studying practitioner could be desirous about utilizing artificial information to concentrate on particular edge instances like jaywalkers. The unique practice check break up could not have been break up by the variety of jaywalkers. On this case, it would make sense to maneuver a whole lot of the present jaywalker samples over to the check set to make sure that enchancment by artificial information is measurable.
Guarantee all your artificial information isn’t just uncommon lessons
A machine studying mannequin shouldn’t be taught that artificial information is usually uncommon lessons and edge instances. Additionally, when extra uncommon lessons and edge instances are found, extra artificial information would possibly must be generated to account for this situation.
A serious power of artificial information is that extra can all the time be generated. It additionally comes with the advantage of already being labeled. There are lots of methods to generate artificial information and which one you select will depend on your use case.
Statistical strategies
A standard statistical methodology is to generate new information primarily based on the distribution and variability of the unique information set. Statistical strategies work greatest when the dataset is comparatively easy and the relationships between variables are properly understood and will be outlined mathematically. For instance, if actual information has a standard distribution like human heights, artificial information will be created utilizing the identical imply and normal deviation of the unique dataset.
Information augmentation/CGI
A standard technique to extend the range and quantity of coaching information is by modifying present information to create artificial information. Information augmentation is broadly utilized in picture processing. This would possibly imply flipping photographs, cropping them, or adjusting brightness. Simply be sure that the information augmentation technique is smart for the mission of curiosity. For instance, for self-driving purposes, rotating a picture by 180 levels in order that the highway is on the prime of the picture and the sky on the backside doesn’t make sense.
https://youtu.be/296k6OHErfM?si=H56aB5hlpEIBtp7c
Caption: Multiformer inference on an city scene from the artificial SHIFT dataset.
Slightly than modifying present information for self-driving purposes, CGI can be utilized to exactly generate all kinds of photographs or movies that may not be simply obtainable within the real-world. This may embody uncommon or harmful eventualities, particular lighting situations, or forms of autos. A few the drawbacks of this strategy are that creating high-quality CGI requires important computational sources. specialised software program, and a talented crew.
Generative AI
A generally used generative mannequin to create artificial information is Generative Adversarial Networks or GANs for brief. GANs encompass two networks, a generator, and a discriminator, which are skilled concurrently. The generator creates new examples, and the discriminator makes an attempt to distinguish between actual and generated examples. The fashions be taught collectively, with the generator enhancing its capability to create reasonable information, and the discriminator changing into extra expert at detecting artificial information. If you want to strive implementing a GAN with PyTorch, check out this TDS blog post.
These strategies work properly for complicated datasets and may generate very reasonable, high-quality information, Nevertheless, because the picture above reveals, it’s not all the time simple to manage particular attributes like the colour, textual content, or measurement of generated objects.
If a mission doesn’t have sufficient high-quality and various actual information, artificial information could be an choice. In spite of everything, extra artificial information can all the time be generated. It is a main distinction between actual and artificial information as artificial information is much simpler to enhance! When you have any questions or ideas on this weblog submit, be at liberty to achieve out within the feedback under or via Twitter.
Michael Galarnyk is a Information Science Skilled, and works in Product Advertising and marketing Content material Lead at Parallel Area.