Information Cleansing in SQL: How To Put together Messy Information for Evaluation


Picture generated with Segmind SSD-1B mannequin
Excited to begin analyzing information utilizing SQL? Nicely, you’ll have to attend only a bit. However why?
Information in database tables can usually be messy. Your information could comprise lacking values, duplicate data, outliers, inconsistent information entries, and extra. So cleansing the info earlier than you may analyze it utilizing SQL is tremendous vital.
While you’re studying SQL, you may spin up database tables, alter them, replace and delete data as you want. However in observe, that is nearly by no means the case. It’s possible you’ll not have permission to change tables, replace and delete data. However you’ll have learn entry to the database and can have the ability to run a bunch of SELECT queries.
On this tutorial, we’ll spin up a database desk, populate it with data, and see how we will clear the info with SQL. Let’s begin coding!
For this tutorial, let’s create an staff desk like so:
-- Create the workers desk
CREATE TABLE staff (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(50),
wage DECIMAL(10, 2),
hire_date VARCHAR(20),
division VARCHAR(50)
);
Subsequent, let’s insert some fictional pattern data into the desk:
-- Insert 20 pattern data
INSERT INTO staff (employee_id, employee_name, wage, hire_date, division) VALUES
(1, 'Amy West', 60000.00, '2021-01-15', 'HR'),
(2, 'Ivy Lee', 75000.50, '2020-05-22', 'Gross sales'),
(3, 'joe smith', 80000.75, '2019-08-10', 'Advertising'),
(4, 'John White', 90000.00, '2020-11-05', 'Finance'),
(5, 'Jane Hill', 55000.25, '2022-02-28', 'IT'),
(6, 'Dave West', 72000.00, '2020-03-12', 'Advertising'),
(7, 'Fanny Lee', 85000.50, '2018-06-25', 'Gross sales'),
(8, 'Amy Smith', 95000.25, '2019-11-30', 'Finance'),
(9, 'Ivy Hill', 62000.75, '2021-07-18', 'IT'),
(10, 'Joe White', 78000.00, '2022-04-05', 'Advertising'),
(11, 'John Lee', 68000.50, '2018-12-10', 'HR'),
(12, 'Jane West', 89000.25, '2017-09-15', 'Gross sales'),
(13, 'Dave Smith', 60000.75, '2022-01-08', NULL),
(14, 'Fanny White', 72000.00, '2019-04-22', 'IT'),
(15, 'Amy Hill', 84000.50, '2020-08-17', 'Advertising'),
(16, 'Ivy West', 92000.25, '2021-02-03', 'Finance'),
(17, 'Joe Lee', 58000.75, '2018-05-28', 'IT'),
(18, 'John Smith', 77000.00, '2019-10-10', 'HR'),
(19, 'Jane Hill', 81000.50, '2022-03-15', 'Gross sales'),
(20, 'Dave White', 70000.25, '2017-12-20', 'Advertising');
When you can inform, I’ve used a small set of first and final names to pattern from and assemble the title area for the data. You could be extra inventive with the data, although.
Word: All of the queries on this tutorial are for MySQL. However you’re free to make use of the RDBMS of your selection.
Lacking values in information data are at all times an issue. So you must deal with them accordingly.
A naive strategy is to drop all of the data that comprise lacking values for a number of fields. Nevertheless, you shouldn’t do that except you’re certain there is no such thing as a different higher method of dealing with lacking values.
Within the staff desk, we see that there’s a NULL worth within the ‘division’ column (see row of employee_id 13) indicating that the sphere is lacking:
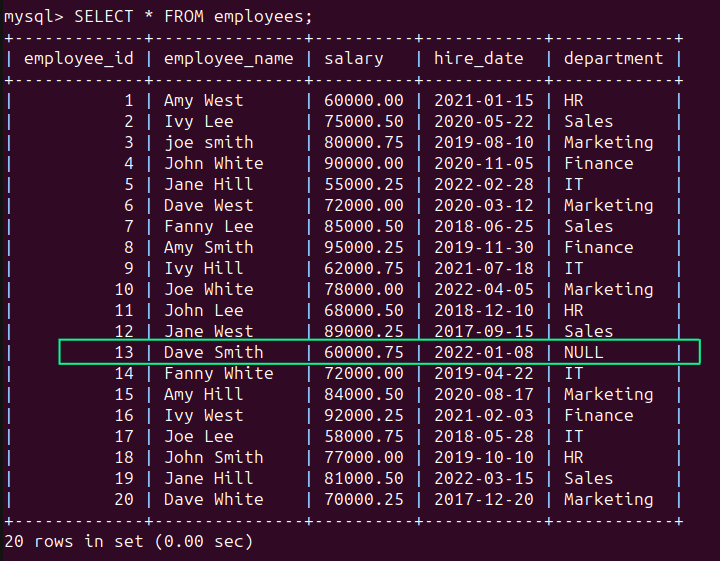
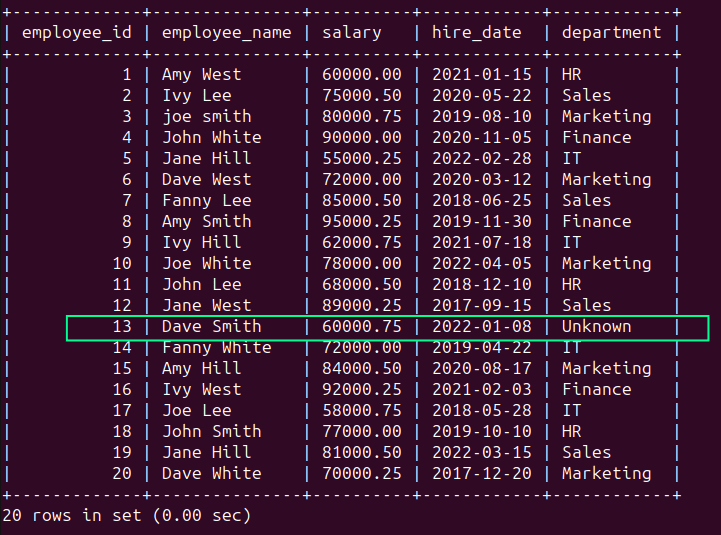
You should use the COALESCE() function to make use of the ‘Unknown’ string for the NULL worth:
SELECT
employee_id,
employee_name,
wage,
hire_date,
COALESCE(division, 'Unknown') AS division
FROM staff;
Operating the above question ought to provide the following outcome:
Duplicate data in a database desk can distort the outcomes of research. We’ve chosen the employee_id as the first key in our database desk. So we’ll not have any repeating worker data within the employee_data desk.
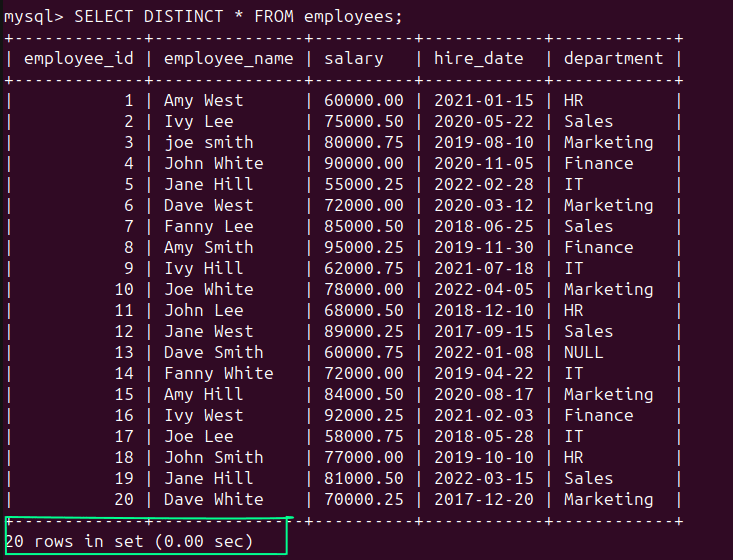
You may nonetheless the SELECT DISTINCT assertion:
SELECT DISTINCT * FROM staff;
As anticipated, the outcome set incorporates all of the 20 data:
When you discover, the ‘hire_date’ column is presently VARCHAR and never a date sort. To make it simpler when working with dates, it’s useful to make use of the STR_TO_DATE() operate like so:
SELECT
employee_id,
employee_name,
wage,
STR_TO_DATE(hire_date, '%Y-%m-%d') AS hire_date,
division
FROM staff;
Right here, we’ve solely chosen the ‘hire_date’ column amongst others and haven’t carried out any operations on the date values. So the question output needs to be the identical as that of the earlier question.
However if you wish to carry out operations reminiscent of including an offset date to the values, this operate could be useful.
Outliers in a number of numeric fields can skew evaluation. So we must always examine for and take away outliers in order to filter out the info that isn’t related.
However deciding which values represent outliers requires area information and information utilizing information of each the area and historic information.
In our instance, as an instance we know that the ‘wage’ column has an higher restrict of 100000. So any entry within the ‘wage’ column could be at most 100000. And entries larger than this worth are outliers.
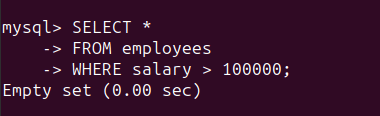
We are able to examine for such data by working the next question:
SELECT *
FROM staff
WHERE wage > 100000;
As seen, all entries within the ‘wage’ column are legitimate. So the outcome set is empty:
Inconsistent information entries and formatting are fairly widespread particularly in date and string columns.
Within the staff desk, we see that the document comparable to worker ‘bob johnson’ will not be within the title case.
However for consistency let’s choose all of the names formatted within the title case. You need to use the CONCAT() operate together with UPPER() and SUBSTRING() like so:
SELECT
employee_id,
CONCAT(
UPPER(SUBSTRING(employee_name, 1, 1)), -- Capitalize the primary letter of the primary title
LOWER(SUBSTRING(employee_name, 2, LOCATE(' ', employee_name) - 2)), -- Make the remainder of the primary title lowercase
' ',
UPPER(SUBSTRING(employee_name, LOCATE(' ', employee_name) + 1, 1)), -- Capitalize the primary letter of the final title
LOWER(SUBSTRING(employee_name, LOCATE(' ', employee_name) + 2)) -- Make the remainder of the final title lowercase
) AS employee_name_title_case,
wage,
hire_date,
division
FROM staff;
When speaking about outliers, we talked about how we’d just like the higher restrict on the ‘wage’ column to be 100000 and thought of any wage entry above 100000 to be an outlier.
Nevertheless it’s additionally true that you do not need any destructive values within the ‘wage’ column. So you may run the next question to validate that each one worker data comprise values between 0 and 100000:
SELECT
employee_id,
employee_name,
wage,
hire_date,
division
FROM staff
WHERE wage < 0 OR wage > 100000;
As seen, the outcome set is empty:
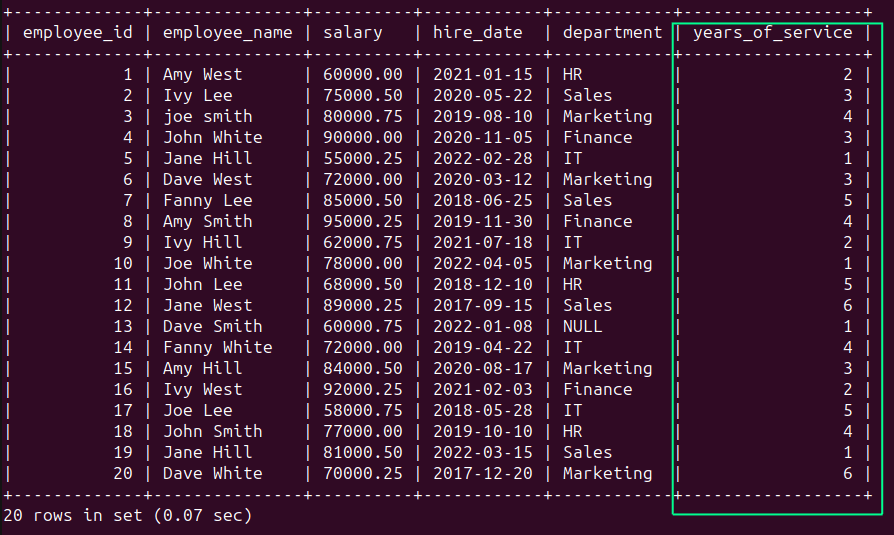
Deriving new columns will not be primarily a knowledge cleansing step. Nevertheless, in observe, chances are you’ll want to make use of present columns to derive new columns which are extra useful in evaluation.
For instance, the staff desk incorporates a ‘hire_date’ column. A extra useful area is, maybe, a ‘years_of_service’ column that signifies how lengthy an worker has been with the corporate.
The next question finds the distinction between the present 12 months and the 12 months worth in ‘hire_date’ to compute the ‘years_of_service’:
SELECT
employee_id,
employee_name,
wage,
hire_date,
division,
YEAR(CURDATE()) - YEAR(hire_date) AS years_of_service
FROM staff;
You must see the next output:
As with different queries we’ve run, this doesn’t modify the unique desk. So as to add new columns to the unique desk, you must have permissions to ALTER the database desk.
I hope you perceive how related information cleansing duties can enhance information high quality and facilitate extra related evaluation. You’ve discovered tips on how to examine for lacking values, duplicate data, inconsistent formatting, outliers, and extra.
Attempt spinning up your individual relational database desk and run some queries to carry out widespread information cleansing duties. Subsequent, find out about SQL for data visualization.
Bala Priya C is a developer and technical author from India. She likes working on the intersection of math, programming, information science, and content material creation. Her areas of curiosity and experience embody DevOps, information science, and pure language processing. She enjoys studying, writing, coding, and occasional! At the moment, she’s engaged on studying and sharing her information with the developer group by authoring tutorials, how-to guides, opinion items, and extra.





