Welcome to a New Period of Constructing within the Cloud with Generative AI on AWS

We imagine generative AI has the potential over time to remodel just about each buyer expertise we all know. The variety of firms launching generative AI functions on AWS is substantial and constructing rapidly, together with adidas, Reserving.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Authorized & Skilled, to call just some. Modern startups like Perplexity AI are going all in on AWS for generative AI. Main AI firms like Anthropic have chosen AWS as their main cloud supplier for mission-critical workloads, and the place to coach their future fashions. And world providers and options suppliers like Accenture are reaping the advantages of personalized generative AI functions as they empower their in-house builders with Amazon CodeWhisperer.
These prospects are selecting AWS as a result of we’re targeted on doing what we’ve at all times completed—taking advanced and costly expertise that may remodel buyer experiences and companies and democratizing it for purchasers of all sizes and technical skills. To do that, we’re investing and quickly innovating to supply essentially the most complete set of capabilities throughout the three layers of the generative AI stack. The underside layer is the infrastructure to coach Giant Language Fashions (LLMs) and different Basis Fashions (FMs) and produce inferences or predictions. The center layer is simple entry to all the fashions and instruments prospects must construct and scale generative AI functions with the identical safety, entry management, and different options prospects anticipate from an AWS service. And on the prime layer, we’ve been investing in game-changing functions in key areas like generative AI-based coding. Along with providing them selection and—as they anticipate from us—breadth and depth of capabilities throughout all layers, prospects additionally inform us they admire our data-first strategy, and belief that we’ve constructed all the pieces from the bottom up with enterprise-grade safety and privateness.
This week we took a giant step ahead, asserting many vital new capabilities throughout all three layers of the stack to make it simple and sensible for our prospects to make use of generative AI pervasively of their companies.

Backside layer of the stack: AWS Trainium2 is the most recent addition to ship essentially the most superior cloud infrastructure for generative AI
The underside layer of the stack is the infrastructure—compute, networking, frameworks, providers—required to coach and run LLMs and different FMs. AWS innovates to supply essentially the most superior infrastructure for ML. Via our long-standing collaboration with NVIDIA, AWS was the primary to carry GPUs to the cloud greater than 12 years in the past, and most not too long ago we have been the primary main cloud supplier to make NVIDIA H100 GPUs out there with our P5 situations. We proceed to spend money on distinctive improvements that make AWS the very best cloud to run GPUs, together with the price-performance advantages of essentially the most superior virtualization system (AWS Nitro), highly effective petabit-scale networking with Elastic Cloth Adapter (EFA), and hyper-scale clustering with Amazon EC2 UltraClusters (1000’s of accelerated situations co-located in an Availability Zone and interconnected in a non-blocking community that may ship as much as 3,200 Gbps for massive-scale ML coaching). We’re additionally making it simpler for any buyer to entry extremely sought-after GPU compute capability for generative AI with Amazon EC2 Capability Blocks for ML—the primary and solely consumption mannequin within the {industry} that lets prospects reserve GPUs for future use (as much as 500 deployed in EC2 UltraClusters) for brief period ML workloads.
A number of years in the past, we realized that to maintain pushing the envelope on value efficiency we would want to innovate all the best way right down to the silicon, and we started investing in our personal chips. For ML particularly, we began with AWS Inferentia, our purpose-built inference chip. In the present day, we’re on our second technology of AWS Inferentia with Amazon EC2 Inf2 situations which are optimized particularly for large-scale generative AI functions with fashions containing tons of of billions of parameters. Inf2 situations supply the bottom price for inference within the cloud whereas additionally delivering as much as 4 instances greater throughput and as much as ten instances decrease latency in comparison with Inf1 situations. Powered by as much as 12 Inferentia2 chips, Inf2 are the one inference-optimized EC2 situations which have high-speed connectivity between accelerators so prospects can run inference sooner and extra effectively (at decrease price) with out sacrificing efficiency or latency by distributing ultra-large fashions throughout a number of accelerators. Clients like Adobe, Deutsche Telekom, and Leonardo.ai have seen nice early outcomes and are excited to deploy their fashions at scale on Inf2.
On the coaching aspect, Trn1 situations—powered by AWS’s purpose-built ML coaching chip, AWS Trainium—are optimized to distribute coaching throughout a number of servers related with EFA networking. Clients like Ricoh have skilled a Japanese LLM with billions of parameters in mere days. Databricks is getting as much as 40% higher price-performance with Trainium-based situations to coach large-scale deep studying fashions. However with new, extra succesful fashions popping out virtually each week, we’re persevering with to push the boundaries on efficiency and scale, and we’re excited to announce AWS Trainium2, designed to ship even higher value efficiency for coaching fashions with tons of of billions to trillions of parameters. Trainium2 ought to ship as much as 4 instances sooner coaching efficiency than first-generation Trainium, and when utilized in EC2 UltraClusters ought to ship as much as 65 exaflops of combination compute. This implies prospects will be capable of prepare a 300 billion parameter LLM in weeks versus months. Trainium2’s efficiency, scale, and power effectivity are a number of the the explanation why Anthropic has chosen to coach its fashions on AWS, and can use Trainium2 for its future fashions. And we’re collaborating with Anthropic on continued innovation with each Trainium and Inferentia. We anticipate our first Trainium2 situations to be out there to prospects in 2024.
We’ve additionally been doubling down on the software program software chain for our ML silicon, particularly in advancing AWS Neuron, the software program improvement package (SDK) that helps prospects get the utmost efficiency from Trainium and Inferentia. Since introducing Neuron in 2019 we’ve made substantial investments in compiler and framework applied sciences, and immediately Neuron helps lots of the hottest publicly out there fashions, together with Llama 2 from Meta, MPT from Databricks, and Secure Diffusion from Stability AI, in addition to 93 of the highest 100 fashions on the favored mannequin repository Hugging Face. Neuron plugs into well-liked ML frameworks like PyTorch and TensorFlow, and help for JAX is coming early subsequent yr. Clients are telling us that Neuron has made it simple for them to change their present mannequin coaching and inference pipelines to Trainium and Inferentia with just some strains of code.
No person else provides this identical mixture of selection of the very best ML chips, super-fast networking, virtualization, and hyper-scale clusters. And so, it’s not shocking that a number of the most well-known generative AI startups like AI21 Labs, Anthropic, Hugging Face, Perplexity AI, Runway, and Stability AI run on AWS. However, you continue to want the best instruments to successfully leverage this compute to construct, prepare, and run LLMs and different FMs effectively and cost-effectively. And for a lot of of those startups, Amazon SageMaker is the reply. Whether or not constructing and coaching a brand new, proprietary mannequin from scratch or beginning with one of many many well-liked publicly out there fashions, coaching is a fancy and costly enterprise. It’s additionally not simple to run these fashions cost-effectively. Clients should purchase giant quantities of knowledge and put together it. This usually includes loads of guide work cleansing information, eradicating duplicates, enriching and remodeling it. Then they need to create and keep giant clusters of GPUs/accelerators, write code to effectively distribute mannequin coaching throughout clusters, often checkpoint, pause, examine and optimize the mannequin, and manually intervene and remediate {hardware} points within the cluster. Many of those challenges aren’t new, they’re a number of the the explanation why we launched SageMaker six years in the past—to interrupt down the numerous obstacles concerned in mannequin coaching and deployment and provides builders a a lot simpler approach. Tens of 1000’s of consumers use Amazon SageMaker, and an growing variety of them like LG AI Analysis, Perplexity AI, AI21, Hugging Face, and Stability AI are coaching LLMs and different FMs on SageMaker. Only recently, Know-how Innovation Institute (creators of the favored Falcon LLMs) skilled the biggest publicly out there mannequin—Falcon 180B—on SageMaker. As mannequin sizes and complexity have grown, so has SageMaker’s scope.
Through the years, we’ve added greater than 380 game-changing options and capabilities to Amazon SageMaker like computerized mannequin tuning, distributed coaching, versatile mannequin deployment choices, instruments for ML OPs, instruments for information preparation, characteristic shops, notebooks, seamless integration with human-in-the-loop evaluations throughout the ML lifecycle, and built-in options for accountable AI. We hold innovating quickly to verify SageMaker prospects are capable of hold constructing, coaching, and working inference for all fashions—together with LLMs and different FMs. And we’re making it even simpler and more cost effective for purchasers to coach and deploy giant fashions with two new capabilities. First, to simplify coaching we’re introducing Amazon SageMaker HyperPod which automates extra of the processes required for high-scale fault-tolerant distributed coaching (e.g., configuring distributed coaching libraries, scaling coaching workloads throughout 1000’s of accelerators, detecting and repairing defective situations), rushing up coaching by as a lot as 40%. Because of this, prospects like Perplexity AI, Hugging Face, Stability, Hippocratic, Alkaid, and others are utilizing SageMaker HyperPod to construct, prepare, or evolve fashions. Second, we’re introducing new capabilities to make inference more cost effective whereas decreasing latency. SageMaker now helps prospects deploy a number of fashions to the identical occasion in order that they will share compute assets—decreasing inference price by 50% (on common). SageMaker additionally actively displays situations which are processing inference requests and intelligently routes requests primarily based on which situations can be found—reaching 20% decrease inference latency (on common). Conjecture, Salesforce, and Slack are already utilizing SageMaker for internet hosting fashions resulting from these inference optimizations.
Center layer of the stack: Amazon Bedrock provides new fashions and a wave of recent capabilities make it even simpler for purchasers to securely construct and scale generative AI functions
Whereas various prospects will construct their very own LLMs and different FMs, or evolve any variety of the publicly out there choices, many is not going to need to spend the assets and time to do that. For them, the center layer of the stack provides these fashions as a service. Our resolution right here, Amazon Bedrock, permits prospects to select from industry-leading fashions from Anthropic, Stability AI, Meta, Cohere, AI21, and Amazon, customise them with their very own information, and leverage all the identical main safety, entry controls, and options they’re used to in AWS—all by means of a managed service. We made Amazon Bedrock typically out there in late September, and buyer response has been overwhelmingly optimistic. Clients from all over the world and throughout just about each {industry} are excited to make use of Amazon Bedrock. adidas is enabling builders to get fast solutions on all the pieces from “getting began” information to deeper technical questions. Reserving.com intends to make use of generative AI to write down up tailor-made journey suggestions for each buyer. Bridgewater Associates is growing an LLM-powered Funding Analyst Assistant to assist generate charts, compute monetary indicators, and summarize outcomes. Service is making extra exact power analytics and insights accessible to prospects in order that they cut back power consumption and minimize carbon emissions. Clariant is empowering its staff members with an inner generative AI chatbot to speed up R&D processes, help gross sales groups with assembly preparation, and automate buyer emails. GoDaddy helps prospects simply arrange their companies on-line through the use of generative AI to construct their web sites, discover suppliers, join with prospects, and extra. Lexis Nexis Authorized & Skilled is reworking authorized work for attorneys and growing their productiveness with Lexis+ AI conversational search, summarization, and doc drafting and evaluation capabilities. Nasdaq helps to automate investigative workflows on suspicious transactions and strengthen their anti–monetary crime and surveillance capabilities. All of those—and plenty of extra—various generative AI functions are working on AWS.

We’re excited concerning the momentum for Amazon Bedrock, however it’s nonetheless early days. What we’ve seen as we’ve labored with prospects is that everybody is shifting quick, however the evolution of generative AI continues at a fast tempo with new choices and improvements taking place virtually day by day. Clients are discovering there are completely different fashions that work higher for various use circumstances, or on completely different units of knowledge. Some fashions are nice for summarization, others are nice for reasoning and integration, and nonetheless others have actually superior language help. After which there may be picture technology, search use circumstances, and extra—all coming from each proprietary fashions and from fashions which are publicly out there to anybody. And in instances when there may be a lot that’s unknowable, the flexibility to adapt is arguably essentially the most precious software of all. There may be not going to be one mannequin to rule all of them. And positively not only one expertise firm offering the fashions that everybody makes use of. Clients should be attempting out completely different fashions. They want to have the ability to change between them or mix them inside the identical use case. This implies they want an actual selection of mannequin suppliers (which the occasions of the previous 10 days have made much more clear). This is the reason we invented Amazon Bedrock, why it resonates so deeply with prospects, and why we’re persevering with to innovate and iterate rapidly to make constructing with (and shifting between) a spread of fashions as simple as an API name, put the most recent methods for mannequin customization within the palms of all builders, and hold prospects safe and their information personal. We’re excited to introduce a number of new capabilities that may make it even simpler for purchasers to construct and scale generative AI functions:
- Increasing mannequin selection with Anthropic Claude 2.1, Meta Llama 2 70B, and additions to the Amazon Titan household. In these early days, prospects are nonetheless studying and experimenting with completely different fashions to find out which of them they need to use for numerous functions. They need to have the ability to simply attempt the most recent fashions, and likewise check to see which capabilities and options will give them the very best outcomes and price traits for his or her use circumstances. With Amazon Bedrock, prospects are solely ever one API name away from a brand new mannequin. A few of the most spectacular outcomes prospects have skilled these previous few months are from LLMs like Anthropic’s Claude model, which excels at a variety of duties from subtle dialog and content material technology to advanced reasoning whereas sustaining a excessive diploma of reliability and predictability. Clients report that Claude is far much less prone to produce dangerous outputs, simpler to converse with, and extra steerable in comparison with different FMs, so builders can get their desired output with much less effort. Anthropic’s state-of-the-art mannequin, Claude 2, scores above the ninetieth percentile on the GRE studying and writing exams, and equally on quantitative reasoning. And now, the newly launched Claude 2.1 mannequin is offered in Amazon Bedrock. Claude 2.1 delivers key capabilities for enterprises similar to an industry-leading 200K token context window (2x the context of Claude 2.0), decreased charges of hallucination, and vital enhancements in accuracy, even at very lengthy context lengths. Claude 2.1 additionally consists of improved system prompts – that are mannequin directions that present a greater expertise for finish customers – whereas additionally decreasing the price of prompts and completions by 25%.
For a rising variety of prospects who need to use a managed model of Meta’s publicly out there Llama 2 mannequin, Amazon Bedrock provides Llama 2 13B, and we’re including Llama 2 70B. Llama 2 70B is appropriate for large-scale duties similar to language modeling, textual content technology, and dialogue programs. The publicly out there Llama fashions have been downloaded greater than 30M instances, and prospects love that Amazon Bedrock provides them as a part of a managed service the place they don’t want to fret about infrastructure or have deep ML experience on their groups. Moreover, for picture technology, Stability AI provides a collection of well-liked text-to-image fashions. Secure Diffusion XL 1.0 (SDXL 1.0) is essentially the most superior of those, and it’s now typically out there in Amazon Bedrock. The most recent version of this well-liked picture mannequin has elevated accuracy, higher photorealism, and better decision.
Clients are additionally utilizing Amazon Titan fashions, that are created and pretrained by AWS to supply highly effective capabilities with nice economics for quite a lot of use circumstances. Amazon has a 25 yr monitor file in ML and AI—expertise we use throughout our companies—and we have now realized rather a lot about constructing and deploying fashions. We now have fastidiously chosen how we prepare our fashions and the information we use to take action. We indemnify prospects in opposition to claims that our fashions or their outputs infringe on anybody’s copyright. We launched our first Titan fashions in April of this yr. Titan Text Lite—now typically out there—is a succinct, cost-effective mannequin to be used circumstances like chatbots, textual content summarization, or copywriting, and additionally it is compelling to fine-tune. Titan Textual content Categorical—additionally now typically out there—is extra expansive, and can be utilized for a wider vary of text-based duties, similar to open-ended textual content technology and conversational chat. We provide these textual content mannequin choices to provide prospects the flexibility to optimize for accuracy, efficiency, and price relying on their use case and enterprise necessities. Clients like Nexxiot, PGA Tour, and Ryanair are utilizing our two Titan Textual content fashions. We even have an embeddings mannequin, Titan Textual content Embeddings, for search use circumstances and personalization. Clients like Nasdaq are seeing nice outcomes utilizing Titan Textual content Embeddings to boost capabilities for Nasdaq IR Perception to generate insights from 9,000+ world firms’ paperwork for sustainability, authorized, and accounting groups. And we’ll proceed so as to add extra fashions to the Titan household over time. We’re introducing a brand new embeddings mannequin, Titan Multimodal Embeddings, to energy multimodal search and advice experiences for customers utilizing photographs and textual content (or a mix of each) as inputs. And we’re introducing a brand new text-to-image mannequin, Amazon Titan Picture Generator. With Titan Picture Generator, prospects throughout industries like promoting, e-commerce, and media and leisure can use a textual content enter to generate sensible, studio-quality photographs in giant volumes and at low price. We’re enthusiastic about how prospects are responding to Titan Fashions, and you may anticipate that we’ll proceed to innovate right here.
- New capabilities to customise your generative AI utility securely together with your proprietary information: One of the crucial vital capabilities of Amazon Bedrock is how simple it’s to customise a mannequin. This turns into actually thrilling for purchasers as a result of it’s the place generative AI meets their core differentiator—their information. Nonetheless, it’s actually vital that their information stays safe, that they’ve management of it alongside the best way, and that mannequin enhancements are personal to them. There are just a few ways in which you are able to do this, and Amazon Bedrock provides the broadest choice of customization choices throughout a number of fashions). The primary is okay tuning. Tremendous tuning a mannequin in Amazon Bedrock is simple. You merely choose the mannequin and Amazon Bedrock makes a replica of it. Then you definately level to some labeled examples (e.g., a sequence of fine question-answer pairs) that you simply retailer in Amazon Easy Storage Service (Amazon S3), and Amazon Bedrock “incrementally trains” (augments the copied mannequin with the brand new data) on these examples, and the result’s a non-public, extra correct fine-tuned mannequin that delivers extra related, personalized responses. We’re excited to announce that advantageous tuning is mostly out there for Cohere Command, Meta Llama 2, Amazon Titan Textual content (Lite and Categorical), Amazon Titan Multimodal Embeddings, and in preview for Amazon Titan Picture Generator. And, by means of our collaboration with Anthropic, we are going to quickly present AWS prospects early entry to distinctive options for mannequin customization and fine-tuning of its state-of-the-art mannequin Claude.
A second approach for customizing LLMs and different FMs for your corporation is retrieval augmented technology (RAG), which lets you customise a mannequin’s responses by augmenting your prompts with information from a number of sources, together with doc repositories, databases, and APIs. In September, we launched a RAG functionality, Information Bases for Amazon Bedrock, that securely connects fashions to your proprietary information sources to complement your prompts with extra data so your functions ship extra related, contextual, and correct responses. Knowledge Bases is now typically out there with an API that performs your entire RAG workflow from fetching textual content wanted to enhance a immediate, to sending the immediate to the mannequin, to returning the response. Information Bases helps databases with vector capabilities that retailer numerical representations of your information (embeddings) that fashions use to entry this information for RAG, together with Amazon OpenSearch Service, and different well-liked databases like Pinecone and Redis Enterprise Cloud (Amazon Aurora and MongoDB vector help coming quickly).
The third approach you may customise fashions in Amazon Bedrock is with continued pre-training. With this technique, the mannequin builds on its unique pre-training for basic language understanding to be taught domain-specific language and terminology. This strategy is for purchasers who’ve giant troves of unlabeled, domain-specific data and need to allow their LLMs to grasp the language, phrases, abbreviations, ideas, definitions, and jargon distinctive to their world (and enterprise). Not like in fine-tuning, which takes a reasonably small quantity of knowledge, continued pre-training is carried out on giant information units (e.g., 1000’s of textual content paperwork). Now, pre-training capabilities can be found in Amazon Bedrock for Titan Textual content Lite and Titan Textual content Categorical.
- Common availability of Agents for Amazon Bedrock to assist execute multistep duties utilizing programs, information sources, and firm information. LLMs are nice at having conversations and producing content material, however prospects need their functions to have the ability to do much more—like take actions, remedy issues, and work together with a spread of programs to finish multi-step duties like reserving journey, submitting insurance coverage claims, or ordering alternative elements. And Amazon Bedrock can assist with this problem. With brokers, builders choose a mannequin, write just a few fundamental directions like “you’re a cheerful customer support agent” and “examine product availability within the stock system,” level the chosen mannequin to the best information sources and enterprise programs (e.g., CRM or ERP functions), and write just a few AWS Lambda features to execute the APIs (e.g., examine availability of an merchandise within the ERP stock). Amazon Bedrock routinely analyzes the request and breaks it down right into a logical sequence utilizing the chosen mannequin’s reasoning capabilities to find out what data is required, what APIs to name, and when to name them to finish a step or remedy a process. Now typically out there, brokers can plan and carry out most enterprise duties—from answering buyer questions on your product availability to taking their orders—and builders don’t should be aware of machine studying, engineer prompts, prepare fashions, or manually join programs. And Bedrock does all of this securely and privately, and prospects like Druva and Athene are already utilizing them to enhance the accuracy and velocity of improvement of their generative AI functions.
- Introducing Guardrails for Amazon Bedrock so you may apply safeguards primarily based in your use case necessities and accountable AI insurance policies. Clients need to ensure that interactions with their AI functions are protected, keep away from poisonous or offensive language, keep related to their enterprise, and align with their accountable AI insurance policies. With guardrails, prospects can specify matters to keep away from, and Amazon Bedrock will solely present customers with accredited responses to questions that fall in these restricted classes. For instance, an internet banking utility will be set as much as keep away from offering funding recommendation, and take away inappropriate content material (similar to hate speech and violence). In early 2024, prospects may also be capable of redact personally identifiable data (PII) in mannequin responses. For instance, after a buyer interacts with a name middle agent the customer support dialog is commonly summarized for file maintaining, and guardrails can take away PII from these summaries. Guardrails can be utilized throughout fashions in Amazon Bedrock (together with fine-tuned fashions), and with Brokers for Amazon Bedrock so prospects can carry a constant degree of safety to all of their generative AI functions.
High layer of the stack: Continued innovation makes generative AI accessible to extra customers
On the prime layer of the stack are functions that leverage LLMs and different FMs so as to benefit from generative AI at work. One space the place generative AI is already altering the sport is in coding. Final yr, we launched Amazon CodeWhisperer, which helps you construct functions sooner and extra securely by producing code solutions and suggestions in close to real-time. Clients like Accenture, Boeing, Bundesliga, The Cigna Group, Kone, and Warner Music Group are utilizing CodeWhisperer to extend developer productiveness—and Accenture is enabling as much as 50,000 of their software program builders and IT professionals with Amazon CodeWhisperer. We would like as many builders as potential to have the ability to get the productiveness advantages of generative AI, which is why CodeWhisperer provides suggestions free of charge to all people.
Nonetheless, whereas AI coding instruments do rather a lot to make builders’ lives simpler, their productiveness advantages are restricted by their lack of information of inner code bases, inner APIs, libraries, packages and courses. A method to consider that is that should you rent a brand new developer, even when they’re world-class, they’re not going to be that productive at your organization till they perceive your finest practices and code. In the present day’s AI-powered coding instruments are like that new-hire developer. To assist with this, we not too long ago previewed a brand new customization capability in Amazon CodeWhisperer that securely leverages a buyer’s inner code base to supply extra related and helpful code suggestions. With this functionality, CodeWhisperer is an skilled on your code and gives suggestions which are extra related to save lots of much more time. In a research we did with Persistent, a worldwide digital engineering and enterprise modernization firm, we discovered that customizations assist builders full duties as much as 28% sooner than with CodeWhisperer’s basic capabilities. Now a developer at a healthcare expertise firm can ask CodeWhisperer to “import MRI photographs related to the client ID and run them by means of the picture classifier“ to detect anomalies. As a result of CodeWhisperer has entry to the code base it might present far more related solutions that embody the import areas of the MRI photographs and buyer IDs. CodeWhisperer retains customizations utterly personal, and the underlying FM doesn’t use them for coaching, defending prospects’ precious mental property. AWS is the one main cloud supplier that provides a functionality like this to everybody.
Introducing Amazon Q, the generative AI-powered assistant tailor-made for work
Builders actually aren’t the one ones who’re getting palms on with generative AI—hundreds of thousands of persons are utilizing generative AI chat functions. What early suppliers have completed on this house is thrilling and tremendous helpful for shoppers, however in loads of methods they don’t fairly “work” at work. Their basic information and capabilities are nice, however they don’t know your organization, your information, your prospects, your operations, or your corporation. That limits how a lot they can assist you. Additionally they don’t know a lot about your function—what work you do, who you’re employed with, what data you utilize, and what you’ve got entry to. These limitations are comprehensible as a result of these assistants don’t have entry to your organization’s personal data, and so they weren’t designed to satisfy the information privateness and safety necessities firms want to provide them this entry. It’s exhausting to bolt on safety after the actual fact and anticipate it to work effectively. We predict we have now a greater approach, which is able to enable each individual in each group to make use of generative AI safely of their day-to-day work.
We are excited to introduce Amazon Q, a brand new kind of generative AI-powered assistant that’s particularly for work and will be tailor-made to your corporation. Q can assist you get quick, related solutions to urgent questions, remedy issues, generate content material, and take actions utilizing the information and experience present in your organization’s data repositories, code, and enterprise programs. Once you chat with Amazon Q, it gives rapid, related data and recommendation to assist streamline duties, velocity decision-making, and assist spark creativity and innovation at work. We now have constructed Amazon Q to be safe and personal, and it might perceive and respect your present identities, roles, and permissions and use this data to personalize its interactions. If a consumer doesn’t have permission to entry sure information with out Q, they will’t entry it utilizing Q both. We now have designed Amazon Q to satisfy stringent enterprise prospects’ necessities from day one—none of their content material is used to enhance the underlying fashions.
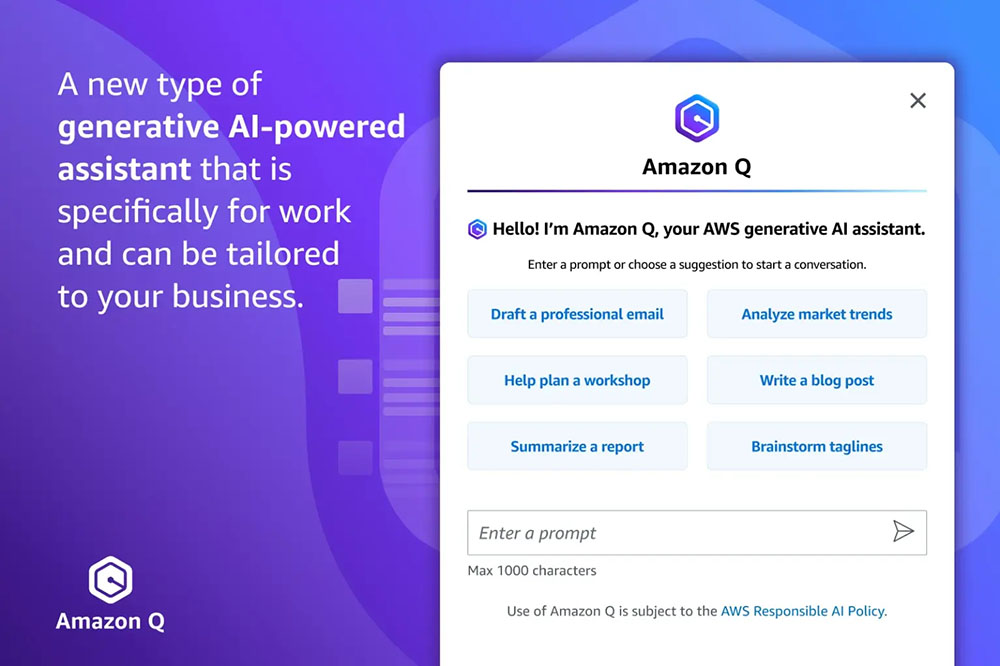
Amazon Q is your expert assistant for constructing on AWS: We’ve skilled Amazon Q on 17 years’ value of AWS information and expertise so it might remodel the best way you construct, deploy, and function functions and workloads on AWS. Amazon Q has a chat interface within the AWS Administration Console and documentation, your IDE (through CodeWhisperer), and your staff chat rooms on Slack or different chat apps. Amazon Q can assist you discover new AWS capabilities, get began sooner, be taught unfamiliar applied sciences, architect options, troubleshoot, improve, and far more —it’s an skilled in AWS well-architected patterns, finest practices, documentation, and options implementations. Listed below are some examples of what you are able to do together with your new AWS skilled assistant:
- Get crisp solutions and steerage on AWS capabilities, providers, and options: Ask Amazon Q to “Inform me about Brokers for Amazon Bedrock,” and Q offers you an outline of the characteristic plus hyperlinks to related supplies. You may as well Ask Amazon Q just about any query about how an AWS service works (e.g., “What are the scaling limits on a DynamoDB desk?” “What’s Redshift Managed Storage?”), or tips on how to finest architect any variety of options (“What are the very best practices for constructing event-driven architectures?”). And Amazon Q will pull collectively succinct solutions and at all times cite (and hyperlink to) its sources.
- Select the very best AWS service in your use case, and get began rapidly: Ask Amazon Q “What are the methods to construct a Internet app on AWS? ” and it’ll present a listing of potential providers like AWS Amplify, AWS Lambda, and Amazon EC2 with some great benefits of every. From there you may slender down the choices by serving to Q perceive your necessities, preferences, and constraints (e.g., “Which of those could be finest if I need to use containers?” or “Ought to I exploit a relational or non-relational database?”). End up with “How do I get began?” and Amazon Q will define some fundamental steps and level you in the direction of further assets.
- Optimize your compute assets: Amazon Q can assist you choose Amazon EC2 situations. In case you ask it to “Assist me discover the best EC2 occasion to deploy a video encoding workload for my gaming app with the best efficiency”, Q will get you a listing of occasion households with causes for every suggestion. And, you may ask any variety of observe up questions to assist discover your best option in your workload.
- Get help debugging, testing, and optimizing your code: In case you encounter an error whereas coding in your IDE, you may ask Amazon Q to assist by saying, “My code has an IO error, are you able to present a repair?” and Q will generate the code for you. In case you just like the suggestion, you may ask Amazon Q so as to add the repair to your utility. Since Amazon Q is in your IDE, it understands the code you’re engaged on and is aware of the place to insert the repair. Amazon Q also can create unit exams (“Write unit exams for the chosen operate”) that it might insert into your code and you may run. Lastly, Amazon Q can inform you methods to optimize your code for greater efficiency. Ask Q to “Optimize my chosen DynamoDB question,” and it’ll use its understanding of your code to supply a pure language suggestion on what to repair together with the accompanying code you may implement in a single click on.
- Diagnose and troubleshoot points: In case you encounter points within the AWS Administration Console, like EC2 permissions errors or Amazon S3 configuration errors, you may merely press the “Troubleshoot with Amazon Q” button, and it’ll use its understanding of the error kind and repair the place the error is situated to provide you a solutions for a repair. You possibly can even ask Amazon Q to troubleshoot your community (e.g., “Why can’t I hook up with my EC2 occasion utilizing SSH?”) and Q will analyze your end-to-end configuration and supply a prognosis (e.g., “This occasion seems to be in a non-public subnet, so public accessibility could should be established”).
- Ramp up on a brand new code base very quickly: Once you chat with Amazon Q in your IDE, it combines its experience in constructing software program with an understanding of your code—a robust pairing! Beforehand, should you took over a undertaking from another person, otherwise you have been new to the staff, you might need to spend hours manually reviewing the code and documentation to grasp the way it works and what it does. Now, since Amazon Q understands the code in your IDE, you may merely ask Amazon Q to elucidate the code (“Present me with an outline of what this utility does and the way it works”) and Q offers you particulars like which providers the code makes use of and what completely different features do (e.g., Q would possibly reply with one thing like, “This utility is constructing a fundamental help ticket system utilizing Python Flask and AWS Lambda” and go on to explain every of its core capabilities, how they’re applied, and far more).
- Clear your characteristic backlog sooner: You possibly can even ask Amazon Q to information you thru and automate a lot of the end-to-end technique of including a characteristic to your utility in Amazon CodeCatalyst, our unified software program improvement service for groups. To do that, you simply assign Q a backlog process out of your points checklist – similar to you’ll a teammate – and Q generates a step-by-step plan for the way it will construct and implement the characteristic. When you approve the plan, Q will write the code and current the steered modifications to you as a code evaluate. You possibly can request rework (if vital), approve and/or deploy!
- Improve your code in a fraction of the time: Most builders truly solely spend a fraction of their time writing new code and constructing new functions. They spend much more of their cycles on painful, sloggy areas like upkeep and upgrades. Take language model upgrades. Numerous prospects proceed utilizing older variations of Java as a result of it would take months—even years—and 1000’s of hours of developer time to improve. Placing this off has actual prices and dangers—you miss out on efficiency enhancements and are weak to safety points. We predict Amazon Q is usually a sport changer right here, and are enthusiastic about Amazon Q Code Transformation, a characteristic which might take away loads of this heavy lifting and cut back the time it takes to improve functions from days to minutes. You simply open the code you need to replace in your IDE, and ask Amazon Q to “/remodel” your code. Amazon Q will analyze your entire supply code of the appliance, generate the code within the goal language and model, and execute exams, serving to you notice the safety and efficiency enhancements of the most recent language variations. Just lately, a really small staff of Amazon builders used Amazon Q Code Transformation to improve 1,000 manufacturing functions from Java 8 to Java 17 in simply two days. The common time per utility was lower than 10 minutes. In the present day Amazon Q Code Transformation performs Java language upgrades from Java 8 or Java 11 to Java 17. Coming subsequent (and shortly) is the flexibility to remodel .NET Framework to cross-platform .NET (with much more transformations to observe sooner or later).
Amazon Q is your business expert: You possibly can join Amazon Q to your corporation information, data, and programs in order that it might synthesize all the pieces and supply tailor-made help to assist individuals remedy issues, generate content material, and take actions which are related to your corporation. Bringing Amazon Q to your corporation is simple. It has 40+ built-in connectors to well-liked enterprise programs similar to Amazon S3, Microsoft 365, Salesforce, ServiceNow, Slack, Atlassian, Gmail, Google Drive, and Zendesk. It could additionally hook up with your inner intranet, wikis, and run books, and with the Amazon Q SDK, you may construct a connection to whichever inner utility you prefer to. Level Amazon Q at these repositories, and it’ll “ramp up” on your corporation, capturing and understanding the semantic data that makes your organization distinctive. Then, you get your personal pleasant and easy Amazon Q internet utility in order that workers throughout your organization can work together with the conversational interface. Amazon Q additionally connects to your identification supplier to grasp a consumer, their function, and what programs they’re permitted to entry in order that customers can ask detailed, nuanced questions and get tailor-made outcomes that embody solely data they’re approved to see. Amazon Q generates solutions and insights which are correct and trustworthy to the fabric and information that you simply present it, and you may limit delicate matters, block key phrases, or filter out inappropriate questions and solutions. Listed below are just a few examples of what you are able to do with your corporation’s new skilled assistant:
- Get crisp, super-relevant solutions primarily based on your corporation information and data: Workers can ask Amazon Q about something they may have beforehand had to go looking for throughout every kind of sources. Ask “What are the most recent tips for brand utilization?”, or “How do I apply for a corporation bank card?”, and Amazon Q will synthesize all the related content material it finds and are available again with quick solutions plus hyperlinks to the related sources (e.g., model portals and brand repositories, firm T&E insurance policies, and card functions).
- Streamline day-to-day communications: Simply ask, and Amazon Q can generate content material (“Create a weblog put up and three social media headlines asserting the product described on this documentation”), create government summaries (“Write a abstract of our assembly transcript with a bulleted checklist of motion gadgets”), present e mail updates (“Draft an e mail highlighting our Q3 coaching packages for purchasers in India”), and assist construction conferences (“Create a gathering agenda to speak concerning the newest buyer satisfaction report”).
- Full duties: Amazon Q can assist full sure duties, decreasing the period of time workers spend on repetitive work like submitting tickets. Ask Amazon Q to “Summarize buyer suggestions on the brand new pricing supply in Slack,” after which request that Q take that data and open a ticket in Jira to replace the advertising and marketing staff. You possibly can ask Q to “Summarize this name transcript,” after which “Open a brand new case for Buyer A in Salesforce.” Amazon Q helps different well-liked work automation instruments like Zendesk and Service Now.
Amazon Q is in Amazon QuickSight: With Amazon Q in QuickSight, AWS’s enterprise intelligence service, customers can ask their dashboards questions like “Why did the variety of orders improve final month?” and get visualizations and explanations of the components that influenced the rise. And, analysts can use Amazon Q to scale back the time it takes them to construct dashboards from days to minutes with a easy immediate like “Present me gross sales by area by month as a stacked bar chart.” Q comes proper again with that diagram, and you may simply add it to a dashboard or chat additional with Q to refine the visualization (e.g., “Change the bar chart right into a Sankey diagram,” or “Present international locations as a substitute of areas”). Amazon Q in QuickSight additionally makes it simpler to make use of present dashboards to tell enterprise stakeholders, distill key insights, and simplify decision-making utilizing information tales. For instance, customers could immediate Amazon Q to “Construct a narrative about how the enterprise has modified during the last month for a enterprise evaluate with senior management,” and in seconds, Amazon Q delivers a data-driven story that’s visually compelling and is totally customizable. These tales will be shared securely all through the group to assist align stakeholders and drive higher selections.
Amazon Q is in Amazon Join: In Amazon Join, our contact middle service, Amazon Q helps your customer support brokers present higher customer support. Amazon Q leverages the information repositories your brokers usually use to get data for purchasers, after which brokers can chat with Amazon Q immediately in Hook up with get solutions that assist them reply extra rapidly to buyer requests without having to look by means of the documentation themselves. And, whereas chatting with Amazon Q for super-fast solutions is nice, in customer support there is no such thing as a such factor as too quick. That’s why Amazon Q In Connect turns a stay buyer dialog with an agent right into a immediate, and routinely offering the agent potential responses, steered actions, and hyperlinks to assets. For instance, Amazon Q can detect {that a} buyer is contacting a rental automobile firm to vary their reservation, generate a response for the agent to rapidly talk how the corporate’s change price insurance policies apply, and information the agent by means of the steps they should replace the reservation.
Amazon Q is in AWS Provide Chain (Coming Quickly): In AWS Provide Chain, our provide chain insights service, Amazon Q helps provide and demand planners, stock managers, and buying and selling companions optimize their provide chain by summarizing and highlighting potential stockout or overstock dangers, and visualize eventualities to unravel the issue. Customers can ask Amazon Q “what,” “why,” and “what if” questions on their provide chain information and chat by means of advanced eventualities and the tradeoffs between completely different provide chain selections. For instance, a buyer could ask, “What’s inflicting the delay in my shipments and the way can I velocity issues up?” to which Amazon Q could reply, “90% of your orders are on the east coast, and a giant storm within the Southeast is inflicting a 24-hour delay. In case you ship to the port of New York as a substitute of Miami, you’ll expedite deliveries and cut back prices by 50%.”
Our prospects are adopting generative AI rapidly—they’re coaching groundbreaking fashions on AWS, they’re growing generative AI functions at file velocity utilizing Amazon Bedrock, and they’re deploying game-changing functions throughout their organizations like Amazon Q. With our newest bulletins, AWS is bringing prospects much more efficiency, selection, and innovation to each layer of the stack. The mixed impression of all of the capabilities we’re delivering at re:Invent marks a significant milestone towards assembly an thrilling and significant aim: We’re making generative AI accessible to prospects of all sizes and technical skills to allow them to get to reinventing and remodeling what is feasible.
Assets
Concerning the Writer
 Swami Sivasubramanian is Vice President of Knowledge and Machine Studying at AWS. On this function, Swami oversees all AWS Database, Analytics, and AI & Machine Studying providers. His staff’s mission is to assist organizations put their information to work with an entire, end-to-end information resolution to retailer, entry, analyze, and visualize, and predict.
Swami Sivasubramanian is Vice President of Knowledge and Machine Studying at AWS. On this function, Swami oversees all AWS Database, Analytics, and AI & Machine Studying providers. His staff’s mission is to assist organizations put their information to work with an entire, end-to-end information resolution to retailer, entry, analyze, and visualize, and predict.