Methods for automated summarization of paperwork utilizing language fashions
Summarization is the strategy of condensing sizable data right into a compact and significant type, and stands as a cornerstone of environment friendly communication in our information-rich age. In a world full of information, summarizing lengthy texts into temporary summaries saves time and helps make knowledgeable selections. Summarization condenses content material, saving time and enhancing readability by presenting data concisely and coherently. Summarization is invaluable for decision-making and in managing giant volumes of content material.
Summarization strategies have a broad vary of purposes serving numerous functions, reminiscent of:
- Information aggregation – News aggregation includes summarizing information articles right into a e-newsletter for the media trade
- Authorized doc summarization – Legal document summarization helps authorized professionals extract key authorized data from prolonged paperwork like phrases, circumstances, and contracts
- Educational analysis – Summarization annotates, indexes, condenses, and simplifies essential data from tutorial papers
- Content material curation for blogs and web sites – You possibly can create participating and authentic content material summaries for readers, particularly in advertising
- Monetary experiences and market evaluation – You possibly can extract financial insights from experiences and create government summaries for investor shows within the finance trade
With the developments in pure language processing (NLP), language fashions, and generative AI, summarizing texts of various lengths has turn into extra accessible. Instruments like LangChain, mixed with a big language mannequin (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart, simplify the implementation course of.
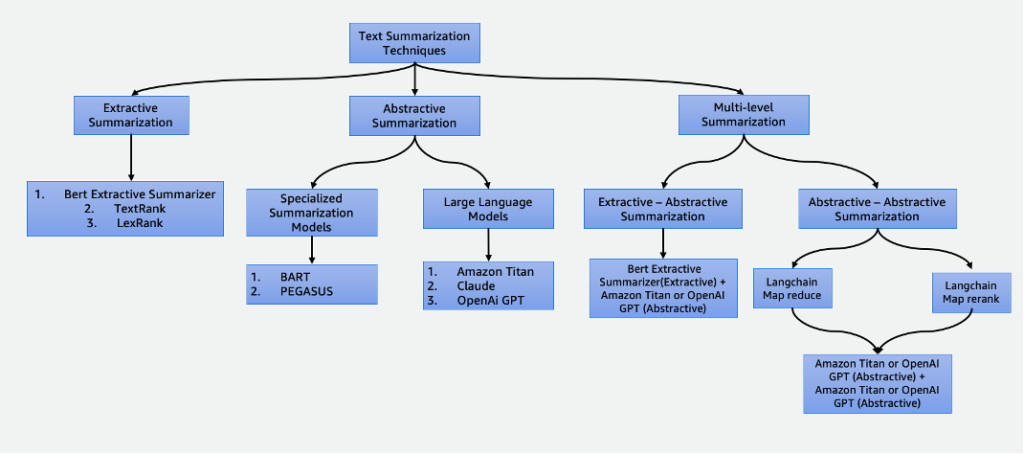
This put up delves into the next summarization strategies:
- Extractive summarization utilizing the BERT extractive summarizer
- Abstractive summarization utilizing specialised summarization fashions and LLMs
- Two multi-level summarization strategies:
- Extractive-abstractive summarization utilizing the extractive-abstractive content material summarization technique (EACSS)
- Abstractive-abstractive summarization utilizing Map Cut back and Map ReRank

The entire code pattern is discovered within the GitHub repo. You possibly can launch this solution in Amazon SageMaker Studio.
Click here to open the AWS console and follow along.
Forms of summarizations
There are a number of strategies to summarize textual content, that are broadly categorized into two fundamental approaches: extractive and abstractive summarization. Moreover, multi-level summarization methodologies incorporate a collection of steps, combining each extractive and abstractive strategies. These multi-level approaches are advantageous when coping with textual content with tokens longer than the restrict of an LLM, enabling an understanding of advanced narratives.
Extractive summarization
Extractive summarization is a way utilized in NLP and textual content evaluation to create a abstract by extracting key sentences. As an alternative of producing new sentences or content material as in abstractive summarization, extractive summarization depends on figuring out and pulling out probably the most related and informative parts of the unique textual content to create a condensed model.
Extractive summarization, though advantageous in preserving the unique content material and making certain excessive readability by immediately pulling essential sentences from the supply textual content, has limitations. It lacks creativity, is unable to generate novel sentences, and will overlook nuanced particulars, probably lacking essential data. Furthermore, it could produce prolonged summaries, typically overwhelming readers with extreme and undesirable data. There are a lot of extractive summarization strategies, reminiscent of TextRank and LexRank. On this put up, we deal with the BERT extractive summarizer.
BERT extractive summarizer
The BERT extractive summarizer is a kind of extractive summarization mannequin that makes use of the BERT language mannequin to extract an important sentences from a textual content. BERT is a pre-trained language mannequin that may be fine-tuned for quite a lot of duties, together with textual content summarization. It really works by first embedding the sentences within the textual content utilizing BERT. This produces a vector illustration for every sentence that captures its which means and context. The mannequin then makes use of a clustering algorithm to group the sentences into clusters. The sentences which can be closest to the middle of every cluster are chosen to type the abstract.
In contrast with LLMs, the benefit of the BERT extractive summarizer is it’s comparatively easy to coach and deploy the mannequin and it’s extra explainable. The drawback is the summarization isn’t artistic and doesn’t generate sentences. It solely selects sentences from the unique textual content. This limits its capability to summarize advanced or nuanced texts.
Abstractive summarization
Abstractive summarization is a way utilized in NLP and textual content evaluation to create a abstract that goes past mere extraction of sentences or phrases from the supply textual content. As an alternative of choosing and reorganizing current content material, abstractive summarization generates new sentences or phrases that seize the core which means and fundamental concepts of the unique textual content in a extra condensed and coherent type. This method requires the mannequin to grasp the content material of the textual content and categorical it in a method that’s not essentially current within the supply materials.
Specialised summarization fashions
These pre-trained pure language fashions, reminiscent of BART and PEGASUS, are particularly tailor-made for textual content summarization duties. They make use of encoder-decoder architectures and are smaller in parameters in comparison with their counterparts. This lowered measurement permits for ease of fine-tuning and deployment on smaller cases. Nevertheless, it’s essential to notice that these summarization fashions additionally include smaller enter and output token sizes. Not like their extra general-purpose counterparts, these fashions are completely designed for summarization duties. Because of this, the enter required for these fashions is solely the textual content that must be summarized.
Massive language fashions
A giant language mannequin refers to any mannequin that undergoes coaching on in depth and numerous datasets, sometimes by way of self-supervised studying at a big scale, and is able to being fine-tuned to go well with a wide selection of particular downstream duties. These fashions are bigger in parameter measurement and carry out higher in duties. Notably, they characteristic considerably bigger enter token sizes, some going up to 100,000, reminiscent of Anthropic’s Claude. To make use of one among these fashions, AWS gives the absolutely managed service Amazon Bedrock. For those who want extra management of the mannequin improvement lifecycle, you may deploy LLMs by way of SageMaker.
Given their versatile nature, these fashions require particular job directions offered by way of enter textual content, a observe known as prompt engineering. This artistic course of yields various outcomes primarily based on the mannequin kind and enter textual content. The effectiveness of each the mannequin’s efficiency and the immediate’s high quality considerably affect the ultimate high quality of the mannequin’s outputs. The next are some ideas when engineering prompts for summarization:
- Embody the textual content to summarize – Enter the textual content that must be summarized. This serves because the supply materials for the abstract.
- Outline the duty – Clearly state that the target is textual content summarization. For instance, “Summarize the next textual content: [input text].”
- Present context – Provide a quick introduction or context for the given textual content that must be summarized. This helps the mannequin perceive the content material and context. For instance, “You’re given the next article about Synthetic Intelligence and its function in Healthcare: [input text].”
- Immediate for the abstract – Immediate the mannequin to generate a abstract of the offered textual content. Be clear concerning the desired size or format of the abstract. For instance, “Please generate a concise abstract of the given article on Synthetic Intelligence and its function in Healthcare: [input text].”
- Set constraints or size pointers – Optionally, information the size of the abstract by specifying a desired phrase rely, sentence rely, or character restrict. For instance, “Please generate a abstract that’s now not than 50 phrases: [input text].”
Efficient immediate engineering is important for making certain that the generated summaries are correct, related, and aligned with the supposed summarization job. Refine the immediate for optimum summarization outcome with experiments and iterations. After you might have established the effectiveness of the prompts, you may reuse them with using prompt templates.
Multi-level summarization
Extractive and abstractive summarizations are helpful for shorter texts. Nevertheless, when the enter textual content exceeds the mannequin’s most token restrict, multi-level summarization turns into mandatory. Multi-level summarization includes a mix of assorted summarization strategies, reminiscent of extractive and abstractive strategies, to successfully condense longer texts by making use of a number of layers of summarization processes. On this part, we talk about two multi-level summarization strategies: extractive-abstractive summarization and abstractive-abstractive summarization.
Extractive-abstractive summarization
Extractive-abstractive summarization works by first producing an extractive abstract of the textual content. Then it makes use of an abstractive summarization system to refine the extractive abstract, making it extra concise and informative. This enhances accuracy by offering extra informative summaries in comparison with extractive strategies alone.
Extractive-abstractive content material summarization technique
The EACSS method combines the strengths of two highly effective strategies: the BERT extractive summarizer for the extractive section and LLMs for the abstractive section, as illustrated within the following diagram.

EACSS gives a number of benefits, together with the preservation of essential data, enhanced readability, and flexibility. Nevertheless, implementing EACSS is computationally costly and complicated. There’s a threat of potential data loss, and the standard of the summarization closely relies on the efficiency of the underlying fashions, making cautious mannequin choice and tuning important for attaining optimum outcomes. Implementation contains the next steps:
- Step one is to interrupt down the massive doc, reminiscent of a e-book, into smaller sections, or chunks. These chunks are outlined as sentences, paragraphs, and even chapters, relying on the granularity desired for the abstract.
- For the extractive section, we make use of the BERT extractive summarizer. This element works by embedding the sentences inside every chunk after which using a clustering algorithm to establish sentences which can be closest to the cluster’s centroids. This extractive step helps in preserving an important and related content material from every chunk.
- Having generated extractive summaries for every chunk, we transfer on to the abstractive summarization section. Right here, we make the most of LLMs recognized for his or her capability to generate coherent and contextually related summaries. These fashions take the extracted summaries as enter and produce abstractive summaries that seize the essence of the unique doc whereas making certain readability and coherence.
By combining extractive and abstractive summarization strategies, this method gives an environment friendly and complete solution to summarize prolonged paperwork reminiscent of books. It ensures that essential data is extracted whereas permitting for the era of concise and human-readable summaries, making it a beneficial software for numerous purposes within the area of doc summarization.
Abstractive-abstractive summarization
Abstractive-abstractive summarization is an method the place abstractive strategies are used for each extracting and producing summaries. It gives notable benefits, together with enhanced readability, coherence, and the pliability to regulate abstract size and element. It excels in language era, permitting for paraphrasing and avoiding redundancy. Nevertheless, there are drawbacks. For instance, it’s computationally costly and useful resource intensive, and its high quality closely relies on the effectiveness of the underlying fashions, which, if not well-trained or versatile, might affect the standard of the generated summaries. Number of fashions is essential to mitigate these challenges and guarantee high-quality abstractive summaries. For abstractive-abstractive summarization, we talk about two methods: Map Cut back and Map ReRank.
Map Cut back utilizing LangChain
This two-step course of contains a Map step and a Reduce step, as illustrated within the following diagram. This system lets you summarize an enter that’s longer than the mannequin’s enter token restrict.

The method consists of three fundamental steps:
- The corpora is break up into smaller chunks that match into the LLM’s token restrict.
- We use a Map step to individually apply an LLM chain that extracts all of the essential data from every passage, and its output is used as a brand new passage. Relying on the scale and construction of the corpora, this might be within the type of overarching themes or brief summaries.
- The Cut back step combines the output passages from the Map step or a Cut back Step such that it suits the token restrict and feeds it into the LLM. This course of is repeated till the ultimate output is a singular passage.
The benefit of utilizing this system is that it’s extremely scalable and parallelizable. All of the processing in every step is unbiased from one another, which takes benefit of distributed programs or serverless providers and decrease compute time.
Map ReRank utilizing LangChain
This chain runs an preliminary immediate on every doc that not solely tries to finish a job but in addition offers a rating for the way sure it’s in its reply. The best scoring response is returned.
This system is similar to Map Cut back however with the benefit of requiring fewer general calls, streamlining the summarization course of. Nevertheless, its limitation lies in its incapacity to merge data throughout a number of paperwork. This restriction makes it best in eventualities the place a single, easy reply is predicted from a singular doc, making it much less appropriate for extra advanced or multifaceted data retrieval duties that contain a number of sources. Cautious consideration of the context and the character of the information is crucial to find out the appropriateness of this methodology for particular summarization wants.
Cohere ReRank makes use of a semantic-based reranking system that contextualizes the which means of a consumer’s question past key phrase relevance. It’s used with vector retailer programs in addition to keyword-based engines like google, giving it flexibility.
Evaluating summarization strategies
Every summarization method has its personal distinctive benefits and drawbacks:
- Extractive summarization preserves the unique content material and ensures excessive readability however lacks creativity and will produce prolonged summaries.
- Abstractive summarization, whereas providing creativity and producing concise, fluent summaries, comes with the chance of unintentional content material modification, challenges in language accuracy, and resource-intensive improvement.
- Extractive-abstractive multi-level summarization successfully summarizes giant paperwork and supplies higher flexibility in fine-tuning the extractive a part of the fashions. Nevertheless, it’s costly, time consuming, and lacks parallelization, making parameter tuning difficult.
- Abstractive-abstractive multi-level summarization additionally successfully summarizes giant paperwork and excels in enhanced readability and coherence. Nevertheless, it’s computationally costly and useful resource intensive, relying closely on the effectiveness of underlying fashions.
Cautious mannequin choice is essential to mitigate challenges and guarantee high-quality abstractive summaries on this method. The next desk summarizes the capabilities for every kind of summarization.
| Facet | Extractive Summarization | Abstractive Summarization | Multi-level Summarization |
| Generate artistic and interesting summaries | No | Sure | Sure |
| Protect authentic content material | Sure | No | No |
| Steadiness data preservation and creativity | No | Sure | Sure |
| Appropriate for brief, goal textual content (enter textual content size smaller than most tokens of the mannequin) | Sure | Sure | No |
| Efficient for longer, advanced paperwork reminiscent of books (enter textual content size larger than most tokens of the mannequin) | No | No | Sure |
| Combines extraction and content material era | No | No | Sure |
Multi-level summarization strategies are appropriate for lengthy and complicated paperwork the place the enter textual content size exceeds the token restrict of the mannequin. The next desk compares these strategies.
| Approach | Benefits | Disadvantages |
| EACSS (extractive-abstractive) | Preserves essential data, supplies the flexibility to fine-tune the extractive a part of the fashions. | Computationally costly, potential data loss, and lacks parallelization. |
| Map Cut back (abstractive-abstractive) | Scalable and parallelizable, with much less compute time. The most effective method to generate artistic and concise summaries. | Reminiscence-intensive course of. |
| Map ReRank (abstractive-abstractive) | Streamlined summarization with semantic-based rating. | Restricted data merging. |
Suggestions when summarizing textual content
Take into account the next greatest practices when summarizing textual content:
- Concentrate on the entire token measurement – Be ready to separate the textual content if it exceeds the mannequin’s token limits or make use of a number of ranges of summarization when utilizing LLMs.
- Concentrate on the kinds and variety of knowledge sources – Combining data from a number of sources might require transformations, clear group, and integration methods. LangChain Stuff has integration on all kinds of information sources and document types. It simplifies the method of mixing textual content from completely different paperwork and knowledge sources with using this system.
- Concentrate on mannequin specialization – Some fashions might excel at sure forms of content material however battle with others. There could also be fine-tuned fashions which can be higher suited to your area of textual content.
- Use multi-level summarization for giant our bodies of textual content – For texts that exceed the token limits, contemplate a multi-level summarization method. Begin with a high-level abstract to seize the primary concepts after which progressively summarize subsections or chapters for extra detailed insights.
- Summarize textual content by subjects – This method helps preserve a logical move and scale back data loss, and it prioritizes the retention of essential data. For those who’re utilizing LLMs, craft clear and particular prompts that information the mannequin to summarize a selected subject as an alternative of the entire physique of textual content.
Conclusion
Summarization stands as a significant software in our information-rich period, enabling the environment friendly distillation of in depth data into concise and significant varieties. It performs a pivotal function in numerous domains, providing quite a few benefits. Summarization saves time by swiftly conveying important content material from prolonged paperwork, aids decision-making by extracting important data, and enhances comprehension in training and content material curation.
This put up offered a complete overview of assorted summarization strategies, together with extractive, abstractive, and multi-level approaches. With instruments like LangChain and language fashions, you may harness the facility of summarization to streamline communication, enhance decision-making, and unlock the total potential of huge data repositories. The comparability desk on this put up may also help you establish probably the most appropriate summarization strategies to your initiatives. Moreover, the ideas shared within the put up function beneficial pointers to keep away from repetitive errors when experimenting with LLMs for textual content summarization. This sensible recommendation empowers you to use the data gained, making certain profitable and environment friendly summarization within the initiatives.
References
In regards to the authors
 Nick Biso is a Machine Studying Engineer at AWS Skilled Companies. He solves advanced organizational and technical challenges utilizing knowledge science and engineering. As well as, he builds and deploys AI/ML fashions on the AWS Cloud. His ardour extends to his proclivity for journey and numerous cultural experiences.
Nick Biso is a Machine Studying Engineer at AWS Skilled Companies. He solves advanced organizational and technical challenges utilizing knowledge science and engineering. As well as, he builds and deploys AI/ML fashions on the AWS Cloud. His ardour extends to his proclivity for journey and numerous cultural experiences.
 Suhas chowdary Jonnalagadda is a Information Scientist at AWS International Companies. He’s keen about serving to enterprise prospects resolve their most advanced issues with the facility of AI/ML. He has helped prospects in reworking their enterprise options throughout numerous industries, together with finance, healthcare, banking, ecommerce, media, promoting, and advertising.
Suhas chowdary Jonnalagadda is a Information Scientist at AWS International Companies. He’s keen about serving to enterprise prospects resolve their most advanced issues with the facility of AI/ML. He has helped prospects in reworking their enterprise options throughout numerous industries, together with finance, healthcare, banking, ecommerce, media, promoting, and advertising.
 Tabby Ward is a Principal Cloud Architect/Strategic Technical Advisor with in depth expertise migrating prospects and modernizing their utility workload and providers to AWS. With over 25 years of expertise growing and architecting software program, she is acknowledged for her deep-dive capability in addition to skillfully incomes the belief of shoppers and companions to design architectures and options throughout a number of tech stacks and cloud suppliers.
Tabby Ward is a Principal Cloud Architect/Strategic Technical Advisor with in depth expertise migrating prospects and modernizing their utility workload and providers to AWS. With over 25 years of expertise growing and architecting software program, she is acknowledged for her deep-dive capability in addition to skillfully incomes the belief of shoppers and companions to design architectures and options throughout a number of tech stacks and cloud suppliers.
 Shyam Desai is a Cloud Engineer for large knowledge and machine studying providers at AWS. He helps enterprise-level massive knowledge purposes and prospects utilizing a mix of software program engineering experience with knowledge science. He has in depth data in laptop imaginative and prescient and imaging purposes for synthetic intelligence, in addition to biomedical and bioinformatic purposes.
Shyam Desai is a Cloud Engineer for large knowledge and machine studying providers at AWS. He helps enterprise-level massive knowledge purposes and prospects utilizing a mix of software program engineering experience with knowledge science. He has in depth data in laptop imaginative and prescient and imaging purposes for synthetic intelligence, in addition to biomedical and bioinformatic purposes.





