EPFL and Apple Researchers Open-Sources 4M: An Synthetic Intelligence Framework for Coaching Multimodal Basis Fashions Throughout Tens of Modalities and Duties
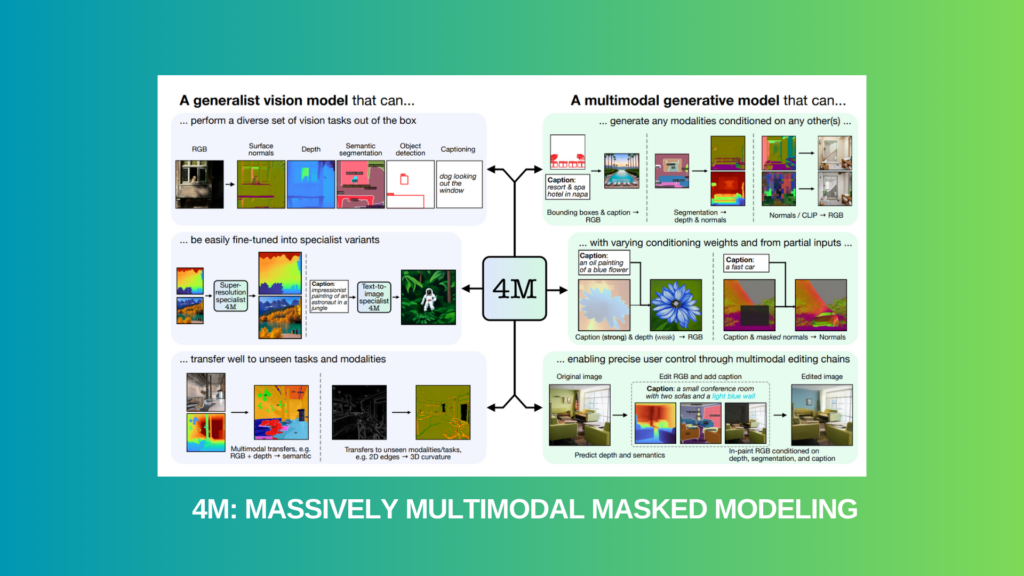
Coaching massive language fashions (LLMs) that may naturally deal with varied duties with out intensive task-specific changes has develop into extra fashionable in pure language processing (NLP). There’s nonetheless a have to create equally versatile and scalable fashions for imaginative and prescient, although these fashions have proven excellent success in NLP. The capability to handle many enter modalities and output duties is crucial for imaginative and prescient’s scalability and flexibility.
Imaginative and prescient fashions should deal with varied sensory inputs, together with photos, 3D, and textual content, and carry out varied duties. Concerning imaginative and prescient, coaching on RGB photographs with a single function has not produced the identical outcomes as language modeling on uncooked textual content, which has led to multitasking capabilities in pure language processing. Because of this, coaching ought to make use of a wide range of modalities and duties.
Knowledge, structure, and coaching function are three important scalability elements to think about whereas constructing a mannequin with the fascinating imaginative and prescient basis mannequin attributes. Knowledge scalability refers back to the capability to leverage extra coaching samples to boost efficiency. In architectural phrases, scalability signifies that efficiency improves with growing mannequin dimension and stays steady when educated at enormous sizes. Lastly, a scalable coaching purpose ought to be capable to effectively take care of an growing variety of modalities with out inflicting the computational prices to skyrocket.
New analysis by the Swiss Federal Institute of Expertise Lausanne (EPFL) and Apple goals for scalability in all three areas whereas being suitable with totally different enter sorts.
To beat these obstacles, the group presents a method that entails coaching a single built-in Transformer encoder-decoder with a multimodal masked modeling purpose. 4M stands for “Massively Multimodal Masked Modeling,” highlighting the method’s capability to develop to a number of diverse modalities. This method combines one of the best options of masked modeling and multimodal studying:
- Sturdy cross-modal predictive coding skills and shared scene representations,
- Iterative sampling permits fashions for use for generative duties.
- The pre-training goal is to successfully study wealthy representations.
Importantly, 4M integrates these benefits whereas sustaining effectivity by way of many processes. Via using modality-specific tokenizers, modalities could also be transformed with numerous codecs into units or sequences of discrete tokens, permitting a single Transformer to be educated on textual content, bounding bins, photos, or neural community options, amongst others. This unifies their representational domains. Since task-specific encoders and heads are not crucial, the Transformer can be utilized with any modality and retain full parameter-sharing due to this tokenization method, enhancing compatibility, scalability, and sharing.
Moreover, 4M can practice effectively by using enter and goal masking, although it operates on an unlimited assortment of modalities. This requires selecting a small subset of tokens randomly from all modalities to make use of as mannequin inputs and one other small subset as targets. To attain a scalable coaching purpose, decoupling the variety of enter and goal tokens from the variety of modalities is critical. This prevents the computational value from shortly growing because the variety of modalities will increase. Utilizing CC12M and different obtainable single-modal or text-image pair datasets, they create modally aligned binding knowledge utilizing highly effective pseudo-labeling networks.
With out requiring them to incorporate multimodal/multitask annotations, this pseudo-labeling technique permits coaching on totally different and large-scale datasets. Along with excelling at quite a few necessary visible duties proper out of the gate, 4M fashions might be fine-tuned to attain outstanding outcomes on unexpected downstream duties and enter modalities.
Moreover, one should make the most of a multimodal masked modeling purpose to coach steerable generative fashions that may be conditioned on any modality. This enables for numerous expression of consumer intent and varied multimodal enhancing duties. The parameters impacting 4M’s efficiency are then studied in an intensive ablation evaluation. This complete evaluation, together with the convenience and generalizability of this technique, proves that 4M has nice promise for a lot of imaginative and prescient duties and future developments.
Take a look at the Paper and Project. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to hitch our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
Dhanshree Shenwai is a Pc Science Engineer and has expertise in FinTech corporations masking Monetary, Playing cards & Funds and Banking area with eager curiosity in purposes of AI. She is obsessed with exploring new applied sciences and developments in right now’s evolving world making everybody’s life straightforward.





