Microsoft AI Open-Sources DeepSpeed Chat: An Finish-To-Finish RLHF Pipeline To Prepare ChatGPT-like Fashions
There isn’t a exaggeration in saying that ChatGPT-like ideas have had a revolutionary impact on the digital world. Because of this, the AI open-source group is engaged on some initiatives (akin to ChatLLaMa, Alpaca, and so forth.) that goal to make ChatGPT-style fashions extra extensively out there. These fashions are extraordinarily versatile and may execute duties akin to summarization, coding, and translation at or above human ranges of experience.
Regardless of these spectacular efforts, a publicly out there end-to-end RLHF pipeline can nonetheless not prepare a strong ChatGPT-like mannequin. Coaching effectivity is often lower than 5% of those machines’ capabilities, even when entry to such computing sources is accessible. Regardless of entry to multi-GPU clusters, current methods can’t assist the easy, quick, and cheap coaching of state-of-the-art ChatGPT fashions with billions of parameters.
These restrictions originate from the truth that the delicate RLHF coaching pipeline utilized by InstructGPT isn’t well-supported by current DL methods, that are optimized for extra typical pre-training and fine-tuning pipelines. To make ChatGPT-like fashions extra extensively out there and RLHF coaching extra simply accessible, the Microsoft crew is releasing DeepSpeed-Chat, which gives an end-to-end RLHF pipeline to coach ChatGPT-like fashions. It has the next options:
1. A Handy Atmosphere for Coaching and Inferring ChatGPT-Related Fashions: InstructGPT coaching will be executed on a pre-trained Huggingface mannequin with a single script using the DeepSpeed-RLHF system. This enables person to generate their ChatGPT-like mannequin. After the mannequin is educated, an inference API can be utilized to check out conversational interactions.
2. The DeepSpeed-RLHF Pipeline: The DeepSpeed-RLHF pipeline largely replicates the coaching pipeline from the InstructGPT paper. The crew ensured full and actual correspondence between the three steps a) Supervised Tremendous-tuning (SFT), b) Reward Mannequin Tremendous-tuning, and c) Reinforcement Studying with Human Suggestions (RLHF). As well as, in addition they present instruments for information abstraction and mixing that make it attainable to coach utilizing information from numerous sources.
3. The DeepSpeed-RLHF System: Hybrid Engine (DeepSpeed-HE) for RLHF is a robust and complicated system that mixes the coaching and inference capabilities of DeepSpeed. The Hybrid Engine can simply change between RLHF’s inference and coaching modes, making the most of DeepSpeed-Inference’s optimizations like tensor-parallelism and high-performance transformer kernels for era, in addition to RLHF’s many reminiscence optimization methods like ZeRO and LoRA. To additional optimize reminiscence administration and information switch throughout the varied levels of RLHF, DeepSpeed-HE is moreover conscious of the entire RLHF pipeline. The DeepSpeed-RLHF system achieves unprecedented effectivity at scale, permitting the AI group to rapidly, cheaply, and conveniently entry coaching on advanced RLHF fashions.
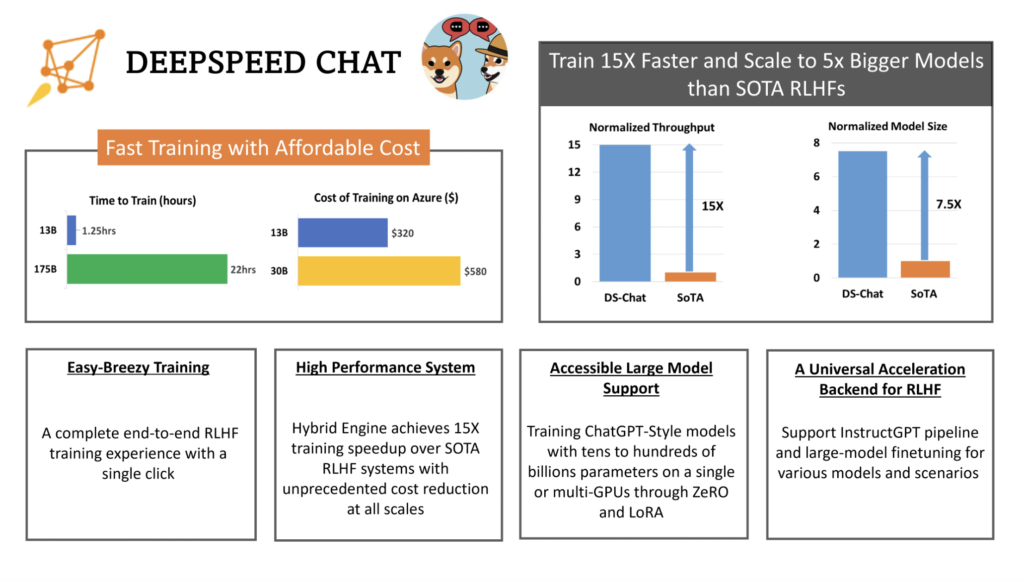
4. Effectivity and Affordability: As a result of DeepSpeed-HE is over 15 occasions faster than typical methods, RLHF coaching could also be accomplished rapidly and cheaply.
5. Glorious Scalability: DeepSpeed-HE’s sturdy scalability on multi-node multi-GPU methods permits it to accommodate fashions with lots of of billions of parameters.
6. Increasing Entry to RLHF Training: DeepSpeed-HE permits information scientists with out entry to multi-GPU methods to construct not simply toy RLHF fashions however large and highly effective ones that may be deployed in real-world settings, all with only a single GPU for coaching.
The researchers have included an entire end-to-end coaching pipeline in DeepSpeed-Chat and modeled it after InstructGPT to make the coaching course of as streamlined as attainable.
The manufacturing course of consists of three levels:
1. The pretrained language fashions are fine-tuned through supervised fine-tuning (SFT), during which human responses to varied inquiries are fastidiously chosen.
2. Subsequent, the crew performs “reward mannequin fine-tuning,” which includes coaching a special (usually smaller than the SFT) mannequin (RW) utilizing a dataset that features human-provided rankings of quite a few solutions to the identical inquiry.
3. Lastly, in RLHF coaching, the Proximal Coverage Optimization (PPO) algorithm is used to additional alter the SFT mannequin with the reward suggestions from the RW mannequin.
The AI group can now entry DeepSpeed-Chat due to its open-sourced nature. On the DeepSpeed GitHub web site, the researchers invite customers to report points, submit PRs, and take part in discussions.
Try the Code. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to hitch our 18k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
🚀 Check Out 100’s AI Tools in AI Tools Club
Tanushree Shenwai is a consulting intern at MarktechPost. She is at the moment pursuing her B.Tech from the Indian Institute of Know-how(IIT), Bhubaneswar. She is a Information Science fanatic and has a eager curiosity within the scope of software of synthetic intelligence in numerous fields. She is enthusiastic about exploring the brand new developments in applied sciences and their real-life software.