Enhance prediction high quality in customized classification fashions with Amazon Comprehend
Synthetic intelligence (AI) and machine studying (ML) have seen widespread adoption throughout enterprise and authorities organizations. Processing unstructured knowledge has change into simpler with the developments in pure language processing (NLP) and user-friendly AI/ML companies like Amazon Textract, Amazon Transcribe, and Amazon Comprehend. Organizations have began to make use of AI/ML companies like Amazon Comprehend to construct classification fashions with their unstructured knowledge to get deep insights that they didn’t have earlier than. Though you should utilize pre-trained fashions with minimal effort, with out correct knowledge curation and mannequin tuning, you possibly can’t understand the complete advantages AI/ML fashions.
On this submit, we clarify the way to construct and optimize a customized classification mannequin utilizing Amazon Comprehend. We show this utilizing an Amazon Comprehend customized classification to construct a multi-label customized classification mannequin, and supply tips on the way to put together the coaching dataset and tune the mannequin to fulfill efficiency metrics equivalent to accuracy, precision, recall, and F1 rating. We use the Amazon Comprehend mannequin coaching output artifacts like a confusion matrix to tune mannequin efficiency and information you on bettering your coaching knowledge.
Answer overview
This resolution presents an strategy to constructing an optimized customized classification mannequin utilizing Amazon Comprehend. We undergo a number of steps, together with knowledge preparation, mannequin creation, mannequin efficiency metric evaluation, and optimizing inference primarily based on our evaluation. We use an Amazon SageMaker notebook and the AWS Management Console to finish a few of these steps.
We additionally undergo greatest practices and optimization methods throughout knowledge preparation, mannequin constructing, and mannequin tuning.
Conditions
In the event you don’t have a SageMaker pocket book occasion, you possibly can create one. For directions, consult with Create an Amazon SageMaker Notebook Instance.
Put together the information
For this evaluation, we use the Poisonous Remark Classification dataset from Kaggle. This dataset comprises 6 labels with 158,571 knowledge factors. Nonetheless, every label solely has lower than 10% of the entire knowledge as constructive examples, with two of the labels having lower than 1%.
We convert the prevailing Kaggle dataset to the Amazon Comprehend two-column CSV format with the labels cut up utilizing a pipe (|) delimiter. Amazon Comprehend expects a minimum of one label for every knowledge level. On this dataset, we encounter a number of knowledge factors that don’t fall underneath any of the supplied labels. We create a brand new label referred to as clear and assign any of the information factors that aren’t poisonous to be constructive with this label. Lastly, we cut up the curated datasets into coaching and check datasets utilizing an 80/20 ratio cut up per label.
We can be utilizing the Knowledge-Preparation pocket book. The next steps use the Kaggle dataset and put together the information for our mannequin.
- On the SageMaker console, select Pocket book situations within the navigation pane.
- Choose the pocket book occasion you might have configured and select Open Jupyter.
- On the New menu, select Terminal.

- Run the next instructions within the terminal to obtain the required artifacts for this submit:
- Shut the terminal window.
It’s best to see three notebooks and practice.csv information.
- Select the pocket book Knowledge-Preparation.ipynb.
- Run all of the steps within the pocket book.
These steps put together the uncooked Kaggle dataset to function curated coaching and check datasets. Curated datasets can be saved within the pocket book and Amazon Simple Storage Service (Amazon S3).
Think about the next knowledge preparation tips when coping with large-scale multi-label datasets:
- Datasets should have a minimal of 10 samples per label.
- Amazon Comprehend accepts a most of 100 labels. This can be a gentle restrict that may be elevated.
- Make sure the dataset file is correctly formatted with the right delimiter. Incorrect delimiters can introduce clean labels.
- All the information factors should have labels.
- Coaching and check datasets ought to have balanced knowledge distribution per label. Don’t use random distribution as a result of it’d introduce bias within the coaching and check datasets.
Construct a customized classification mannequin
We use the curated coaching and check datasets we created in the course of the knowledge preparation step to construct our mannequin. The next steps create an Amazon Comprehend multi-label customized classification mannequin:
- On the Amazon Comprehend console, select Customized classification within the navigation pane.
- Select Create new mannequin.
- For Mannequin title, enter toxic-classification-model.
- For Model title, enter 1.
- For Annotation and knowledge format, select Utilizing Multi-label mode.
- For Coaching dataset, enter the placement of the curated coaching dataset on Amazon S3.
- Select Buyer supplied check dataset and enter the placement of the curated check knowledge on Amazon S3.
- For Output knowledge, enter the Amazon S3 location.
- For IAM function, choose Create an IAM function, specify the title suffix as “comprehend-blog”.
- Select Create to start out the customized classification mannequin coaching and mannequin creation.
The next screenshot exhibits the customized classification mannequin particulars on the Amazon Comprehend console.

Tune for mannequin efficiency
The next screenshot exhibits the mannequin efficiency metrics. It consists of key metrics like precision, recall, F1 rating, accuracy, and extra.

After the mannequin is skilled and created, it should generate the output.tar.gz file, which comprises the labels from the dataset in addition to the confusion matrix for every of the labels. To additional tune the mannequin’s prediction efficiency, you must perceive your mannequin with the prediction possibilities for every class. To do that, you should create an evaluation job to determine the scores Amazon Comprehend assigned to every of the information factors.
Full the next steps to create an evaluation job:
- On the Amazon Comprehend console, select Evaluation jobs within the navigation pane.
- Select Create job.
- For Identify, enter
toxic_train_data_analysis_job. - For Evaluation kind, select Customized classification.
- For Classification fashions and flywheels, specify
toxic-classification-model. - For Model, specify 1.
- For Enter knowledge S3 location, enter the placement of the curated coaching knowledge file.
- For Enter format, select One doc per line.
- For Output knowledge S3 location, enter the placement.
- For Entry Permissions, choose Use an present IAM Function and decide the function created beforehand.
- Select Create job to start out the evaluation job.
- Choose the Evaluation jobs to view the job particulars. Please take a be aware of the job id underneath Job particulars. We can be utilizing the job id in our subsequent step.

Repeat the steps to the beginning evaluation job for the curated check knowledge. We use the prediction outputs from our evaluation jobs to find out about our mannequin’s prediction possibilities. Please make be aware of job ids of coaching and check evaluation jobs.
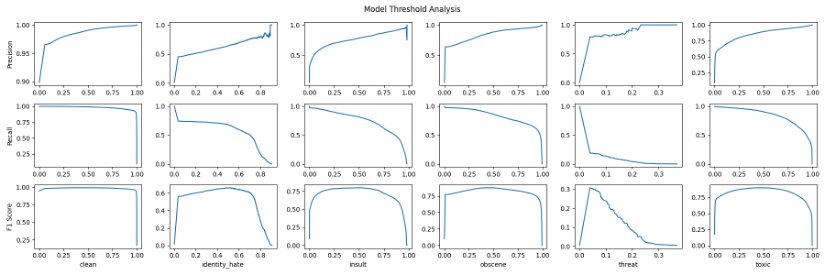
We use the Mannequin-Threshold-Evaluation.ipynb pocket book to check the outputs on all attainable thresholds and rating the output primarily based on the prediction chance utilizing the scikit-learn’s precision_recall_curve operate. Moreover, we are able to compute the F1 rating at every threshold.
We are going to want the Amazon Comprehend evaluation job id’s as enter for Mannequin-Threshold-Evaluation pocket book. You will get the job ids from Amazon Comprehend console. Execute all of the steps in Mannequin-Threshold-Evaluation pocket book to look at the thresholds for all of the lessons.

Discover how precision goes up as the edge goes up, whereas the inverse happens with recall. To seek out the stability between the 2, we use the F1 rating the place it has seen peaks of their curve. The peaks within the F1 rating correspond to a specific threshold that may enhance the mannequin’s efficiency. Discover how a lot of the labels fall across the 0.5 mark for the edge apart from risk label, which has a threshold round 0.04.

We are able to then use this threshold for particular labels which can be underperforming with simply the default 0.5 threshold. Through the use of the optimized thresholds, the outcomes of the mannequin on the check knowledge enhance for the label risk from 0.00 to 0.24. We’re utilizing the max F1 rating on the threshold as a benchmark to find out constructive vs. destructive for that label as an alternative of a standard benchmark (a regular worth like > 0.7) for all of the labels.

Dealing with underrepresented lessons
One other strategy that’s efficient for an imbalanced dataset is oversampling. By oversampling the underrepresented class, the mannequin sees the underrepresented class extra typically and emphasizes the significance of these samples. We use the Oversampling-underrepresented.ipynb pocket book to optimize the datasets.
For this dataset, we examined how the mannequin’s efficiency on the analysis dataset modifications as we offer extra samples. We use the oversampling method to extend the incidence of underrepresented lessons to enhance the efficiency.

On this explicit case, we examined on 10, 25, 50, 100, 200, and 500 constructive examples. Discover that though we’re repeating knowledge factors, we’re inherently bettering the efficiency of the mannequin by emphasizing the significance of the underrepresented class.
Value
With Amazon Comprehend, you pay as you go primarily based on the variety of textual content characters processed. Seek advice from Amazon Comprehend Pricing for precise prices.
Clear up
Once you’re completed experimenting with this resolution, clear up your sources to delete all of the sources deployed on this instance. This helps you keep away from persevering with prices in your account.
Conclusion
On this submit, we’ve got supplied greatest practices and steering on knowledge preparation, mannequin tuning utilizing prediction possibilities and methods to deal with underrepresented knowledge lessons. You should utilize these greatest practices and methods to enhance the efficiency metrics of your Amazon Comprehend customized classification mannequin.
For extra details about Amazon Comprehend, go to Amazon Comprehend developer resources to seek out video sources and weblog posts, and consult with AWS Comprehend FAQs.
In regards to the Authors
 Sathya Balakrishnan is a Sr. Buyer Supply Architect within the Skilled Providers staff at AWS, specializing in knowledge and ML options. He works with US federal monetary purchasers. He’s keen about constructing pragmatic options to resolve clients’ enterprise issues. In his spare time, he enjoys watching films and mountaineering together with his household.
Sathya Balakrishnan is a Sr. Buyer Supply Architect within the Skilled Providers staff at AWS, specializing in knowledge and ML options. He works with US federal monetary purchasers. He’s keen about constructing pragmatic options to resolve clients’ enterprise issues. In his spare time, he enjoys watching films and mountaineering together with his household.
 Prince Mallari is an NLP Knowledge Scientist within the Skilled Providers staff at AWS, specializing in purposes of NLP for public sector clients. He’s keen about utilizing ML as a device to permit clients to be extra productive. In his spare time, he enjoys enjoying video video games and creating one together with his associates.
Prince Mallari is an NLP Knowledge Scientist within the Skilled Providers staff at AWS, specializing in purposes of NLP for public sector clients. He’s keen about utilizing ML as a device to permit clients to be extra productive. In his spare time, he enjoys enjoying video video games and creating one together with his associates.