Producing worth from enterprise knowledge: Finest practices for Text2SQL and generative AI
Generative AI has opened up loads of potential within the area of AI. We’re seeing quite a few makes use of, together with textual content technology, code technology, summarization, translation, chatbots, and extra. One such space that’s evolving is utilizing pure language processing (NLP) to unlock new alternatives for accessing knowledge by intuitive SQL queries. As an alternative of coping with complicated technical code, enterprise customers and knowledge analysts can ask questions associated to knowledge and insights in plain language. The first purpose is to routinely generate SQL queries from pure language textual content. To do that, the textual content enter is remodeled right into a structured illustration, and from this illustration, a SQL question that can be utilized to entry a database is created.
On this put up, we offer an introduction to textual content to SQL (Text2SQL) and discover use circumstances, challenges, design patterns, and greatest practices. Particularly, we talk about the next:
- Why do we’d like Text2SQL
- Key elements for Textual content to SQL
- Immediate engineering concerns for pure language or Textual content to SQL
- Optimizations and greatest practices
- Structure patterns
Why do we’d like Text2SQL?
At present, a considerable amount of knowledge is on the market in conventional knowledge analytics, knowledge warehousing, and databases, which can be not straightforward to question or perceive for almost all of group members. The first purpose of Text2SQL is to make querying databases extra accessible to non-technical customers, who can present their queries in pure language.
NLP SQL permits enterprise customers to research knowledge and get solutions by typing or talking questions in pure language, equivalent to the next:
- “Present complete gross sales for every product final month”
- “Which merchandise generated extra income?”
- “What share of shoppers are from every area?”
Amazon Bedrock is a completely managed service that provides a selection of high-performing basis fashions (FMs) by way of a single API, enabling to simply construct and scale Gen AI purposes. It may be leveraged to generate SQL queries primarily based on questions much like those listed above and question organizational structured knowledge and generate pure language responses from the question response knowledge.
Key elements for textual content to SQL
Textual content-to-SQL techniques contain a number of phases to transform pure language queries into runnable SQL:
- Pure language processing:
- Analyze the person’s enter question
- Extract key components and intent
- Convert to a structured format
- SQL technology:
- Map extracted particulars into SQL syntax
- Generate a sound SQL question
- Database question:
- Run the AI-generated SQL question on the database
- Retrieve outcomes
- Return outcomes to the person
One exceptional functionality of Massive Language Fashions (LLMs) is technology of code, together with Structured Question Language (SQL) for databases. These LLMs could be leveraged to know the pure language query and generate a corresponding SQL question as an output. The LLMs will profit by adopting in-context studying and fine-tuning settings as extra knowledge is supplied.
The next diagram illustrates a fundamental Text2SQL circulation.

Immediate engineering concerns for pure language to SQL
The immediate is essential when utilizing LLMs to translate pure language into SQL queries, and there are a number of essential concerns for immediate engineering.
Efficient prompt engineering is essential to creating pure language to SQL techniques. Clear, easy prompts present higher directions for the language mannequin. Offering context that the person is requesting a SQL question together with related database schema particulars permits the mannequin to translate the intent precisely. Together with a number of annotated examples of pure language prompts and corresponding SQL queries helps information the mannequin to provide syntax-compliant output. Moreover, incorporating Retrieval Augmented Era (RAG), the place the mannequin retrieves related examples throughout processing, additional improves the mapping accuracy. Effectively-designed prompts that give the mannequin adequate instruction, context, examples, and retrieval augmentation are essential for reliably translating pure language into SQL queries.
The next is an instance of a baseline immediate with code illustration of the database from the whitepaper Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies.
As illustrated on this instance, prompt-based few-shot studying offers the mannequin with a handful of annotated examples within the immediate itself. This demonstrates the goal mapping between pure language and SQL for the mannequin. Sometimes, the immediate would comprise round 2–3 pairs displaying a pure language question and the equal SQL assertion. These few examples information the mannequin to generate syntax-compliant SQL queries from pure language with out requiring in depth coaching knowledge.
High quality-tuning vs. immediate engineering
When constructing pure language to SQL techniques, we frequently get into the dialogue of if fine-tuning the mannequin is the fitting method or if efficient immediate engineering is the best way to go. Each approaches might be thought-about and chosen primarily based on the fitting set of necessities:
-
- High quality-tuning – The baseline mannequin is pre-trained on a big normal textual content corpus after which can use instruction-based fine-tuning, which makes use of labeled examples to enhance the efficiency of a pre-trained basis mannequin on text-SQL. This adapts the mannequin to the goal process. High quality-tuning immediately trains the mannequin on the top process however requires many text-SQL examples. You need to use supervised fine-tuning primarily based in your LLM to enhance the effectiveness of text-to-SQL. For this, you should use a number of datasets like Spider, WikiSQL, CHASE, BIRD-SQL, or CoSQL.
- Immediate engineering – The mannequin is educated to finish prompts designed to immediate the goal SQL syntax. When producing SQL from pure language utilizing LLMs, offering clear directions within the immediate is essential for controlling the mannequin’s output. Within the immediate to annotate completely different elements like pointing to columns, schema after which instruct which kind of SQL to create. These act like directions that inform the mannequin format the SQL output. The next immediate reveals an instance the place you level desk columns and instruct to create a MySQL question:
An efficient strategy for text-to-SQL fashions is to first begin with a baseline LLM with none task-specific fine-tuning. Effectively-crafted prompts can then be used to adapt and drive the bottom mannequin to deal with the text-to-SQL mapping. This immediate engineering lets you develop the aptitude without having to do fine-tuning. If immediate engineering on the bottom mannequin doesn’t obtain adequate accuracy, fine-tuning on a small set of text-SQL examples can then be explored together with additional immediate engineering.
The mixture of fine-tuning and immediate engineering could also be required if immediate engineering on the uncooked pre-trained mannequin alone doesn’t meet necessities. Nonetheless, it’s greatest to initially try immediate engineering with out fine-tuning, as a result of this enables fast iteration with out knowledge assortment. If this fails to offer satisfactory efficiency, fine-tuning alongside immediate engineering is a viable subsequent step. This general strategy maximizes effectivity whereas nonetheless permitting customization if purely prompt-based strategies are inadequate.
Optimization and greatest practices
Optimization and greatest practices are important for enhancing effectiveness and guaranteeing sources are used optimally and the fitting outcomes are achieved in one of the best ways potential. The strategies assist in enhancing efficiency, controlling prices, and attaining a better-quality final result.
When creating text-to-SQL techniques utilizing LLMs, optimization strategies can enhance efficiency and effectivity. The next are some key areas to contemplate:
- Caching – To enhance latency, value management, and standardization, you may cache the parsed SQL and acknowledged question prompts from the text-to-SQL LLM. This avoids reprocessing repeated queries.
- Monitoring – Logs and metrics round question parsing, immediate recognition, SQL technology, and SQL outcomes needs to be collected to observe the text-to-SQL LLM system. This offers visibility for the optimization instance updating the immediate or revisiting the fine-tuning with an up to date dataset.
- Materialized views vs. tables – Materialized views can simplify SQL technology and enhance efficiency for widespread text-to-SQL queries. Querying tables immediately could lead to complicated SQL and likewise lead to efficiency points, together with fixed creation of efficiency strategies like indexes. Moreover, you may keep away from efficiency points when the identical desk is used for different areas of utility on the identical time.
- Refreshing knowledge – Materialized views should be refreshed on a schedule to maintain knowledge present for text-to-SQL queries. You need to use batch or incremental refresh approaches to steadiness overhead.
- Central knowledge catalog – Making a centralized knowledge catalog offers a single pane of glass view to a corporation’s knowledge sources and can assist LLMs choose acceptable tables and schemas with a purpose to present extra correct responses. Vector embeddings created from a central knowledge catalog could be equipped to an LLM together with data requested to generate related and exact SQL responses.
By making use of optimization greatest practices like caching, monitoring, materialized views, scheduled refreshing, and a central catalog, you may considerably enhance the efficiency and effectivity of text-to-SQL techniques utilizing LLMs.
Structure patterns
Let’s have a look at some structure patterns that may be carried out for a textual content to SQL workflow.
Immediate engineering
The next diagram illustrates the structure for producing queries with an LLM utilizing immediate engineering.

On this sample, the person creates prompt-based few-shot studying that gives the mannequin with annotated examples within the immediate itself, which incorporates the desk and schema particulars and a few pattern queries with its outcomes. The LLM makes use of the supplied immediate to return again the AI-generated SQL, which is validated after which run towards the database to get the outcomes. That is probably the most easy sample to get began utilizing immediate engineering. For this, you should use Amazon Bedrock or foundation models in Amazon SageMaker JumpStart.
On this sample, the person creates a prompt-based few-shot studying that gives the mannequin with annotated examples within the immediate itself, which incorporates the desk and schema particulars and a few pattern queries with its outcomes. The LLM makes use of the supplied immediate to return again the AI generated SQL which is validated and run towards the database to get the outcomes. That is probably the most easy sample to get began utilizing immediate engineering. For this, you should use Amazon Bedrock which is a completely managed service that provides a selection of high-performing basis fashions (FMs) from main AI firms by way of a single API, together with a broad set of capabilities it’s essential to construct generative AI purposes with safety, privateness, and accountable AI or JumpStart Foundation Models which gives state-of-the-art basis fashions to be used circumstances equivalent to content material writing, code technology, query answering, copywriting, summarization, classification, data retrieval, and extra
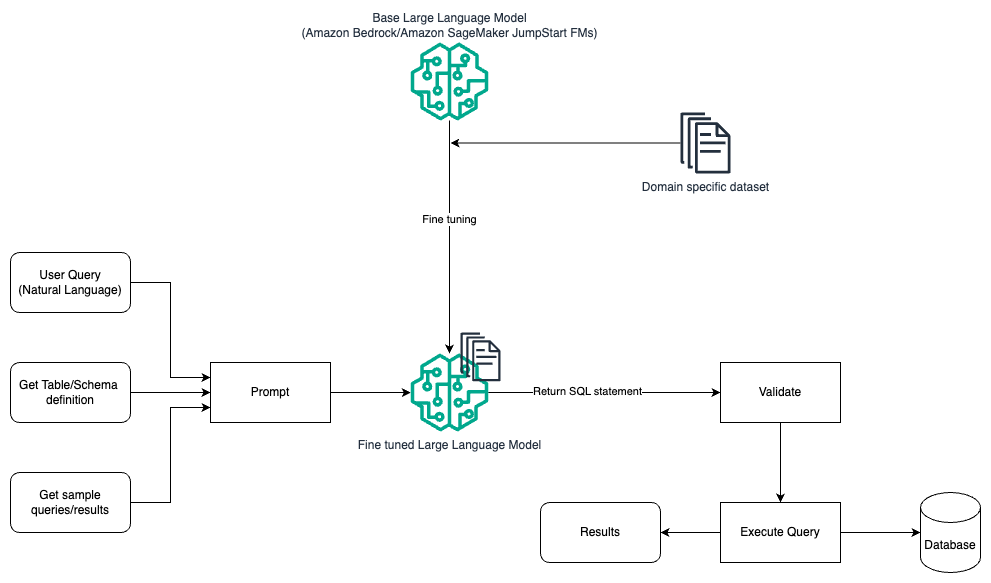
Immediate engineering and fine-tuning
The next diagram illustrates the structure for producing queries with an LLM utilizing immediate engineering and fine-tuning.

This circulation is much like the earlier sample, which principally depends on immediate engineering, however with a further circulation of fine-tuning on the domain-specific dataset. The fine-tuned LLM is used to generate the SQL queries with minimal in-context worth for the immediate. For this, you should use SageMaker JumpStart to fine-tune an LLM on a domain-specific dataset in the identical approach you’ll prepare and deploy any mannequin on Amazon SageMaker.
Immediate engineering and RAG
The next diagram illustrates the structure for producing queries with an LLM utilizing immediate engineering and RAG.

On this sample, we use Retrieval Augmented Generation utilizing vector embeddings shops, like Amazon Titan Embeddings or Cohere Embed, on Amazon Bedrock from a central knowledge catalog, like AWS Glue Data Catalog, of databases inside a corporation. The vector embeddings are saved in vector databases like Vector Engine for Amazon OpenSearch Serverless, Amazon Relational Database Service (Amazon RDS) for PostgreSQL with the pgvector extension, or Amazon Kendra. LLMs use the vector embeddings to pick out the fitting database, tables, and columns from tables sooner when creating SQL queries. Utilizing RAG is useful when knowledge and related data that should be retrieved by LLMs are saved in a number of separate database techniques and the LLM wants to have the ability to search or question knowledge from all these completely different techniques. That is the place offering vector embeddings of a centralized or unified knowledge catalog to the LLMs ends in extra correct and complete data returned by the LLMs.
Conclusion
On this put up, we mentioned how we will generate worth from enterprise knowledge utilizing pure language to SQL technology. We seemed into key elements, optimization, and greatest practices. We additionally realized structure patterns from fundamental immediate engineering to fine-tuning and RAG. To study extra, check with Amazon Bedrock to simply construct and scale generative AI purposes with basis fashions
In regards to the Authors
 Randy DeFauw is a Senior Principal Options Architect at AWS. He holds an MSEE from the College of Michigan, the place he labored on laptop imaginative and prescient for autonomous autos. He additionally holds an MBA from Colorado State College. Randy has held quite a lot of positions within the know-how area, starting from software program engineering to product administration. In entered the Huge Knowledge area in 2013 and continues to discover that space. He’s actively engaged on tasks within the ML area and has introduced at quite a few conferences together with Strata and GlueCon.
Randy DeFauw is a Senior Principal Options Architect at AWS. He holds an MSEE from the College of Michigan, the place he labored on laptop imaginative and prescient for autonomous autos. He additionally holds an MBA from Colorado State College. Randy has held quite a lot of positions within the know-how area, starting from software program engineering to product administration. In entered the Huge Knowledge area in 2013 and continues to discover that space. He’s actively engaged on tasks within the ML area and has introduced at quite a few conferences together with Strata and GlueCon.
 Nitin Eusebius is a Sr. Enterprise Options Architect at AWS, skilled in Software program Engineering, Enterprise Structure, and AI/ML. He’s deeply captivated with exploring the probabilities of generative AI. He collaborates with prospects to assist them construct well-architected purposes on the AWS platform, and is devoted to fixing know-how challenges and aiding with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Options Architect at AWS, skilled in Software program Engineering, Enterprise Structure, and AI/ML. He’s deeply captivated with exploring the probabilities of generative AI. He collaborates with prospects to assist them construct well-architected purposes on the AWS platform, and is devoted to fixing know-how challenges and aiding with their cloud journey.
 Arghya Banerjee is a Sr. Options Architect at AWS within the San Francisco Bay Space targeted on serving to prospects undertake and use AWS Cloud. Arghya is concentrated on Huge Knowledge, Knowledge Lakes, Streaming, Batch Analytics and AI/ML companies and applied sciences.
Arghya Banerjee is a Sr. Options Architect at AWS within the San Francisco Bay Space targeted on serving to prospects undertake and use AWS Cloud. Arghya is concentrated on Huge Knowledge, Knowledge Lakes, Streaming, Batch Analytics and AI/ML companies and applied sciences.






