4 Approaches to construct on prime of Generative AI Foundational Fashions | by Lak Lakshmanan | Mar, 2023

What works, the professionals and cons, and instance code for every method
If a number of the terminology I take advantage of right here is unfamiliar, I encourage you to learn my earlier article on LLMs first.
There are groups which are using ChatGPT or its opponents (Anthropic, Google’s Flan T5 or PaLM, Meta’s LLaMA, Cohere, AI21Labs, and many others.) for actual reasonably for cutesy demos. Sadly, informative content material about how they’re doing so is misplaced amidst advertising and marketing hype and technical jargon. Subsequently, I see of us who’re getting began with generative AI take approaches that specialists within the area will inform you aren’t going to pan out. This text is my try at organizing this area and exhibiting you what’s working.

The bar to clear
The issue with lots of the cutesy demos and hype-filled posts about generative AI is that they hit the training dataset — they don’t actually let you know how effectively it’ll work when utilized to the chaos of actual human customers and truly novel enter. Typical software program is anticipated to work at 99%+ reliability —for instance, it was solely when speech recognition crossed this accuracy bar on phrases that the marketplace for Voice AI took off. Similar for automated captioning, translation, and many others.
I see two methods wherein groups are addressing this situation of their manufacturing techniques:
- Human customers are extra forgiving if the UX is in a scenario the place they already anticipate to right errors (this appears to be what helps GitHub Copilot) or the place it’s positioned as being interactive and useful however not prepared to make use of (ChatGPT, Bing Chat, and many others.)
- Totally automated purposes of generative AI are largely within the trusted-tester stage right now, and the jury is out on whether or not these purposes are literally in a position to clear this bar. That mentioned, the outcomes are promising and trending upwards, and it’s seemingly solely a matter of time earlier than the bar’s met.
Personally, I’ve been experimenting with GPT 3.5 Turbo and Google Flan-T5 with particular manufacturing use instances in thoughts, and studying fairly a bit about what works and what doesn’t. None of my fashions have crossed the 99% bar. I additionally haven’t but gotten entry to GPT-4 or to Google’s PaLM API on the time of writing (March 2023). I’m basing this text on my experiments, on printed analysis, and on publicly introduced initiatives.
With all makes use of of generative AI, it’s useful to firmly understand that the pretrained fashions are educated on web content material and will be biased in a number of methods. Safeguard towards these biases in your software layer.
Strategy 1: Use the API Instantly
The primary method is the best as a result of many customers encountered GPT by way of the interactive interface supplied by ChatGPT. It appears very intuitive to check out varied prompts till you get one which generates the output you need. For this reason you might have loads of LinkedIn influencers publishing ChatGPT prompts that work for sales emails or no matter.
In relation to automating this workflow, the pure methodology is to make use of the REST API endpoint of the service and instantly invoke it with the ultimate, working immediate:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.Edit.create(
mannequin="text-davinci-edit-001",
enter="It was so nice to fulfill you .... ",
instruction="Summarize the textual content under within the type of an e-mail that's 5 sentences or much less."
)
Nevertheless, this method doesn’t lend itself to operationalization. There are a number of causes:
- Brittleness. The underlying fashions preserve enhancing. Sudden modifications within the deployed fashions broke many manufacturing workloads, and other people discovered from that have. ML workloads are brittle sufficient already; including extra factors of failure within the type of prompts which are fine-tuned to particular fashions isn’t smart.
- Injection. It’s uncommon that the instruction and enter are plain strings as within the instance above. Most frequently, they embrace variables which are enter from customers. These variables should be integrated into the prompts and inputs. And as any programmer is aware of, injection by string concatenation is rife with safety issues. You place your self on the mercy of the guardrails positioned across the Generative AI API whenever you do that. As when guarding towards SQL injection, it’s higher to make use of an API that handles variable injection for you.
- A number of prompts. It’s uncommon that it is possible for you to to get a immediate to work in one-shot. Extra widespread is to ship a number of prompts to the mannequin, and get the mannequin to change its output based mostly on these prompts. These prompts themselves might have some human enter (resembling follow-up inputs) embedded within the workflow. Additionally widespread is for the prompts to offer a number of examples of the specified output (referred to as few-shot studying).
A approach to resolve all three of those issues is to make use of langchain.
Strategy 2: Use langchain
Langchain is quickly turning into the library of alternative that permits you to invoke LLMs from totally different distributors, deal with variable injection, and do few-shot coaching. Here’s an example of using langchain:
from langchain.prompts.few_shot import FewShotPromptTemplateexamples = [
{
"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
"""
},
{
"question": "When was the founder of craigslist born?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
"""
...
]
example_prompt = PromptTemplate(input_variables=["question", "answer"],
template="Query: {query}n{reply}")
immediate = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Query: {enter}",
input_variables=["input"]
)
print(immediate.format(enter="Who was the daddy of Mary Ball Washington?"))
I strongly suggest utilizing langchain vs. utilizing a vendor’s API instantly. Then, ensure that all the things you do works with at the very least two APIs or use a LLM checkpoint that won’t change beneath you. Both of those approaches will keep away from your prompts/code being brittle to modifications within the underlying LLM. (Right here, I’m utilizing API to imply a managed LLM endpoint).
Langchain right now supports APIs from Open AI, Cohere, HuggingFace Hub (and therefore Google Flan-T5), and many others. and LLMs from AI21, Anthropic, Open AI, HuggingFace Hub, and many others.
Strategy 3: Finetune the Generative AI Chain
That is the modern method in that it’s the one I see utilized by a lot of the subtle manufacturing purposes of generative AI. As simply an instance (no endorsement), finetuning is how a startup consisting of Stanford PhDs is approaching normal enterprise use instances like SQL technology and document matching.
To grasp the rationale behind this method, it helps to know that there are 4 machine studying fashions that underpin ChatGPT (or its opponents):
- A Giant Language Mannequin (LLM) is educated to foretell the subsequent phrase of textual content given the earlier phrases. It does this by studying phrase associations and patterns on an enormous corpus of paperwork. The mannequin is giant sufficient that it learns these patterns in several contexts.
- A Reinforcement Studying based mostly on Human Suggestions Mannequin (RL-HF) is educated by exhibiting people examples of generated textual content, and asking them to approve textual content that’s pleasing to learn. The rationale that is wanted is that an LLM’s output is probabilistic — it doesn’t predict a single subsequent phrase; as an alternative, it predicts a set of phrases every of which has a sure likelihood of coming subsequent. The RL-HF makes use of human suggestions to discover ways to select the continuation that may generate the textual content that appeals to people.
- Instruction Mannequin is a supervised mannequin that’s educated by exhibiting prompts (“generate a gross sales e-mail that proposes a demo to the engineering management”) and coaching the mannequin on examples of gross sales emails.
- Context Mannequin is educated to hold on a dialog with the consumer, permitting them to craft the output by way of successive prompts.
As well as, there are guardrails (filters on each the enter and output). The mannequin declines to reply sure varieties of queries, and retracts sure solutions. In observe, these are each machine studying fashions which are consistently up to date.

There are open-source generative AI fashions (Meta’s LLaMA, Google’s Flan-T5) which let you choose up at any of the above steps (e.g. use steps 1–2 from the launched checkpoint, practice 3 by yourself information, don’t do 4). Word that LLaMA doesn’t allow business use, and Flan-T5 is a 12 months previous (so you’re compromising on high quality). To be taught the place to interrupt off, it’s useful to grasp the price/profit of every stage:
- In case your software makes use of very totally different jargon and phrases, it might be useful to construct a LLM from scratch by yourself information (i.e., begin at step 1). The issue is that you could be not have sufficient information and even when you’ve got sufficient information, the coaching goes to be costly (on the order of three–5 million {dollars} per coaching run). This appears to be what Salesforce has executed with the generative AI they use for developers.
- The RL-HF mannequin is educated to enchantment to a gaggle of testers who is probably not subject-matter specialists, or consultant of your individual customers. In case your software requires subject material experience, you might be higher off beginning with a LLM and branching off from step 2. The dataset you want for that is a lot smaller — Stiennon et al 2020 used 125k paperwork and offered a pair of outputs for every enter doc in every iteration (see diagram). So, you want human labelers on standby to fee about 1 million outputs. Assuming {that a} labeler takes 10 min to fee every pair of paperwork, the price is that of 250 human-months of labor per coaching run. I’d estimate $250k to $2m relying on location and skillset.
- ChatGPT is educated to reply to 1000’s of various prompts. Your software, alternatively, in all probability requires just one or two particular ones. It may be handy to coach a mannequin resembling Google Flan-T5 in your particular instruction and enter. Such a mannequin will be a lot smaller (and due to this fact cheaper to deploy). This benefit in serving prices explains why step 3 is the commonest level of branching off. It’s doable to fine-tune Google Flan-T5 to your particular job with about 10k paperwork utilizing HuggingFace and/or Keras. You’d do that in your traditional ML framework resembling Databricks, Sagemaker, or Vertex AI and use the identical providers to deploy the educated mannequin. As a result of Flan-T5 is a Google mannequin, GCP makes coaching and deployment very easy by offering pre-built containers in Vertex AI. The associated fee could be maybe $50 or so.
- Theoretically, it’s doable to coach a distinct approach to preserve conversational context. Nevertheless, I haven’t seen this in observe. What most individuals do as an alternative is to make use of a conversational agent framework like Dialogflow that already has a LLM constructed into it, and design a customized chatbot for his or her software. The infra prices are negligible and also you don’t want any AI experience, simply area data.
It’s doable to interrupt off at any of those phases. Limiting my examples to publicly printed work in medication:
- This Nature article builds a customized 8.9-billion parameter LLM from 90 billion phrases extracted from medical data (i.e., they begin from step 1). For comparability, Flan T5 is 540 billion parameters and the “small/environment friendly” PaLM is 62 billion parameters. Clearly, price is a constraint in going a lot larger in your customized language mannequin.
- This MIT CSAIL study forces the mannequin to carefully hew to current textual content and likewise doing instruction fine-tuning (i.e., they’re ranging from step 2).
- Deep Mind’s MedPaLM begins from an instruction-tuned variation of PaLM referred to as Flan-PaLM (i.e. it begins after step 3). They report that 93% of healthcare professionals rated the AI as being on par with human solutions.
My recommendation is to decide on the place to interrupt off based mostly on how totally different your software area is from the generic web textual content on which the foundational fashions are educated. Which mannequin do you have to fine-tune? At present, Google Flan T5 is essentially the most subtle fine-tuneable mannequin obtainable and open for business use. For non-commercial makes use of, Meta’s LLaMA is essentially the most subtle mannequin obtainable.
A phrase of warning although: whenever you faucet into the chain utilizing open-source fashions, the guardrail filters gained’t exist, so you’ll have to put in toxicity safeguards. One choice is to make use of the detoxify library. Be sure that to include toxicity filtering round any API endpoint in manufacturing — in any other case, you’ll end up having to take it back down. API gateways is usually a handy manner to make sure that you’re doing this for all of your ML mannequin endpoints.
Strategy 4: Simplify the issue
There are sensible approaches to reframe the issue you’re fixing in resembling manner that you need to use a Generative AI mannequin (as in Strategy 3) however keep away from issues with hallucination, and many others.
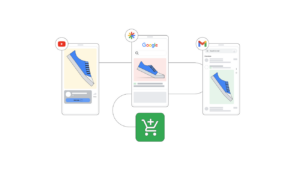
For instance, suppose you wish to do question-answering. You can begin with a robust LLM after which wrestle to “tame” the wild beast to have it not hallucinate. A a lot easier method is to reframe the issue. Change the mannequin from one which predicts the output textual content to a mannequin that has three outputs: the URL of a doc, the beginning place inside that doc, and the size of textual content. That’s what Google Search is doing right here:

At worst, the mannequin will present you irrelevant textual content. What it won’t do is to hallucinate since you don’t permit it to truly predict textual content.
A Keras sample that follows this method tokenizes the inputs and context (the doc that you’re discovering the reply inside):
from transformers import AutoTokenizermodel_checkpoint = "google/flan-t5-small"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
...
examples["question"] = [q.lstrip() for q in examples["question"]]
examples["context"] = [c.lstrip() for c in examples["context"]]
tokenized_examples = tokenizer(
examples["question"],
examples["context"],
...
)
...
after which passes the tokens right into a Keras regression mannequin whose first layer is the Transformer mannequin that takes in these tokens and that outputs the place of the reply throughout the “context” textual content:
from transformers import TFAutoModelForQuestionAnswering
import tensorflow as tf
from tensorflow import kerasmannequin = TFAutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
optimizer = keras.optimizers.Adam(learning_rate=5e-5)
mannequin.compile(optimizer=optimizer)
mannequin.match(train_set, validation_data=validation_set, epochs=1)
Throughout inference, you get the expected areas:
inputs = tokenizer([context], [question], return_tensors="np")
outputs = mannequin(inputs)
start_position = tf.argmax(outputs.start_logits, axis=1)
end_position = tf.argmax(outputs.end_logits, axis=1)
You’ll notice that the pattern doesn’t predict the URL — the context is assumed to be the results of a typical search question (resembling returned by an identical engine or vector database), and the pattern mannequin solely does extraction. Nevertheless, you’ll be able to construct the search additionally into the mannequin by having a separate layer in Keras.
Abstract
There are 4 approaches that I see getting used to construct manufacturing purposes on prime of generative AI foundational fashions:
- Use the REST API of an all-in mannequin resembling GPT-4 for one-shot prompts.
- Use langchain to summary away the LLM, enter injection, multi-turn conversations, and few-shot studying.
- Finetune in your customized information by tapping into the set of fashions that comprise an end-to-end generative AI mannequin.
- Reframe the issue right into a type that avoids the risks of generative AI (bias, toxicity, hallucination).
Strategy #3 is what I see mostly utilized by subtle groups.