Construct monetary search purposes utilizing the Amazon Bedrock Cohere multilingual embedding mannequin
Enterprises have entry to huge quantities of knowledge, a lot of which is troublesome to find as a result of the info is unstructured. Typical approaches to analyzing unstructured data use key phrase or synonym matching. They don’t seize the complete context of a doc, making them much less efficient in coping with unstructured information.
In distinction, textual content embeddings use machine learning (ML) capabilities to seize the which means of unstructured information. Embeddings are generated by representational language fashions that translate textual content into numerical vectors and encode contextual data in a doc. This allows purposes resembling semantic search, Retrieval Augmented Generation (RAG), subject modeling, and textual content classification.
For instance, within the monetary providers business, purposes embody extracting insights from earnings reviews, trying to find data from monetary statements, and analyzing sentiment about shares and markets present in monetary information. Textual content embeddings allow business professionals to extract insights from paperwork, reduce errors, and enhance their efficiency.

On this publish, we showcase an software that may search and question throughout monetary information in numerous languages utilizing Cohere’s Embed and Rerank fashions with Amazon Bedrock.
Cohere’s multilingual embedding mannequin
Cohere is a number one enterprise AI platform that builds world-class giant language fashions (LLMs) and LLM-powered options that permit computer systems to go looking, seize which means, and converse in textual content. They supply ease of use and powerful safety and privateness controls.
Cohere’s multilingual embedding model generates vector representations of paperwork for over 100 languages and is obtainable on Amazon Bedrock. This enables AWS prospects to entry it as an API, which eliminates the necessity to handle the underlying infrastructure and ensures that delicate data stays securely managed and guarded.
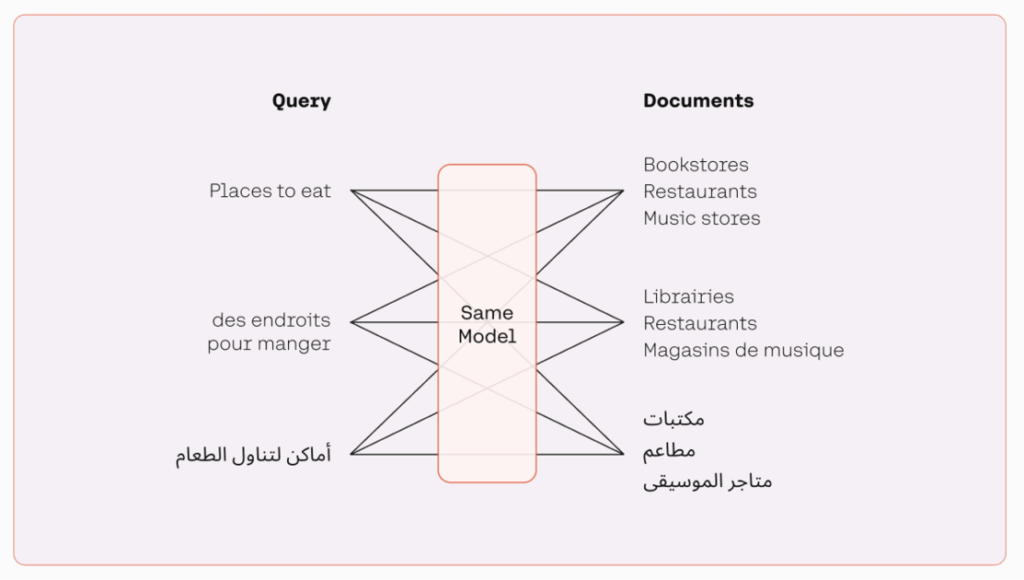
The multilingual mannequin teams textual content with comparable meanings by assigning them positions which are shut to one another in a semantic vector house. With a multilingual embedding mannequin, builders can course of textual content in a number of languages with out the necessity to change between totally different fashions, as illustrated within the following determine. This makes processing extra environment friendly and improves efficiency for multilingual purposes.

The next are a number of the highlights of Cohere’s embedding mannequin:
- Give attention to doc high quality – Typical embedding fashions are skilled to measure similarity between paperwork, however Cohere’s mannequin additionally measures doc high quality
- Higher retrieval for RAG purposes – RAG purposes require retrieval system, which Cohere’s embedding mannequin excels at
- Price-efficient information compression – Cohere makes use of a particular, compression-aware coaching methodology, leading to substantial value financial savings in your vector database
Use circumstances for textual content embedding
Textual content embeddings flip unstructured information right into a structured type. This lets you objectively evaluate, dissect, and derive insights from all of those paperwork. The next are instance use circumstances that Cohere’s embedding mannequin allows:
- Semantic search – Allows highly effective search purposes when coupled with a vector database, with wonderful relevance primarily based on search phrase which means
- Search engine for a bigger system – Finds and retrieves essentially the most related data from linked enterprise information sources for RAG programs
- Textual content classification – Helps intent recognition, sentiment evaluation, and superior doc evaluation
- Subject modeling – Turns a set of paperwork into distinct clusters to uncover rising matters and themes
Enhanced search programs with Rerank
In enterprises the place typical key phrase search programs are already current, how do you introduce fashionable semantic search capabilities? For such programs which have been a part of an organization’s data structure for a very long time, an entire migration to an embeddings-based strategy is, in lots of circumstances, simply not possible.
Cohere’s Rerank endpoint is designed to bridge this hole. It acts because the second stage of a search move to supply a rating of related paperwork per a consumer’s question. Enterprises can retain an current key phrase (and even semantic) system for the first-stage retrieval and increase the standard of search outcomes with the Rerank endpoint within the second-stage reranking.
Rerank gives a quick and simple choice for bettering search outcomes by introducing semantic search expertise right into a consumer’s stack with a single line of code. The endpoint additionally comes with multilingual help. The next determine illustrates the retrieval and reranking workflow.

Resolution overview
Monetary analysts must digest loads of content material, resembling monetary publications and information media, to be able to keep knowledgeable. In response to the Association for Financial Professionals (AFP), monetary analysts spend 75% of their time gathering information or administering the method as an alternative of added-value evaluation. Discovering the reply to a query throughout a wide range of sources and paperwork is time-intensive and tedious work. The Cohere embedding mannequin helps analysts shortly search throughout quite a few article titles in a number of languages to seek out and rank the articles which are most related to a specific question, saving an unlimited quantity of effort and time.
Within the following use case instance, we showcase how Cohere’s Embed mannequin searches and queries throughout monetary information in numerous languages in a single distinctive pipeline. Then we exhibit how including Rerank to your embeddings retrieval (or including it to a legacy lexical search) can additional enhance outcomes.
The supporting pocket book is obtainable on GitHub.
The next diagram illustrates the workflow of the applying.

Allow mannequin entry by means of Amazon Bedrock
Amazon Bedrock customers must request entry to fashions to make them obtainable to be used. To request entry to further fashions, select Mannequin entry the navigation pane on the Amazon Bedrock console. For extra data, see Model access. For this walkthrough, it’s good to request entry to the Cohere Embed Multilingual mannequin.

Set up packages and import modules
First, we set up the mandatory packages and import the modules we’ll use on this instance:
Import paperwork
We use a dataset (MultiFIN) containing a listing of real-world article headlines protecting 15 languages (English, Turkish, Danish, Spanish, Polish, Greek, Finnish, Hebrew, Japanese, Hungarian, Norwegian, Russian, Italian, Icelandic, and Swedish). That is an open supply dataset curated for monetary pure language processing (NLP) and is obtainable on a GitHub repository.
In our case, we’ve created a CSV file with MultiFIN’s information in addition to a column with translations. We don’t use this column to feed the mannequin; we use it to assist us observe alongside after we print the outcomes for individuals who don’t converse Danish or Spanish. We level to that CSV to create our dataframe:

Choose a listing of paperwork to question
MultiFIN has over 6,000 information in 15 totally different languages. For our instance use case, we give attention to three languages: English, Spanish, and Danish. We additionally type the headers by size and choose the longest ones.
As a result of we’re selecting the longest articles, we make sure the size shouldn’t be as a result of repeated sequences. The next code reveals an instance the place that’s the case. We’ll clear that up.
df['text'].iloc[2215]
Our record of paperwork is properly distributed throughout the three languages:
The next is the longest article header in our dataset:
Embed and index paperwork
Now, we wish to embed our paperwork and retailer the embeddings. The embeddings are very giant vectors that encapsulate the semantic which means of our doc. Particularly, we use Cohere’s embed-multilingual-v3.0 mannequin, which creates embeddings with 1,024 dimensions.
When a question is handed, we additionally embed the question and use the hnswlib library to seek out the closest neighbors.
It solely takes just a few traces of code to determine a Cohere shopper, embed the paperwork, and create the search index. We additionally hold observe of the language and translation of the doc to complement the show of the outcomes.
Construct a retrieval system
Subsequent, we construct a operate that takes a question as enter, embeds it, and finds the 4 headers extra carefully associated to it:
Question the retrieval system
Let’s discover what our system does with a few totally different queries. We begin with English:
The outcomes are as follows:
Discover the next:
- We’re asking associated, however barely totally different questions, and the mannequin is nuanced sufficient to current essentially the most related outcomes on the prime.
- Our mannequin doesn’t carry out keyword-based search, however semantic search. Even when we’re utilizing a time period like “information science” as an alternative of “AI,” our mannequin is ready to perceive what’s being requested and return essentially the most related consequence on the prime.
How a few question in Danish? Let’s take a look at the next question:
Within the previous instance, the English acronym “PP&E” stands for “property, plant, and tools,” and our mannequin was in a position to join it to our question.
On this case, all returned outcomes are in Danish, however the mannequin can return a doc in a language apart from the question if its semantic which means is nearer. We’ve full flexibility, and with just a few traces of code, we are able to specify whether or not the mannequin ought to solely take a look at paperwork within the language of the question, or whether or not it ought to take a look at all paperwork.
Enhance outcomes with Cohere Rerank
Embeddings are very highly effective. Nevertheless, we’re now going to take a look at how one can refine our outcomes even additional with Cohere’s Rerank endpoint, which has been skilled to attain the relevancy of paperwork in opposition to a question.
One other benefit of Rerank is that it will probably work on prime of a legacy key phrase search engine. You don’t have to vary to a vector database or make drastic modifications to your infrastructure, and it solely takes just a few traces of code. Rerank is obtainable in Amazon SageMaker.
Let’s strive a brand new question. We use SageMaker this time:
On this case, a semantic search was in a position to retrieve our reply and show it within the outcomes, but it surely’s not on the prime. Nevertheless, after we cross the question once more to our Rerank endpoint with the record of docs retrieved, Rerank is ready to floor essentially the most related doc on the prime.
First, we create the shopper and the Rerank endpoint:
After we cross the paperwork to Rerank, the mannequin is ready to choose essentially the most related one precisely:
Conclusion
This publish offered a walkthrough of utilizing Cohere’s multilingual embedding mannequin in Amazon Bedrock within the monetary providers area. Particularly, we demonstrated an instance of a multilingual monetary articles search software. We noticed how the embedding mannequin allows environment friendly and correct discovery of data, thereby boosting the productiveness and output high quality of an analyst.
Cohere’s multilingual embedding mannequin helps over 100 languages. It removes the complexity of constructing purposes that require working with a corpus of paperwork in numerous languages. The Cohere Embed model is skilled to ship ends in real-world purposes. It handles noisy information as inputs, adapts to advanced RAG programs, and delivers cost-efficiency from its compression-aware coaching methodology.
Begin constructing with Cohere’s multilingual embedding mannequin in Amazon Bedrock at this time.
Concerning the Authors
 James Yi is a Senior AI/ML Companion Options Architect within the Expertise Companions COE Tech group at Amazon Internet Companies. He’s captivated with working with enterprise prospects and companions to design, deploy, and scale AI/ML purposes to derive enterprise worth. Exterior of labor, he enjoys enjoying soccer, touring, and spending time together with his household.
James Yi is a Senior AI/ML Companion Options Architect within the Expertise Companions COE Tech group at Amazon Internet Companies. He’s captivated with working with enterprise prospects and companions to design, deploy, and scale AI/ML purposes to derive enterprise worth. Exterior of labor, he enjoys enjoying soccer, touring, and spending time together with his household.
 Gonzalo Betegon is a Options Architect at Cohere, a supplier of cutting-edge pure language processing expertise. He helps organizations deal with their enterprise wants by means of the deployment of huge language fashions.
Gonzalo Betegon is a Options Architect at Cohere, a supplier of cutting-edge pure language processing expertise. He helps organizations deal with their enterprise wants by means of the deployment of huge language fashions.
 Meor Amer is a Developer Advocate at Cohere, a supplier of cutting-edge pure language processing (NLP) expertise. He helps builders construct cutting-edge purposes with Cohere’s Giant Language Fashions (LLMs).
Meor Amer is a Developer Advocate at Cohere, a supplier of cutting-edge pure language processing (NLP) expertise. He helps builders construct cutting-edge purposes with Cohere’s Giant Language Fashions (LLMs).





