Researchers from EPFL and Meta AI Proposes Chain-of-Abstraction (CoA): A New Methodology for LLMs to Higher Leverage Instruments in Multi-Step Reasoning
Current developments in giant language fashions (LLMs) have propelled the sector ahead in deciphering and executing directions. Regardless of these strides, LLMs nonetheless grapple with errors in recalling and composing world data, resulting in inaccuracies in responses. To handle this, the mixing of auxiliary instruments, corresponding to utilizing search engines like google or calculators throughout inference, has been proposed to reinforce reasoning. Nevertheless, current tool-augmented LLMs face challenges in effectively leveraging instruments for multi-step reasoning, notably in dealing with interleaved instrument calls and minimizing inference ready occasions.
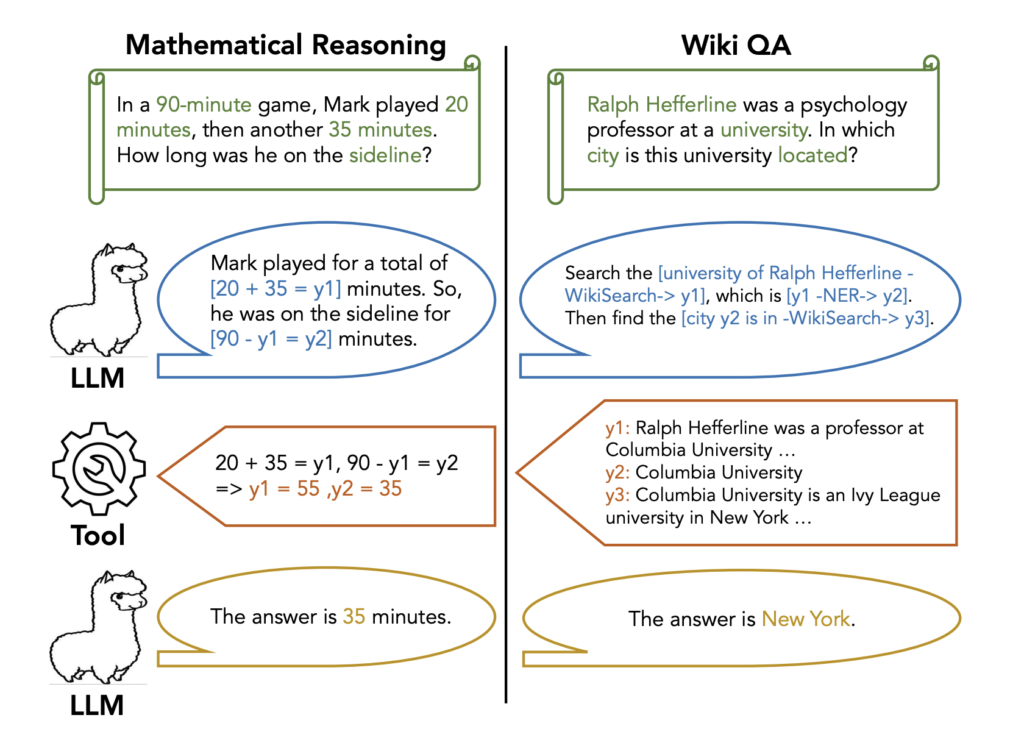
In response to those challenges, this analysis from EPFL and Meta introduces the Chain-of-Abstraction (CoA) reasoning methodology, a sturdy and environment friendly method for LLMs to carry out multi-step reasoning with instruments. The core concept is illustrated in Determine 1, the place LLMs are fine-tuned to create reasoning chains with summary placeholders (e.g., y1, y2, y3). Subsequently, these placeholders are changed with particular data obtained from exterior instruments, corresponding to calculators or net search engines like google, grounding the ultimate reply generations.
Furthermore, not like prior strategies the place LLM decoding and API calls are interleaved, CoA reasoning promotes efficient planning by encouraging LLMs to interconnect a number of instrument calls and undertake extra possible reasoning methods. The summary chain of reasoning permits LLMs to concentrate on basic and holistic reasoning methods with out producing instance-specific data for the mannequin’s parameters. Notably, the decoupling of basic reasoning and domain-specific data permits parallel processing, the place LLMs can generate the subsequent summary chain whereas instruments fill the present chain, thus rushing up the general inference course of.
To coach LLMs for CoA reasoning, the authors assemble fine-tuning information by repurposing current open-source question-answering datasets (Cobbe et al., 2021; Miao et al., 2020; Yang et al., 2018). LLaMa-70B is prompted to re-write solutions as summary chains, changing particular operations with summary placeholders. The ensuing CoA traces are validated utilizing domain-specialized instruments to make sure accuracy.
The CoA methodology is evaluated in two domains: mathematical reasoning and Wikipedia query answering (Wiki QA). For mathematical reasoning, LLMs are skilled on CoA information constructed by re-writing the GSM8K (Cobbe et al., 2021) coaching set. CoA outperforms few-shot and common fine-tuning baselines on each in-distribution and out-of-distribution datasets, showcasing its effectiveness in multi-step reasoning duties. The CoA methodology additionally demonstrates superior efficiency in comparison with the Toolformer baseline.
Within the Wiki QA area, HotpotQA (Yang et al., 2018) is utilized to assemble fine-tuning CoA information. CoA surpasses baselines, together with Toolformer, and achieves exceptional generalization potential on various question-answering datasets (WebQuestions, NaturalQuestions, TriviaQA). Area instruments, corresponding to a Wikipedia search engine and named-entity recognition toolkit, additional improve the efficiency of CoA.
The analysis outcomes throughout each domains point out vital enhancements with the CoA methodology, yielding a median accuracy improve of ∼7.5% and 4.5% for mathematical reasoning and Wiki QA, respectively. These enhancements maintain throughout in-distribution and out-of-distribution check units, notably benefiting questions requiring complicated chain-of-thought reasoning. CoA additionally reveals sooner inference speeds, outpacing earlier augmentation strategies on mathematical reasoning and Wiki QA duties.
In conclusion, The proposed CoA reasoning methodology separates basic reasoning from domain-specific data, fostering extra strong multi-step reasoning in LLMs. Its effectivity in instrument utilization contributes to sooner inference, making it a promising method for various reasoning eventualities. The experiments on mathematical reasoning and Wiki QA underscore the flexibility and efficacy of the CoA methodology, suggesting its potential for broader functions in enhancing LLM efficiency in varied domains.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and Google News. Be part of our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Overlook to affix our Telegram Channel
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Expertise(IIT), Kanpur. He’s a Machine Studying fanatic. He’s obsessed with analysis and the newest developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.





