Researchers from UCSD and NYU Launched the SEAL MLLM framework: That includes the LLM-Guided Visible Search Algorithm V ∗ for Correct Visible Grounding in Excessive-Decision Photographs
The main focus has shifted in direction of multimodal Massive Language Fashions (MLLMs), notably in enhancing their processing and integrating multi-sensory information within the evolution of AI. This development is essential in mimicking human-like cognitive talents for advanced real-world interactions, particularly when coping with wealthy visible inputs.
A key problem within the present MLLMs is their want for high-resolution and visually dense pictures. These fashions usually rely on pre-trained imaginative and prescient encoders, constrained by low-resolution coaching, resulting in a big lack of essential visible particulars. This limitation hinders their skill to offer exact visible grounding, which is crucial for advanced job execution.
MLLMs have adopted two major approaches earlier. Some join a pre-trained language mannequin with a imaginative and prescient encoder, projecting visible options into the language mannequin’s enter area. Others deal with the language mannequin as a software, accessing varied imaginative and prescient professional techniques to carry out vision-language duties. Nevertheless, each strategies undergo from vital drawbacks, comparable to data loss and inaccuracy, primarily when coping with detailed visible information.
Researchers from UC San Diego and New York College have developed SEAL (Show, sEArch, and telL), a framework that introduces an LLM-guided visible search mechanism into MLLMs. This strategy considerably enhances MLLMs’ capabilities to establish and course of vital visible data. SEAL contains a Visible Query Answering Language Mannequin and a Visible Search Mannequin. It leverages the in depth world information embedded in language fashions to establish and find particular visible components inside high-resolution pictures. As soon as these components are discovered, they’re integrated right into a Visible Working Reminiscence. This integration permits for a extra correct and contextually knowledgeable response technology, overcoming the restrictions confronted by conventional MLLMs.
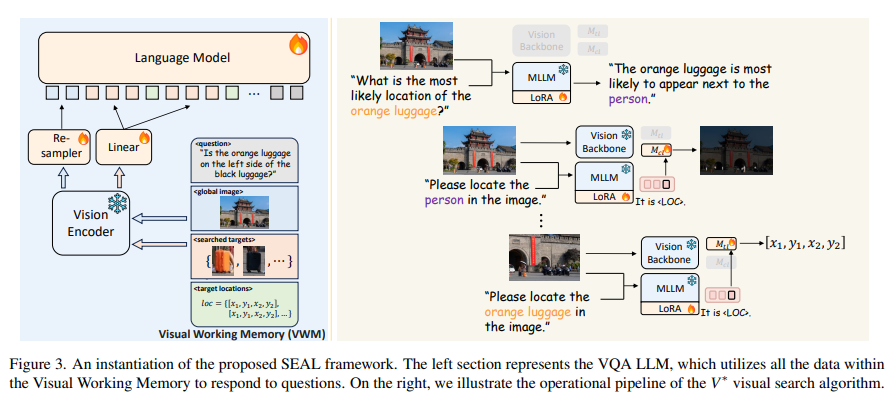
The efficacy of the SEAL framework, notably its visible search algorithm, is obvious in its efficiency. In comparison with present fashions, SEAL reveals a marked enchancment in detailed graphical evaluation. It efficiently addresses the shortcomings of present MLLMs by precisely grounding visible data in advanced pictures. The visible search algorithm enhances the MLLMs’ skill to give attention to important visible particulars, a elementary human cognition mechanism missing in AI fashions. By incorporating these capabilities, SEAL units a brand new customary within the subject, demonstrating a big leap ahead in multimodal reasoning and processing.

In conclusion, introducing the SEAL framework and its visible search algorithm marks a big milestone in MLLM improvement. Key takeaways from this analysis embody:
- SEAL’s integration of an LLM-guided visible search mechanism basically enhances MLLM’s processing of high-resolution pictures.
- The framework’s skill to actively search and course of visible data results in extra correct and contextually related responses.
- Regardless of its developments, there stays room for additional enchancment in architectural design and utility throughout totally different visible content material sorts.
- Future developments may give attention to extending SEAL’s utility to doc and diagram pictures, long-form movies, or open-world environments.
Take a look at the Paper, Project, and Github. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter. Be a part of our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Whats up, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m captivated with know-how and wish to create new merchandise that make a distinction.






